溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
mysql數據庫中如何實現動態修改復制過濾器?針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
MySQL動態修改復制過濾器
說說今天遇到的問題吧,今天在處理一個業務方的需求,比較變態,我大概描述一下:
1、線上的阿里云rds上面有個游戲的日志庫,里面的表都是日表的形式,數據量比較大了,每次備份的時候,都會導致線上的rds報警,報警內容是IO資源占用過多。
2、這個rds上有一個本地的ECS只讀從庫,這個只讀從庫會實時同步線上的rds數據庫中的數據,這個只讀從庫供業務方查詢使用
3、業務方說這些數據都還有用,只讀從庫上的數據必須有,線上rds上的數據可以刪除,保留兩個星期即可。
場景就是這么個場景,DBA想要解決報警這個問題,業務方想要保證擁有完整的數據。請問,怎么解決?
當時看到這個問題,我想罵人,這需求一看就不合理,哪兒有刪除一個庫,另外一個庫上還保留的道理,況且都是些日志數據,不直接搞個冷備份,然后刪除線上,搞這么一出干啥啊。但是啊,怎么說也沒有緩和的余地,于是就開始思考這個問題應該怎么解決。我想到的解決辦法有以下幾個:
1、擴容,提升性能。數據量大,擴磁盤唄,IO使用率高,提升性能么,這是最直接的解決辦法,也是最貴的解決辦法,首先被砍掉。
2、先備份再刪除再還原。rds主庫上提前備份日表數據,然后刪除數據,此時從庫會同步刪除數據,然后再將第一步備份的數據還原到從庫上。這個辦法從可行性上來講是可以的,因為保證了沒有數據丟失。但是操作起來比較麻煩,手續太多,不夠方便。
3、使用replicate-ignore-table參數進行對于指定的表進行過濾。設置了這個參數,可以讓你過濾指定數據表的所有操作。我們看看官方文檔對這個參數的描述,給個鏈接:https://dev.mysql.com/doc/refman/5.7/en/replication-options-slave.html#option_mysqld_replicate-wild-ignore-table
描述如下:
Creates a replication filter which keeps the slave thread from replicating a statement in which any table matches the given wildcard pattern. To specify more than one table to ignore, use this option multiple times,
上面的意思是你可以使用這個參數創建一個過濾器,從而過濾掉匹配你制定的規則的特定表的操作(聽著很繞口),就是說你可以制定過濾規則,加入規則中制定了表a,那么表a的操作就不會同步到從庫中了。
這和我們的需求符合,也就是我們如果設置了要過濾的表,那么當我們進行刪除表操作的時候,從庫中不會對表進行刪除,就實現了我們想要的結果。測試一下這個功能吧:
首先我們創建數據庫test_ignore,然后在其中創建表:
主庫上操作:
mysql :test_ignore >>show tables; Empty set (0.00 sec) mysql :test_ignore >>create table aaa (id int not null); Query OK, 0 rows affected (0.19 sec) mysql :test_ignore >>create table aab (id int not null); Query OK, 0 rows affected (0.01 sec) mysql :test_ignore >>create table aac (id int not null); Query OK, 0 rows affected (0.00 sec) mysql :test_ignore >>create table aad (id int not null); Query OK, 0 rows affected (0.01 sec) mysql :test_ignore >>create table aae (id int not null); Query OK, 0 rows affected (0.01 sec)
從庫上查看:
mysql :test_ignore >>show tables; +-----------------------+ | Tables_in_test_ignore | +-----------------------+ | aaa | | aab | | aac | | aad | | aae | +-----------------------+ 5 rows in set (0.00 sec)
發現已經同步過來了。此時是處于主從同步狀態,如果現在我們在主庫上刪除表,那么從庫上的表一定會刪除,這不是我們想要的結果。
很顯然,接下來的一步是配置replicate-wild-ignore-table這個參數了,一般情況下,我們需要通過停止從庫的服務進行my.cnf文件的配置,如果我們要配置多個表,則需要在my.cnf文件中寫多條通配的記錄。例如,在本例子中,需要配置該參數的值為test_ignore.aa%,其中%代表通配符,也就是說,test_ignore數據庫中形如aa%這種格式的表操作都會被過濾掉。而我們創建的表aaa、aab、aac、aad、aae都是形如這種的,所以針對這幾個表的操作一定不會同步到從庫了,我們測試一下:
首先查看當前的復制狀態:
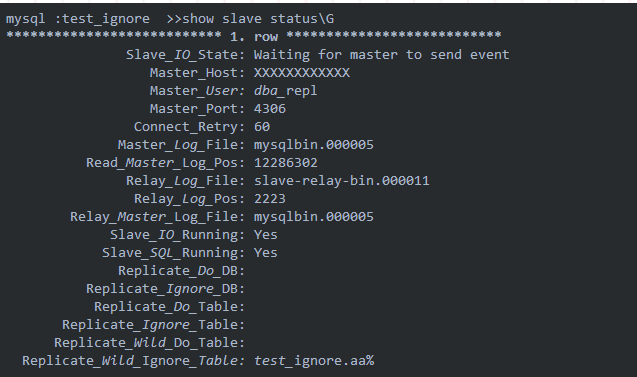
