溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下python中多線程是什么,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
大家可以根據以下Python多線程的實例應用和結合現有認知更深刻了解python多線程。
在Python 3中已經內置了_thread和threading兩個模塊來實現多線程。相較于_thread,threading提供的方法更多而且更常用,因此接下來我們將舉例講解threading模塊的用法,首先來看下面這段代碼:
import threading
import time
def say_after(what, delay):
print (what)
time.sleep(delay)
print (what)
t = threading.Thread(target = say_after, args = ('hello',3))
t.start()1、這里我們導入了threading這個Python內置模塊來實現多線程。之后定義了一個say_after(what, delay)函數,該函數包含what和delay兩個參數,分別用來表示打印的內容,以及time.sleep()休眠的時間。
2、隨后我們使用threading的Thread()函數為say_after(what, delay)函數創建了一個線程并將它賦值給變量t,注意Thread()里的target參數對應的是函數名稱(即這里的say_after),args對應的是該say_after函數里的參數,這里等同于“what = ‘hello’”,“delay = 3”。
3、最后我們調用threading中的start()來啟動我們剛剛創建的線程。
運行代碼效果:

在打印出第一個hello后,程序因為time.sleep(3)休眠了三秒,三秒之后隨即打印出了第二個hello。因為這時我們只運行了say_after(what, delay)這一個函數,并且只運行了一次,因此即使我們現在啟用了多線程,我們也感受不了它和單線程有什么區別。接下來我們將該代碼修改如下:
#coding=utf-8
import threading
import time
def say_after(what, delay):
print (what)
time.sleep(delay)
print (what)
t = threading.Thread(target = say_after, args = ('hello',3))
print (f"程序于 {time.strftime('%X')} 開始執行")
t.start()
print (f"程序于 {time.strftime('%X')} 執行結束")這一次我們調用time.strftime()來嘗試記錄程序執行前和執行后的時間,看看有什么“意想不到”的結果。
運行代碼效果:
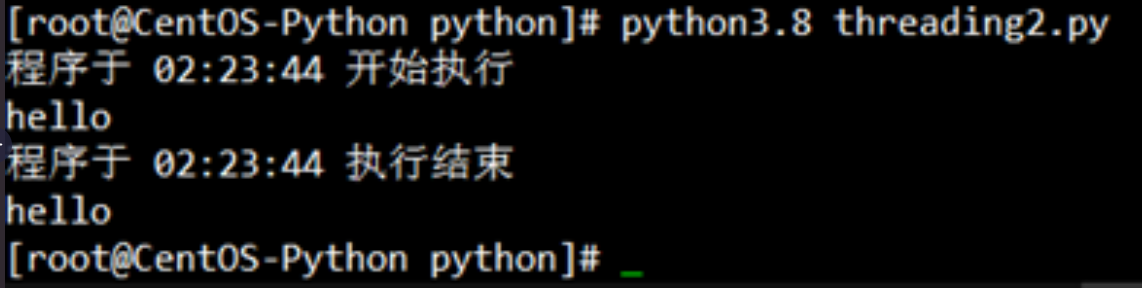
這里除了threading.Thread()為say_after()函數創建的用戶線程外,“print (f"程序于 {time.strftime('%X')} 開始執行")”和“print (f"程序于 {time.strftime('%X')} 執行結束")”兩個print()函數也共同占用了公用的內核線程。也就是說該腳本現在實際上是調用了兩個線程:一個用戶線程,一個內核線程,也就構成了一個多線程的環境。因為分屬不同的線程,say_after()函數和函數之外的兩個print語句是同時運行的,互不干涉。
