溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了如何在PHP中利用正則表達式對中文進行提取,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
1. GBK (GB2312/GB18030)
代碼如下:
\x00-\xff GBK雙字節編碼范圍 \x20-\x7f ASCII \xa1-\xff 中文 gb2312 \x80-\xff 中文 gbk
2. UTF-8 (Unicode)
\u4e00-\u9fa5 (中文) \x3130-\x318F (韓文 \xAC00-\xD7A3 (韓文) \u0800-\u4e00 (日文)
在Notepad++下面,我們可以首先進行測試我們的正則書寫的錯誤與否。第一個表達式我是使用[\u4e00-\u9fa5]+來檢驗的,+號表示不止一個
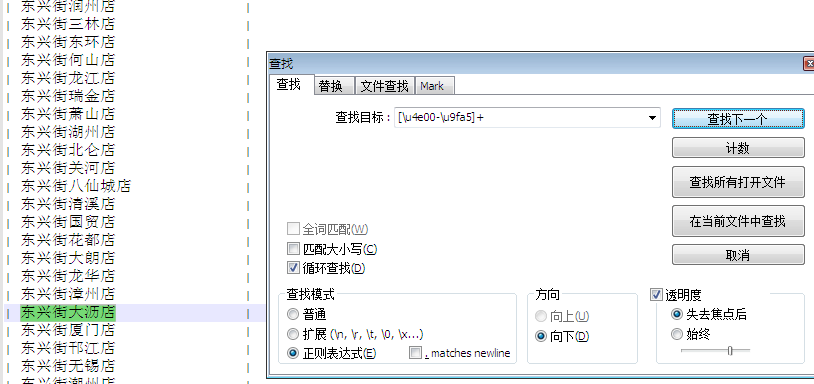
匹配符。結果與預期相同,那么,是否在腳本中就可以使用這個正則了呢?
我們測試一下,我們使用preg_match_all(‘/[\u4e00-\u9fa5]+/', $subject,$matches)調用,然后你卻看到了這么一個結果:Compilation failed: PCRE does not support \L, \l, \N{name}, \U, or \u at offset 2。。。。是不是很頭大??這究竟是什么原因?
查閱了很多資料后發現,u (PCRE_UTF8),就是上面的PCRE,這是是一個Perl庫,包括 perl 兼容的正規表達式庫。此修正符啟用了一個 PCRE 中與 Perl 不兼容的額外功能。模式字符串被當成 UTF-8。本修正符在 Unix 下自 PHP 4.1.0 起可用,在 win32 下自 PHP 4.2.3 起可用。而php正則表達式對于十六進制數據的表達方式上也有所不同,在php中,是用\x表示十六進制數據的。下面我們就將代碼優化一下,檢測函數變為:
class storeDataAdapter extends Store{
private $dsData;
/**
* 數據轉換函數,調用preg_match_all根據$pattern正則來進行數值匹配,并將返回的結果以數組形式存儲在$matches中,
* $matches[0]將包含與整個模式匹配的文本,$matches[1] 將包含與第一個捕獲的括號中的子模式所匹配的文本,以此類推
* @see Store::data_convert()
*/
public function data_convert($pattern,$subject) {
$matches=array();
if (preg_match_all($pattern, $subject,$matches)){
return $matches[0];
}else
{
return null;
}
}
}調用的時候變為:
$store=new storeDataAdapter($txtContent);
$match=array();
$dsName=$store->data_convert(‘/[\x7f-\xff]+/',$txtContent);
foreach ($dsName as $val){
echo $val."<br>";
}
輸入文件為:
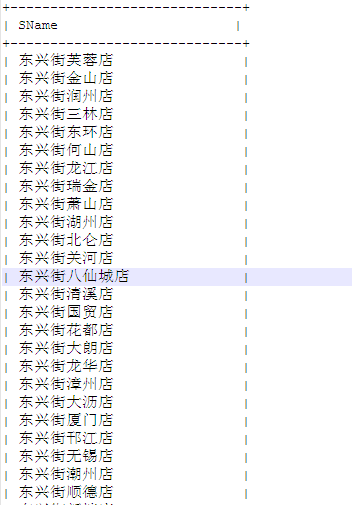
,下面是提取出中文之后的輸出文件內容:

,符合預期需求。
上述內容就是如何在PHP中利用正則表達式對中文進行提取,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





