溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
??Xtrabackup是由percona開源的免費數據庫熱備份軟件,它能對InnoDB數據庫和XtraDB存儲引擎數據庫進行非阻塞的備份,其具備以下一些優點:
??1)備份速度快,物理備份可靠
??2)備份過程不會打斷正在執行的事務
??3)能夠基于壓縮等功能節約磁盤空間和流量
??4)自動備份校驗
??5)還原速度快
??6)可以流傳將備份傳輸到另外一臺機器上
??7)在不增加服務器負載的情況備份數據
??Xtrabackup熱備和恢復原理如下圖所示:
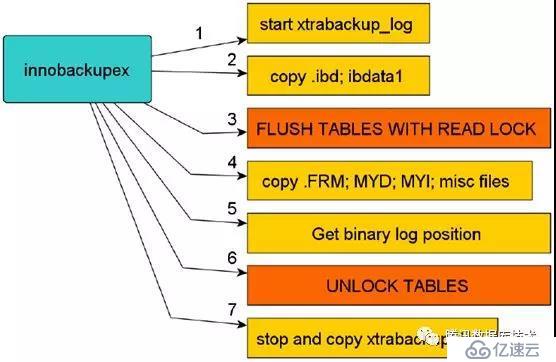 ??
??
備份開始時首先會開啟一個后臺檢測進程,實時檢測mysql redo的變化,一旦發現redo中有新的日志寫入,立刻將日志記入后臺日志文件xtrabackup_log中。之后復制innodb的數據文件和系統表空間文件ibdata1,待復制結束后,執行flush tables with read lock操作,復制.frm,MYI,MYD,等文件,最后會發出unlock tables,停止xtrabackup_log。
??恢復階段則啟動xtrabackup內嵌的innodb實例,回放xtrabackup日志xtrabackup_log,將提交的事務信息變更應用到innodb數據/表空間,同時回滾未提交的事務(這一過程類似innodb的實例恢復)。如圖所示:
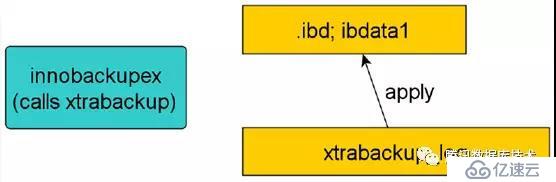
??Xtrabackup的增量備份過程和全量類似,只針對增量備份過程中的”增量”進行處理,主要是相對innodb而言,對myisam和其他存儲引擎而言,它仍然是全量備份。
??從備份恢復的流程上看,備份過程主要受拷貝文件和日志生成速度影響,即和磁盤IO、網絡以及系統壓力有關;恢復過程則主要和IO、并發控制相關,本文下面將主要討論Xtrabackup恢復階段的優化。
??Xtrabackup的恢復過程實則是調用內嵌innodb的恢復邏輯來實現的(修改了一些參數的默認值,如恢復時buffer pool緩存頁面數目),而innodb的恢復一直以來都不是那么的高效,社區也有很多innodb崩潰恢復流程的優化方案。
??在實際生產環境中,動輒上T的數據在使用Xtrabackup進行熱備時通常要產生幾十G甚至更大的日志文件,受限于備份恢復虛擬機的配置,這樣的備份在恢復時往往需要數個小時,平均恢復速度僅為1-4M/s(熱數據分布相關),這樣的速度給現網實例的運維造成了很大的麻煩。
??通常情況下,InnoDB的恢復過程中的內存分配類型為MEM_HEAP_BUFFER,即在buffer pool中開辟一段內存用于存放日志記錄,當需要恢復的日志文件很大時,可能存在內存不足的情況,根據內存是否充足把日志的處理分為兩種方式:
??1、開辟的內存足夠所有保存日志記錄??

??在內存足夠的情況下,日志的解析和回放是串行的,而日志的回放是并行的,可能參與的線程包括主線程以及各個IO線程,極端情況下可能會有log_checkpoint線程以及其他工作線程。
??2、開辟的內存不足以保存所有的日志記錄??
