溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Swoole協程的原理是什么的內容。小編覺得挺實用的,因此分享給大家做個參考。一起跟隨小編過來看看吧。
進程就是應用程序的啟動實例。獨立的文件資源,數據資源,內存空間。
線程屬于進程,是程序的執行者。一個進程至少包含一個主線程,也可以有更多的子線程。線程有兩種調度策略,一是:分時調度,二是:搶占式調度。
我的官方企鵝群
協程是輕量級線程,協程也是屬于線程,協程是在線程里執行的。協程的調度是用戶手動切換的,所以又叫用戶空間線程。協程的創建、切換、掛起、銷毀全部為內存操作,消耗是非常低的。協程的調度策略是:協作式調度。
Swoole4 由于是單線程多進程的,同一時間同一個進程只會有一個協程在運行。
Swoole server 接收數據在 worker 進程觸發 onReceive 回調,產生一個攜程。Swoole 為每個請求創建對應攜程。協程中也能創建子協程。
協程在底層實現上是單線程的,因此同一時間只有一個協程在工作,協程的執行是串行的。
因此多任務多協程執行時,一個協程正在運行時,其他協程會停止工作。當前協程執行阻塞 IO 操作時會掛起,底層調度器會進入事件循環。當有 IO 完成事件時,底層調度器恢復事件對應的協程的執行。。所以協程不存在 IO 耗時,非常適合高并發 IO 場景。(如下圖)
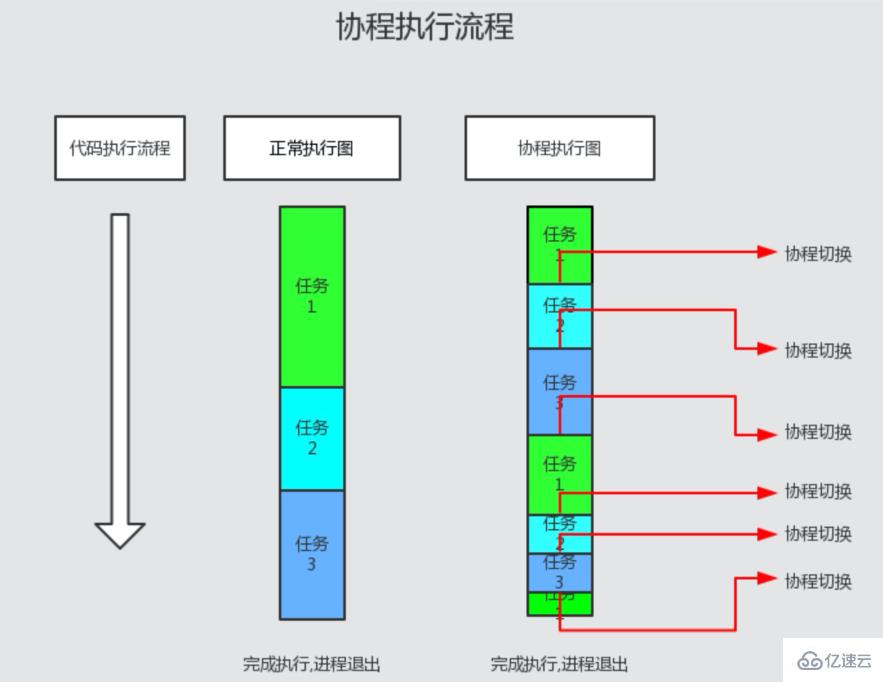
協程沒有 IO 等待 正常執行 PHP 代碼,不會產生執行流程切換
協程遇到 IO 等待 立即將控制權切,待 IO 完成后,重新將執行流切回原來協程切出的點
協程并行協程依次執行,同上一個邏輯
協程嵌套執行流程由外向內逐層進入,直到發生 IO,然后切到外層協程,父協程不會等待子協程結束
先來看看基礎的例子:
go(function () {
echo "hello go1 \n";});echo "hello main \n";go(function () {
echo "hello go2 \n";});go() 是 \Co::create() 的縮寫, 用來創建一個協程, 接受 callback 作為參數, callback 中的代碼, 會在這個新建的協程中執行.
