溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關如何實現Selenium+BeautifulSoup4制作一個python爬蟲,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
在學會了抓包,接口請求(如requests庫)和Selenium的一些操作方法后,基本上就可以編寫爬蟲,爬取絕大多數網站的內容。
在爬蟲領域,Selenium永遠是最后一道防線。從本質上來說,訪問網頁實際上就是一個接口請求。請求url后,返回的是網頁的源代碼。
我們只需要解析html或者通過正則匹配提取出我們需要的數據即可。
有些網站我們可以使用requests.get(url),得到的響應文本中獲取到所有的數據。而有些網頁數據是通過JS動態加載到頁面中的。使用requests獲取不到或者只能獲取到一部分數據。
此時我們就可以使用selenium打開頁面來,使用driver.page_source來獲取JS執行完后的完整源代碼。
例如,我們要爬取,diro官網女包的名稱,價格,url,圖片等數據,可以使用requests先獲取到網頁源代碼:
訪問網頁,打開開發者工具,我們可以看到所有的商品都在一個
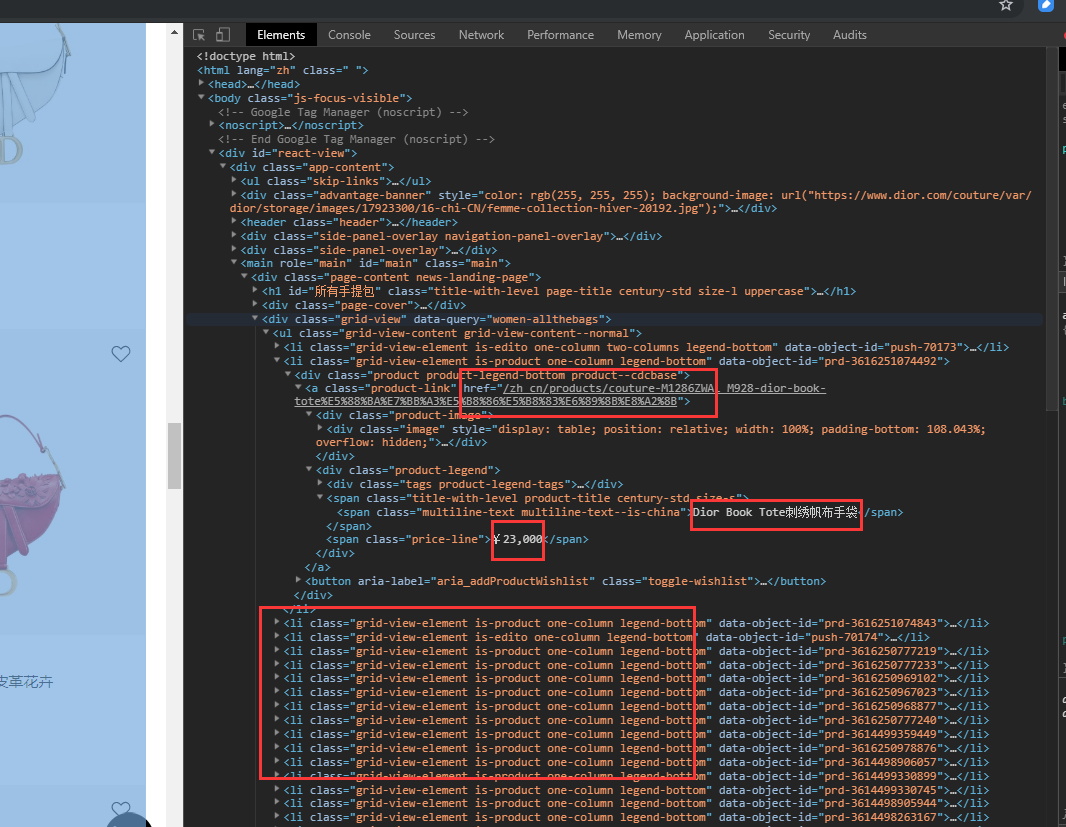
從html格式的源碼中提取數據,有多種選擇,可以使用xml.etree等等方式,bs4是一個比較方便易用的html解析庫,配合lxml解析速度比較快。
bs4的使用方法為
from bs4 import BeautifulSoup
soup = BeautifulSoup(網頁源代碼字符串,'lxml')
soup.find(...).find(...)