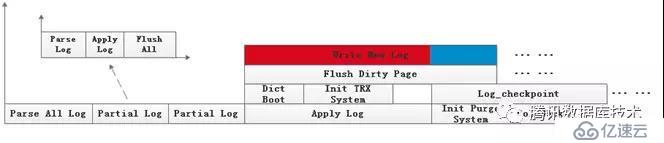
??在內存不足的情況下,日志解析需要進行兩輪,第一輪解析到某個lsn之后發現內存不足,后續的解析將放棄保存log record到hash table,直到解析完所有日志,最后清空這一輪生成的hash table,第一輪留給下一輪解析的遺產是所有需要打開tablespace的信息和所有DDL相關信息,用于恢復開始時的tablespace構建;第二輪在發現內存不足時,把已經解析的日志全部應用到頁面上,此時ibuf的merge是被禁止的(不能產生新的日志),這就需要在應用完日志之后將所有臟頁刷盤,并失效buffer pool中的所有頁面,最后清空hash table,進行后續日志的解析和回放,剩余邏輯和1相同。
??從實際情況看,整體日志恢復速度較慢,平均1-4M每秒,對于數百兆的崩潰恢復以及更大的備份日志恢復來說,這樣的速度遠遠不夠。
??從以上分析來看,日志解析回放的恢復過程存在以下幾個可以優化的地方:
??1、日志的解析
??2、日志內存不足時的page flush
??3、日志解析和回放的并行
??log record中沒有日志長度信息,由于通常情況下日志是格式化的,解析日志文件推進的過程中需要使用簡單的元數據結構體傳入到處理函數中,從而計算單條日志的邊界,恢復的過程就是從last checkpoint lsn逐條推進到沒有合法日志為止,這種元數據結構實則為dict_index_t和dict_table_t結構,日志解析和回放過程中都需要使用這種數據結構,InnoDB的對它們的處理比較粗放,每條log record解析和回放都需要malloc和free以上一對結構。
??在MySQL社區這兩個問題已經被提出,同時也提出了解決方案,如:
??1、對應(Bug#82937),解決方案為在log record header中增加長度信息,如下圖所示:?
?
??如此,log record的邊界依靠length即可求到,省去大量元數據結構的malloc和free,以及解析日志格式的函數調用,這一優化可提升解析性能60%。
??2、對應(Bug#82176),log record在回放時確實需要元數據結構,但需要的信息遠遠少于Runtime,根據分析,相同列數的表可以共享此數據結構,在使用前重新初始化一些屬性即可,這樣就可以通過引入元數據cache來減少不必要的malloc和free。產品實測中,cache對單線程解析有30%+的提升,同樣社區也有阿里團隊類似的優化貢獻。
??但從解析角度出發,優化前單核速度可以達到60-80M/s,優化后可以達到120-160M/s,絕對速度已經相當可觀。
??以innodb5.6的恢復為基準,通常情況下日志文件要被掃描三遍,即解析三次,即便有120M/s的速度,重復的掃描也浪費了一部分的時間,如果對日志解析速度有更高的要求,為了追求更高的解析速度,可以引入多線程并行解析,而能否并行解析的關鍵在于日志如何有效的切分成若干個完整的分片。
??并行解析的可行性建立在能否在以LOG BLOCK組織的連續的日志文件中劃分出完整的日志片段這個問題上。InnoDB日志解析的預讀緩沖區為RECV_SCAN_SIZE(64K),其實也是分次讀取和解析的,但其能通過邊界計算處理跨越64K邊界的日志記錄,跨越邊界的整個日志記錄將在下一個64K中全部讀取,相當于下一次讀取的日志塊和上一次是有重疊的。
??由此,我們按照固定大小(LOG BLOCK的整數倍,如10M)切分日志塊,第一個分片的第一個BLOCK的起始位置通過checkpoint lsn定位,其余分片的第一個BLOCK起始位置通過LOG_BLOCK_FIRST_REC_GROUP來確定,如果某個分片內日志不能完整結束,則向下一個分片移動,直到解析出完整的日志為止,分片的移動可能導致兩個分片解析到同一個log record,由于日志回放是冪等的,所以重復的日志記錄只要按照lsn有序,多次回放不影響正確性。日志文件的分片窗口如下圖所示:??
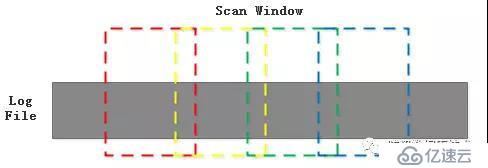
??應用并行解析后的恢復流程將減少大量的解析時間,如下圖所示:??