備注: \Swoole\Coroutine 可以簡寫為 \Co
上面的代碼執行結果:
root@b98940b00a9b /v/w/c/p/swoole# php co.phphello go1 hello main hello go2
執行結果和我們平時寫代碼的順序, 好像沒啥區別. 實際執行過程:
運行此段代碼, 系統啟動一個新進程
遇到 go(), 當前進程中生成一個協程, 協程中輸出 heelo go1, 協程退出
進程繼續向下執行代碼, 輸出 hello main
再生成一個協程, 協程中輸出heelo go2, 協程退出
運行此段代碼, 系統啟動一個新進程. 如果不理解這句話, 你可以使用如下代碼:
// co.php<?phpsleep(100);
執行并使用 ps aux 查看系統中的進程:
root@b98940b00a9b /v/w/c/p/swoole# php co.php &?
root@b98940b00a9b /v/w/c/p/swoole# ps auxPID USER TIME COMMAND
1 root 0:00 php -a 10 root 0:00 sh 19 root 0:01 fish 749 root 0:00 php co.php 760 root 0:00 ps aux
?我們來稍微改一改, 體驗協程的調度:
use Co;go(function () {
Co::sleep(1); // 只新增了一行代碼
echo "hello go1 \n";});echo "hello main \n";go(function () {
echo "hello go2 \n";});\Co::sleep() 函數功能和 sleep() 差不多, 但是它模擬的是 IO等待(IO后面會細講). 執行的結果如下:
root@b98940b00a9b /v/w/c/p/swoole# php co.phphello main hello go2 hello go1
怎么不是順序執行的呢? 實際執行過程:
go(), 當前進程中生成一個協程Co::sleep() 模擬出的 IO等待), 協程讓出控制, 進入協程調度隊列hello mainhello go2hello go1到這里, 已經可以看到 swoole 中 協程與進程的關系, 以及 協程的調度, 我們再改一改剛才的程序:
go(function () {
Co::sleep(1);
echo "hello go1 \n";});echo "hello main \n";go(function () {
Co::sleep(1);
echo "hello go2 \n";});我想你已經知道輸出是什么樣子了:
root@b98940b00a9b /v/w/c/p/swoole# php co.phphello main hello go1 hello go2 ?
大家可能聽到使用協程的最多的理由, 可能就是 協程快. 那看起來和平時寫得差不多的代碼, 為什么就要快一些呢? 一個常見的理由是, 可以創建很多個協程來執行任務, 所以快. 這種說法是對的, 不過還停留在表面.
首先, 一般的計算機任務分為 2 種:
其次, 高性能相關的 2 個概念:
了解了這些, 我們再來看協程, 協程適合的是 IO 密集型 應用, 因為協程在 IO阻塞 時會自動調度, 減少IO阻塞導致的時間損失.
我們可以對比下面三段代碼:
$n = 4;for ($i = 0; $i < $n; $i++) {
sleep(1);
echo microtime(true) . ": hello $i \n";};echo "hello main \n";root@b98940b00a9b /v/w/c/p/swoole# time php co.php1528965075.4608: hello 01528965076.461: hello 11528965077.4613: hello 21528965078.4616: hello 3hello main real 0m 4.02s user 0m 0.01s sys 0m 0.00s ?
$n = 4;go(function () use ($n) {
for ($i = 0; $i < $n; $i++) {
Co::sleep(1);
echo microtime(true) . ": hello $i \n";
};});echo "hello main \n";root@b98940b00a9b /v/w/c/p/swoole# time php co.phphello main1528965150.4834: hello 01528965151.4846: hello 11528965152.4859: hello 21528965153.4872: hello 3real 0m 4.03s user 0m 0.00s sys 0m 0.02s ?
$n = 4;for ($i = 0; $i < $n; $i++) {
go(function () use ($i) {
Co::sleep(1);
echo microtime(true) . ": hello $i \n";
});};echo "hello main \n";root@b98940b00a9b /v/w/c/p/swoole# time php co.phphello main1528965245.5491: hello 01528965245.5498: hello 31528965245.5502: hello 21528965245.5506: hello 1real 0m 1.02s user 0m 0.01s sys 0m 0.00s ?
為什么時間有這么大的差異呢:
普通寫法, 會遇到 IO阻塞 導致的性能損失
單協程: 盡管 IO阻塞 引發了協程調度, 但當前只有一個協程, 調度之后還是執行當前協程
多協程: 真正發揮出了協程的優勢, 遇到 IO阻塞 時發生調度, IO就緒時恢復運行
我們將多協程版稍微修改一下:
$n = 4;for ($i = 0; $i < $n; $i++) {
go(function () use ($i) {
// Co::sleep(1);
sleep(1);
echo microtime(true) . ": hello $i \n";
});};echo "hello main \n";root@b98940b00a9b /v/w/c/p/swoole# time php co.php1528965743.4327: hello 01528965744.4331: hello 11528965745.4337: hello 21528965746.4342: hello 3hello main real 0m 4.02s user 0m 0.01s sys 0m 0.00s ?
只是將 Co::sleep() 改成了 sleep(), 時間又和普通版差不多了. 因為:
sleep() 可以看做是 CPU密集型任務, 不會引起協程的調度
Co::sleep() 模擬的是 IO密集型任務, 會引發協程的調度
這也是為什么, 協程適合 IO密集型 的應用.