雙Yes狀態,說明復制關系沒有問題
主庫進行操作:
mysql :test_ignore >>drop table aaa; Query OK, 0 rows affected (0.01 sec) mysql :test_ignore >>drop table aab; Query OK, 0 rows affected (0.00 sec)
從庫上進行查看:
mysql :test_ignore >>show tables; +-----------------------+ | Tables_in_test_ignore | +-----------------------+ | aaa | | aab | | aac | | aad | | aae | +-----------------------+ 5 rows in set (0.00 sec)
從庫上的表還在,說明主庫上的操作沒有被同步到從庫,我們配置的參數
replicate-wild-ignore-table=test_ignore.aa%
起作用了。此時,如果我們在主庫上創建一個表:
`主庫` mysql :test_ignore >>create table aaf(id int); Query OK, 0 rows affected (0.00 sec) `從庫` mysql :test_ignore >>show tables; +-----------------------+ | Tables_in_test_ignore | +-----------------------+ | aaa | | aab | | aac | | aad | | aae | +-----------------------+ 5 rows in set (0.00 sec)
發現從庫并沒有同步主庫的表aaf,因為aaf也匹配了test_ignore.aa%這條規則。
利用這個特性,我們能夠很好的解決這個業務場景,也就是主庫刪除,從庫保留數據。但是,這里要說但是了,這個方法有一個比較嚴重的問題,就是每次都需要重啟從庫,如果我們需要配置第二條規則,第三條規則,則需要重啟從庫2次,3次,這個過程中,從庫對于業務方是不可見的,如果無法訪問,很可能造成程序報錯,這是我們不能忍受的。
這個過程肯定是要解決的,怎么解決呢?能不能找到不停機就能修改復制過濾器的方法?找找官方文檔。
果然,停機是不可能停機的,這輩子都不可能停機。官方文檔中有這么一句話:
You can also create such a filter by issuing a CHANGE REPLICATION FILTER REPLICATE_WILD_IGNORE_TABLE statement.
我去,這是個啥語句,表示從來沒有用過,可以通過在線變更復制過濾器的方法來對過濾器進行修改,看看官方文檔中的介紹:

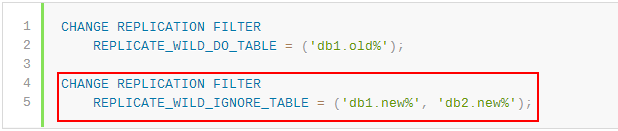
看到了一個神奇的語句,趕緊來試試:
mysql :test_ignore >>change replication filter replicate_wild_ignore_table=('test_ig%.aa%');
ERROR 3017 (HY000): This operation cannot be performed with a running slave sql thread; run STOP SLAVE SQL_THREAD first
mysql :test_ignore >>stop slave;
Query OK, 0 rows affected (0.00 sec)
mysql :test_ignore >>change replication filter replicate_wild_ignore_table=('test_ig%.aa%');
Query OK, 0 rows affected (0.00 sec)
mysql :test_ignore >>start slave;
Query OK, 0 rows affected (0.01 sec)直接使用,提示需要stop slave sql_thread,想想也能理解,不停止復制直接修改復制的規則好像有點不妥,索性停止了整個復制,然后重新修改復制過濾器,妥了,成功執行,開啟復制,一套操作行云流水。
再來看看復制關系中的狀態:
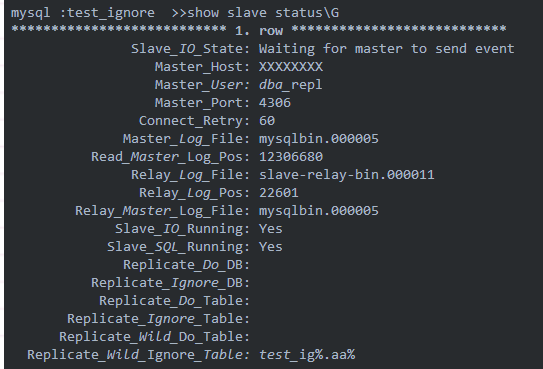
忽略的表規則已經變成了test_ig%.aa%,也就是說,以test_ig開頭的數據庫中以aa開頭的表的操作,都不會被同步到從庫,包括對表的alter和drop以及create操作。
但這里,方案就出來了,我們知道,日表一般是YYYYMMDD這種形式的,我們只要過濾YYYYMM%這種格式的日表,然后在主庫上對它進行刪除,這個操作將不會被同步到從庫,那么這個問題就可以順利解決了。
當然,除了這個方案之外,還有一些方案,例如:
如果業務容忍部分數據丟失,我們還可以使用關閉binlog---刪表---打開binlog的方式使得從庫不會同步主庫的drop操作;
線上所有的日表操作都配置成ignore,然后利用觸發器將日表中的更新同步到從庫中;
這一系列的操作,其實不是從本質上解決問題,本質上還是業務設計的問題,日表中的打點日志太多,可以適當減少這些打點日志,對于打點日志,需要確定保留周期,過期的日志,需要及時清理,保證服務器的指標和性能。
關于mysql數據庫中如何實現動態修改復制過濾器問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