??以上分析中,我們發現當分配的buffer pool不足以放下所有日志記錄時(大實例絕大多數會發生),日志就會被解析多次,然后分批的進行回放,每次回放完成的頁面由于不能執行ibuf merge,只能觸發page cleaner全部刷到磁盤,而且當熱頁面比較分散時,每一輪的回放涉及的頁面遠遠超過Xtrabackup默認的512個頁面的buffer,這就導致產生了大量single page的淘汰,每個頁面都需要調用一次fil_flush(fsync),形成嚴重的性能瓶頸,大實例尤為嚴重。
??結合現網Xtrabackup進行熱備的方式,發現目前整個備份恢復過程其實是整體完成的(原子的),一次備份(全量或增量)只有完整的恢復完才算成功,如此就可以在page flush上進行比較巧妙的優化,即將恢復階段所有的page flush改為只寫文件緩存,而不調用fli_flush,fsync操作交給操作系統批量調度,換句話說就是將同步的刷臟變成了異步,整個恢復完成時fil_close將會把所有未落盤的臟頁全都刷下去,頁面淘汰不再成為瓶頸,每一輪的回放速度將大大提升。
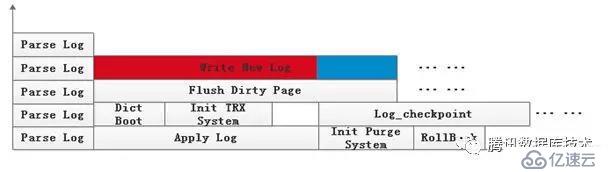
??如下圖所示,日志的解析和回放并行在InnoDB中的大致方案,不同與串行方式,解析過程不再獨立存在,而是與回放線程(寫新日志)、IO線程以及checkpoint線程并發,這樣的并發受限于InnoDB的一些現有機制,如內存管理、刷臟機制、tablespace以及checkpoint機制等,下面將逐一展開分析:??
??1、內存管理
??InnoDB恢復階段所需內存申請類型為MEM_HEAP_BUFFER,從buffer pool中劃分一塊內存,大小有限,因此存在先前提到的兩階段解析。由于MEM_HEAP_BUFFER類型的特點,多次申請,統一釋放,如果和回放并行,當內存達到上限時,解析不得不停止下來,等待所有日志apply結束,回收內存之后再繼續進行解析。
可以將日志解析和回放理解成生產者和消費者,日志回放為消費者,回放過后的日志記錄即可回收,將內存類型設置為MEM_HEAP_DYNAMIC,每條日志記錄解析時malloc自己的內存,回放結束后將其釋放,因為回放是并發的,總體來說內存是大體穩定的。
??2、新日志生成
??InnoDB通過恢復階段依然通過log_sys管理日志,ibuf merge產生的日志需要寫在同一個日志文件中,但通常情況下,解析線程不結束解析過程是無法得到系統持久化lsn的,因此新日志的起始lsn以及寫入日志文件的offset無法確定,從而解析階段產生新日志通常是不可能實現的。
??如果在恢復初期不能得到持久化lsn,將會對生成新日志形成障礙。對于InnoDB的恢復,也有例外存在,如InnoDB如果需要兩階段解析的話,第一階段結束后系統持久化lsn其實已經可以確定;對于Xtrabackup來說,拷貝得到的日志在拷貝結束時是可以確定結束lsn(即最終持久化的lsn)。因此,對于Xtrabackup的恢復而言,不存在生成新日志的障礙。
??最后,InnoDB恢復階段log_sys中某些屬性也在恢復邏輯中被使用,如buffer等,和寫日志邏輯是沖突的,需要將log_sys中有沖突的屬性轉移到recv_sys中實現。
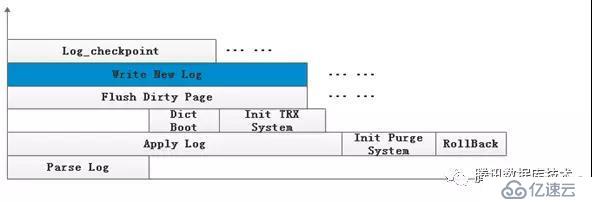
??3、刷臟機制和增量checkpoint