soup.findall()
soup.select('css selector語法')soup.find()可以通過節點屬性進行查找,如,soup.find('div', id='節點id')或soup.find('li', class_='某個類名')或soup.find('標簽名', 屬性=屬性值),當找到一個節點后,還可以使用這個節點繼續在其子節點中查找。
soup.find_all()是查找多個,同樣屬性的節點,返回一個列表。
soup.select()是使用css selector語法查找,返回一個列表。
以下為示例代碼:
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
driver.get('https://www.dior.cn/zh_cn/女士精品/皮具系列/所有手提包')
soup = BeautifulSoup(driver.page_source, 'lxml')
products = soup.select('li.is-product')
for product in products:
name = product.find('span', class_='product-title').text.strip()
price = product.find('span', class_='price-line').text.replace('¥', '').replace(',','')
url = 'https://www.dior.cn' + product.find('a', class_='product-link').attrs['href']
img = product.find('img').attrs['src']
sku = img.split('/')[-1]
print(name, sku, price)
driver.quit()運行結果,如下圖:
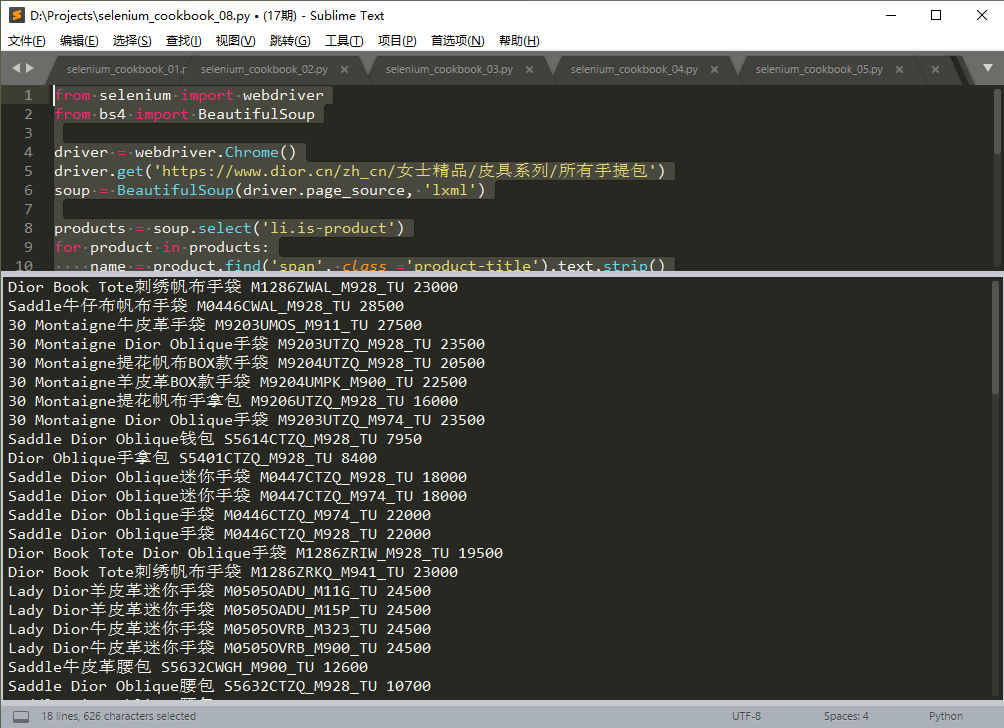
注:本例中,也可以使用requests.get()獲取網頁源代碼,格式和使用selenium加載的稍有不同。
一般簡單爬蟲編寫的步驟為:
上述就是小編為大家分享的如何實現Selenium+BeautifulSoup4制作一個python爬蟲了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





