溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python分布式爬蟲原理是什么,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討吧!
首先,我們先來看看,如果是人正常的行為,是如何獲取網頁內容的。
(1)打開瀏覽器,輸入URL,打開源網頁
(2)選取我們想要的內容,包括標題,作者,摘要,正文等信息
(3)存儲到硬盤中
上面的三個過程,映射到技術層面上,其實就是:網絡請求,抓取結構化數據,數據存儲。
我們使用Python寫一個簡單的程序,實現上面的簡單抓取功能。
#!/usr/bin/python
#-*- coding: utf-8 -*-
'''''
Created on 2014-03-16
@author: Kris
'''
import urllib2, re, cookielib
def httpCrawler(url):
'''''
@summary: 網頁抓取
'''
content = httpRequest(url)
title = parseHtml(content)
saveData(title)
def httpRequest(url):
'''''
@summary: 網絡請求
'''
try:
ret = None
SockFile = None
request = urllib2.Request(url)
request.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; SV1; .NET CLR 1.1.4322)')
request.add_header('Pragma', 'no-cache')
opener = urllib2.build_opener()
SockFile = opener.open(request)
ret = SockFile.read()
finally:
if SockFile:
SockFile.close()
return ret
def parseHtml(html):
'''''
@summary: 抓取結構化數據
'''
content = None
pattern = '<title>([^<]*?)</title>'
temp = re.findall(pattern, html)
if temp:
content = temp[0]
return content
def saveData(data):
'''''
@summary: 數據存儲
'''
f = open('test', 'wb')
f.write(data)
f.close()
if __name__ == '__main__':
url = 'http://www.baidu.com'
httpCrawler(url)看著很簡單,是的,它就是一個爬蟲入門的基礎程序。當然,在實現一個采集過程,無非就是上面的幾個基礎步驟。但是實現一個強大的采集過程,你會遇到下面的問題:
(1)需要帶著cookie信息訪問,比如大多數的社交化軟件,基本上都是需要用戶登錄之后,才能看到有價值的東西,其實很簡單,我們可以使用Python提供的cookielib模塊,實現每次訪問都帶著源網站給的cookie信息去訪問,這樣只要我們成功模擬了登錄,爬蟲處于登錄狀態,那么我們就可以采集到登錄用戶看到的一切信息了。下面是使用cookie對httpRequest()方法的修改:
ckjar = cookielib.MozillaCookieJar()
cookies = urllib2.HTTPCookieProcessor(ckjar) #定義cookies對象
def httpRequest(url):
'''''
@summary: 網絡請求
'''
try:
ret = None
SockFile = None
request = urllib2.Request(url)
request.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; SV1; .NET CLR 1.1.4322)')
request.add_header('Pragma', 'no-cache')