??InnoDB使用flush list管理臟頁面,臟頁面在flush list中以首次變臟時的lsn為順序排序,每當臟頁被刷盤之后,就從flush list中將其移除,增量checkpoint機制定時掃描flush list中最小的lsn,以此為checkpoint lsn進行打點,選取打點的lsn必須滿足“在flush list中,小于這個lsn的所有修改涉及的頁面都在這個lsn所屬頁面之前”的原則,這個原則直接依賴于頁面按照首次變臟lsn有序。
??在InnoDB的恢復中,頁面在flush list中的順序不是在解析日志的時候維護的,而是在具體某個頁面回放完日志之后才確定的(頁面回放完日志之后插入到flush list),由于多線程回放,主線程按照hash table的桶順序回放,或者按需回放(讀取某個頁面),因此flush list中臟頁的順序并不完全按照首次修改有序,直到所有的頁面都回放完日志,最終的flush list的狀態才是完全正確的狀態,因此,在InnoDB的恢復中,log_checkpoint才是在所有頁面全部回放完日志記錄之后進行的。
??解析和回放并行勢必會產生新的日志,而日志緩沖區和日志文件大小是有限的,如果新日志的產生沒有足夠的空間,此時還不能做log checkpoint,那么恢復過程可能會卡死;解析和回放并行產生的臟頁,在IO允許的情況下,及時持久化并推進checkpoint,避免恢復過程中異常退出之后再次重新恢復。
??能否在解析日志時進行checkpoint,根本問題是如何時刻維護flush list的順序。頁面的修改順序就是其在日志中出現的順序,其順序和首次修改完全等價,因此可以在日志解析時peek頁面是否在buffer pool中,如果不在則將其load上來,此時不必實際讀取頁面,只需要在flush list中占一個位置即可,如果從flush list中刷臟頁時頁面還沒有load上來,那么就必須發生一次同步IO。通過這種方式,可以在解析日志時一直維護flush list的順序,由此解決恢復階段checkpoint的限制。
??4、Tablespace
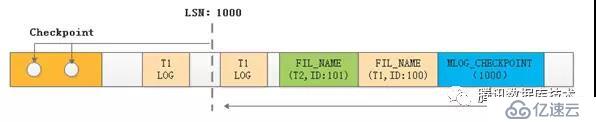
??InnoDB恢復時的fil_space信息從日志記錄中類型為MLOG_FILE_NAME的日志獲得,因為恢復階段SYS_TABLESPACE系統表中的記錄可能是不完整的,MLOG_FILE_NAME類型的記錄在每次tablespace首次變臟或者checkpoint的時候寫入日志,為的是在恢復時能夠打開所有需要的tablespace(MySQL 5.7.5引入的優化,先前的版本是打開所有ibd文件來load tablespace)。
??如下圖所示,當最后一次checkpoint發生在lsn為1000時,T1表在checkpoint之后仍然有修改,而T1表的MLOG_FILE_NAME日志在寫MLOG_CHECKPOINT之前,在T1的最后一條日志之后。如果解析和回放并發,當T1的最后一條日志需要被重放時,T1的FIL_NAME日志沒有解析到,它的tablespace就不會load,此時重放以及后續的IO可能出現問題;系統表有可能還沒有恢復,所以此時通過dict_load的方式也是不可行的。??
??此外,如果某個表在checkpoint之后存在修改,并且在后續的操作中被drop,如下圖所示,那么恢復過程可以忽略這個表的日志,因為不需要也不可能恢復(物理文件已經刪除,沒有tablespace),這個過程是在recv_init_crash_recovery_spaces()中完成的,它要求先將日志全部解析,生成完整的FIL_NAME表,然后統籌那些表不需要恢復。?
?