再來一組對比的例子: 使用 redis
// 同步版, redis使用時會有 IO 阻塞$cnt = 2000;for ($i = 0; $i < $cnt; $i++) {
$redis = new \Redis();
$redis->connect('redis');
$redis->auth('123');
$key = $redis->get('key');}// 單協程版: 只有一個協程, 并沒有使用到協程調度減少 IO 阻塞go(function () use ($cnt) {
for ($i = 0; $i < $cnt; $i++) {
$redis = new Co\Redis();
$redis->connect('redis', 6379);
$redis->auth('123');
$redis->get('key');
}});// 多協程版, 真正使用到協程調度帶來的 IO 阻塞時的調度for ($i = 0; $i < $cnt; $i++) {
go(function () {
$redis = new Co\Redis();
$redis->connect('redis', 6379);
$redis->auth('123');
$redis->get('key');
});}性能對比:
# 多協程版root@0124f915c976 /v/w/c/p/swoole# time php co.phpreal 0m 0.54s user 0m 0.04s sys 0m 0.23s ?# 同步版root@0124f915c976 /v/w/c/p/swoole# time php co.phpreal 0m 1.48s user 0m 0.17s sys 0m 0.57s ?
接觸過 go 協程的 coder, 初始接觸 swoole 的協程會有點 懵, 比如對比下面的代碼:
package main
import (
"fmt"
"time")func main() {
go func() {
fmt.Println("hello go")
}()
fmt.Println("hello main")
time.Sleep(time.Second)}> 14:11 src $ go run test.go hello main hello go
剛寫 go 協程的 coder, 在寫這個代碼的時候會被告知不要忘了 time.Sleep(time.Second), 否則看不到輸出 hello go, 其次, hello go與 hello main 的順序也和 swoole 中的協程不一樣.
原因就在于 swoole 和 go 中, 實現協程調度的模型不同.
上面 go 代碼的執行過程:
package main, 然后執行其中的 func mian()hello maintime.Sleep(time.Second), main 函數執行完, 程序結束, 進程退出, 導致調度中的協程也終止go 中的協程, 使用的 MPG 模型:
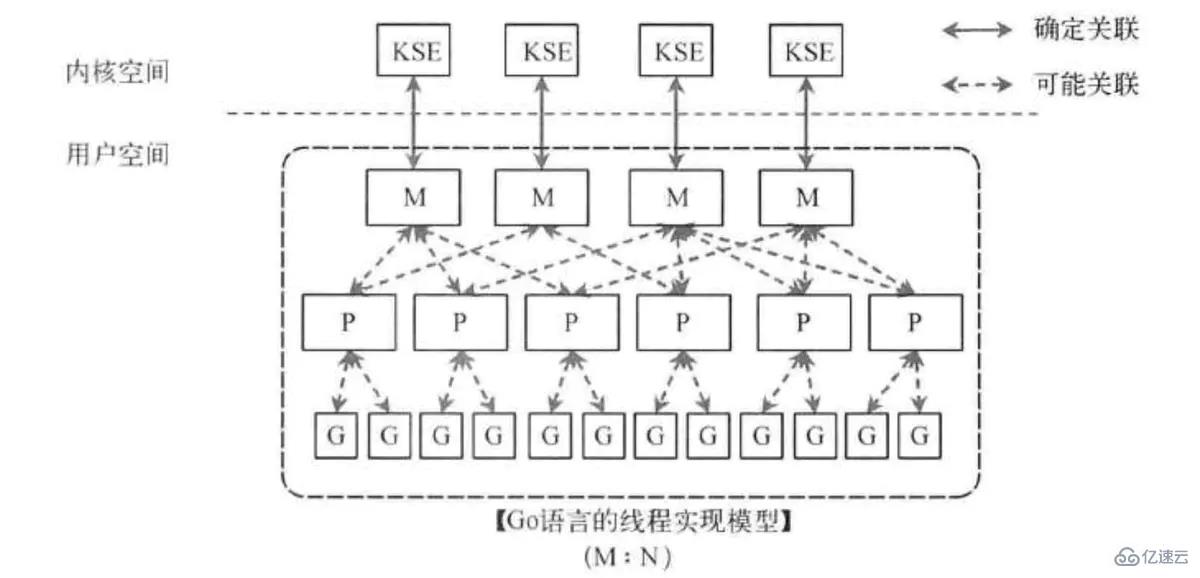
而 swoole 中的協程調度使用 單進程模型, 所有協程都是在當前進程中進行調度, 單進程的好處也很明顯 – 簡單 / 不用加鎖 / 性能也高.
無論是 go 的 MPG模型, 還是 swoole 的 單進程模型, 都是對 CSP理論 的實現.
感謝各位的閱讀!關于Swoole協程的原理是什么就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