opener = urllib2.build_opener(cookies) #傳遞cookies對象
SockFile = opener.open(request)
ret = SockFile.read()
finally:
if SockFile:
SockFile.close()
return ret(2)編碼問題。網站目前最多的兩種編碼:utf-8,或者gbk,當我們采集回來源網站編碼和我們數據庫存儲的編碼不一致時,比如,163.com的編碼使用的是gbk,而我們需要存儲的是utf-8編碼的數據,那么我們可以使用Python中提供的encode()和decode()方法進行轉換,比如:
content = content.decode('gbk', 'ignore') #將gbk編碼轉為unicode編碼
content = content.encode('utf-8', 'ignore') #將unicode編碼轉為utf-8編碼中間出現了unicode編碼,我們需要轉為中間編碼unicode,才能向gbk或者utf-8轉換。
(3)網頁中標簽不完整,比如有些源代碼中出現了起始標簽,但沒有結束標簽,HTML標簽不完整,就會影響我們抓取結構化數據,我們可以通過Python的BeautifulSoup模塊,先對源代碼進行清洗,再分析獲取內容。
(4)某些網站使用JS來生存網頁內容。當我們直接查看源代碼的時候,發現是一堆讓人頭疼的JS代碼。可以使用mozilla、webkit等可以解析瀏覽器的工具包解析js、ajax,雖然速度會稍微慢點。
(5)圖片是flash形式存在的。當圖片中的內容是文字或者數字組成的字符,那這個就比較好辦,我們只要利用ocr技術,就能實現自動識別了,但是如果是flash鏈接,我們將整個URL存儲起來了。
(6)一個網頁出現多個網頁結構的情況,這樣我們如果只是一套抓取規則,那肯定不行,所以需要配置多套模擬進行協助配合抓取。
(7)應對源網站的監控。抓取別人的東西,畢竟是不太好的事情,所以一般網站都會有針對爬蟲禁止訪問的限制。
一個好的采集系統,應該是,不管我們的目標數據在何處,只要是用戶能夠看到的,我們都能采集回來。所見即所得的無阻攔式采集,無論是否需要登錄的數據都能夠順利采集。大部分有價值的信息,一般都需要登錄才能看到,比如社交網站,為了應對登錄的網站要有模擬用戶登錄的爬蟲系統,才能正常獲取數據。不過社會化網站都希望自己形成一個閉環,不愿意把數據放到站外,這種系統也不會像新聞等內容那么開放的讓人獲取。這些社會化網站大部分會采取一些限制防止機器人爬蟲系統爬取數據,一般一個賬號爬取不了多久就會被檢測出來被禁止訪問了。那是不是我們就不能爬取這些網站的數據呢?肯定不是這樣的,只要社會化網站不關閉網頁訪問,正常人能夠訪問的數據,我們也能訪問。說到底就是模擬人的正常行為操作,專業一點叫“反監控”。
源網站一般會有下面幾種限制:
1、一定時間內單個IP訪問次數,一個正常用戶訪問網站,除非是隨意的點著玩,否則不會在一段持續時間內過快訪問一個網站,持續時間也不會太長。這個問題好辦,我們可以采用大量不規則代理IP形成一個代理池,隨機從代理池中選擇代理,模擬訪問。代理IP有兩種,透明代理和匿名代理。
2、一定時間內單個賬號訪問次數,如果一個人一天24小時都在訪問一個數據接口,而且速度非常快,那就有可能是機器人了。我們可以采用大量行為正常的賬號,行為正常就是普通人怎么在社交網站上操作,并且單位時間內,訪問URL數目盡量減少,可以在每次訪問中間間隔一段時間,這個時間間隔可以是一個隨機值,即每次訪問完一個URL,隨機隨眠一段時間,再接著訪問下一個URL。
如果能把賬號和IP的訪問策略控制好了,基本就沒什么問題了。當然對方網站也會有運維會調整策略,敵我雙方的一場較量,爬蟲必須要能感知到對方的反監控將會對我們有影響,通知管理員及時處理。其實最理想的是能夠通過機器學習,智能的實現反監控對抗,實現不間斷地抓取。
下面是本人近期正在設計的一個分布式爬蟲架構圖,如圖1所示:
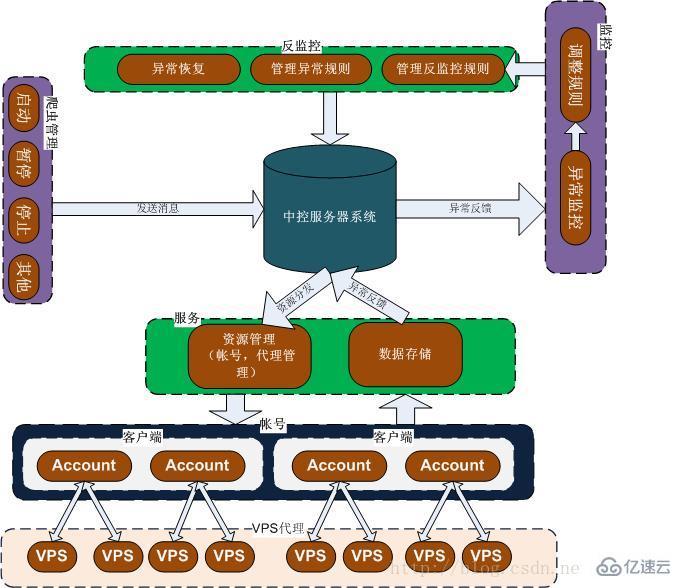
看完了這篇文章,相信你對Python分布式爬蟲原理是什么有了一定的了解,想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