??如果解析和回放并行,Tablespace的Load可以在解析日志前通過掃描所有ibd文件,load所有已存在的tablespace方式完成;或者將當前系統表中已存在的表通過dict_load的方式全部加載,即使此時的tablespace是不完整的。此外,對于刪掉或者truncate掉的表,如果在回放日志時fil_space不存在,或者page no超過tablespace的size,則不回放相關日志記錄。
??從以上可行性分析來看,解析和回放在InnoDB中從理論上是可以實現并行的,但需要一些關鍵機制的適配,涉及內容比較多,復雜度高,結合性能收益,我們將對實際實施的優化進行取舍。
??從收益來看,假設日志解析總時間為Xa,回放總時間為(10-X)a,在引入dict_index cache以及并行解析日志之后,整個解析和回放的時間會提升10/(10-(1-0.7/N)*X))倍,其中0.7為dict_index cache單線程提升的效果,N為并發解析線程數,由公式可以看到,當解析時間占比比較大時,增加并發解析線程數,就能大大提升恢復效率;如果回放時間占比大時,即使將解析和回放并行,收益也是很有限的。
??綜上,鑒于解析和回放并行的高復雜度和有限的收益以及解析和回放代價占比,目前恢復的優化方案主要針對單線程的解析優化和頁面的刷盤優化,具體實施方案如下:
??1、dict_index cache
??對每一個獨立的解析線程,增加線程級cache(避免不必要的鎖開銷),cache的搜索key為列數,兩個列數相同的表共享一對dict_index和dict_table結構,使用前需要重新初始化結構上的一些字段。
??對于主線程、若干個IO線程以及可能執行回放任務的checkpoint線程,也增加線程級cache,用于回放階段的優化
??2、控制多次解析
??首先將innodb 5.6中最多掃描日志三次的機制改為最多掃描兩次,其實是消除mlog_checkpoint的作用;提供配置參數,配置在熱備產生大量日志的情況下,跳過第一輪log record加入log hash table的操作,使得第一輪掃描變為快速構造tablespace,對高負載的小實例熱備有一些作用,參考生成日志文件大小和buffer pool的大小進行配置。
??3、延遲刷臟
??提供配置參數,配置在恢復階段臟頁刷盤方式,實施異步刷臟。
??開發機:Dev-VD2??
??數據庫參數
??port=3306
??max_connections=100
??innodb_buffer_pool_size=4G
??innodb_buffer_pool_instances=2
??innodb_file_per_table=1
??innodb_flush_log_at_trx_commit=0
??innodb_log_buffer_size=512M
??innodb_log_file_size=1G
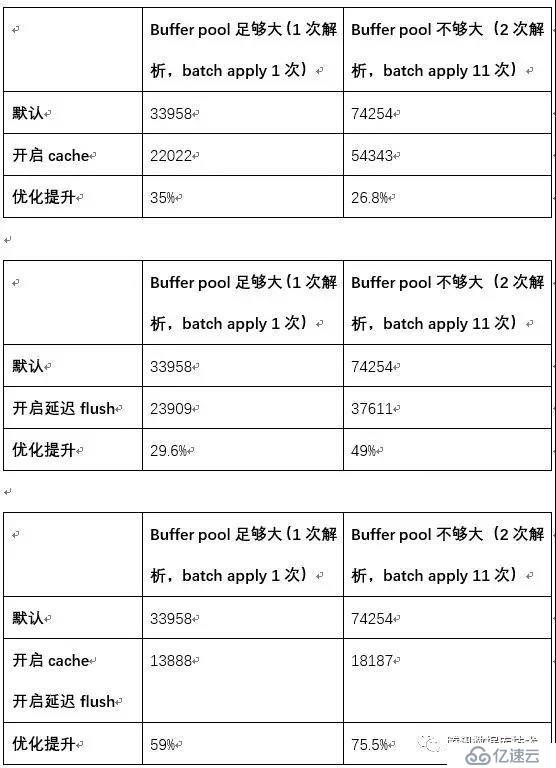
??目前,所有5.6版本(之前)日志解析都需要默認進行三次,結合Xtrabackup自身的特點,兩次完全足夠,本章節就不再對比解析三次的測試。(單位ms)
? ??
??
以上測試均是小實例、虛擬機上的測試對比,這些優化在不同場景下提升幅度各有不同,大部分在30%-75%之間,受系統負載,IO,熱數據分布等因素影響;現網中一個2T的實例,某次熱備產生20G的日志,優化后恢復時間從原先的4小時降低到10分鐘,恢復速度大幅提升了20余倍。
??針對不同場景的實例,可以進一步的深度優化,如前所述的并行解析、日志格式引入長度信息(需考慮兼容性問題)、結合Xtrabackup自身tablespace處理特點優化tablespace的構建等;InnoDB恢復時日志相關的內存管理比較粗放,也有優化的空間;此外,恢復階段的鎖如recv_sys的mutex、fli_system的mutex、flush list的mutex以及buffer pool的mutex都有一定的優化空間。
??不管采用何種方式優化,當實例和日志很大時,解析優化所帶來的效果將會越來越小,其在整個恢復過程中已不再成為瓶頸,瓶頸一般都會轉移到IO上來,因此后續的優化需要結合特定場景具體分析,有的放矢地進行針對性的優化。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