如果想要正確捕捉say_after(what, delay)函數開始和結束時的時間,我們需要額外使用threading模塊的join()方法,來看下面的代碼:
#coding=utf-8
import threading
import time
def say_after(what, delay):
print (what)
time.sleep(delay)
print (what)
t = threading.Thread(target = say_after, args = ('hello',3))
print (f"程序于 {time.strftime('%X')} 開始執行")
t.start()
t.join()
print (f"程序于 {time.strftime('%X')} 執行結束")這里我們只修改了代碼的一處地方,即在t.start()下面添加了一個t.join(),join()方法的作用是強制阻塞調用它的線程,直到該線程運行完畢或者終止為止(類似于單線程同步)。因為這里調用join()方法的變量t正是我們用threading.Thread()為say_after(what, delay)創建的用戶線程,因此使用內核線程的“print (f"程序于 {time.strftime('%X')} 執行結束")”必須等待該用戶線程執行完畢過后才能繼續執行,因此腳本在執行時的效果會讓你覺得整體還是以“單線程同步”的方式運行的。
運行代碼效果:
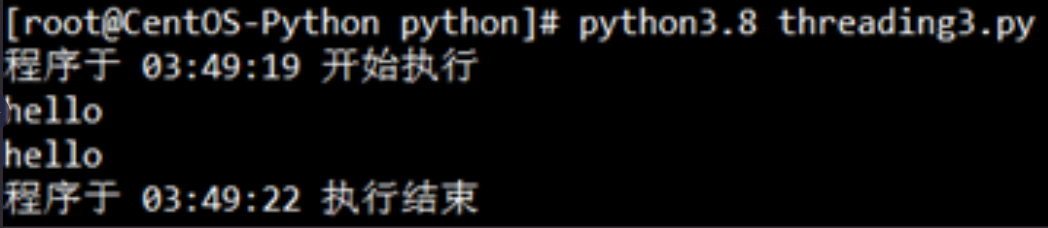
最后我們再舉一例,來看看創建多個用戶線程并運行,代碼如下:
#coding=utf-8
import threading
import time
def say_after(what, delay):
print (what)
time.sleep(delay)
print (what)
print (f"程序于 {time.strftime('%X')} 開始執行\n")
threads = []
for i in range(1,6):
t = threading.Thread(target=say_after, name="線程" + str(i), args=('hello',3))
print(t.name + '開始執行。')
t.start()
threads.append(t)
for i in threads:
i.join()
print (f"\n程序于 {time.strftime('%X')} 執行結束")這里我們使用for循環配合range(1,6)創建了5個線程,并且將它們以多線程的形式執行,也就是把say_after(what, delay)函數以多線程的形式執行了5次。每個線程作為元素加入進了threads這個空列表,然后我們再次使用for語句來遍歷現在已經有了5個線程的threads列表,對其中的每個線程都調用的join()方法,確保直到它們都執行結束后,我們才執行內核線程下的“print (f"程序于 {time.strftime('%X')} 執行結束")”。
運行代碼效果:
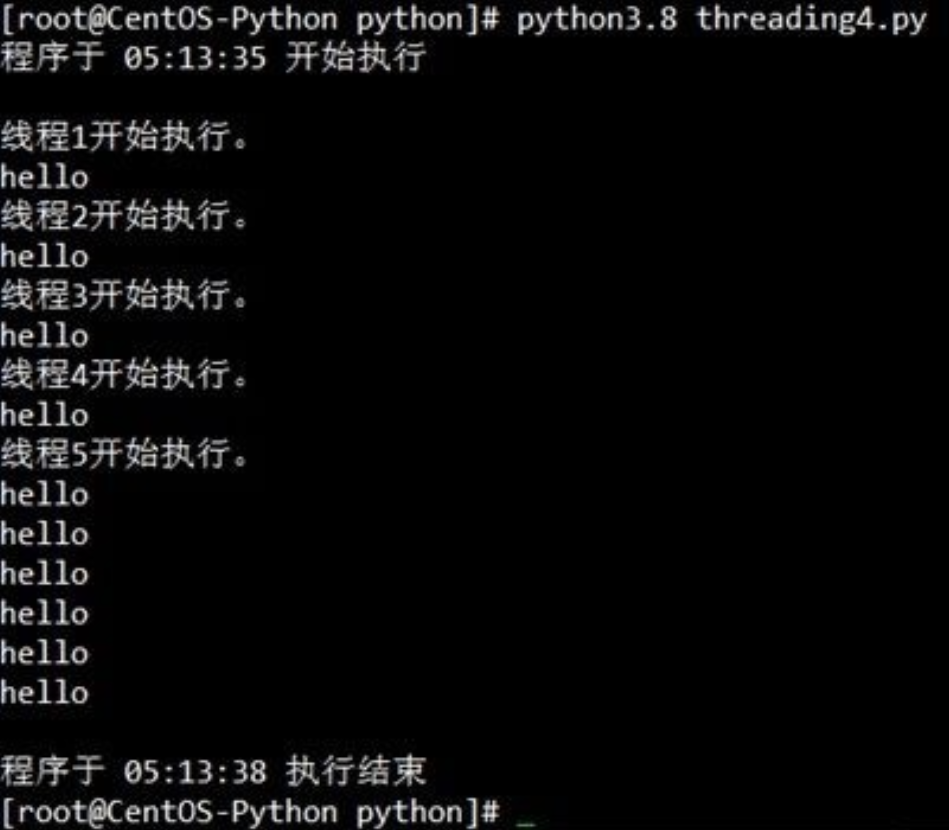
可以看到這里我們成功的使用了多線程將程序執行,如果以單線程來執行5次say_after(what,delay)函數的話,那么需要花費3x5=15秒才能跑完整個腳本,而在多線程的形式下,整個程序只花費了3秒就運行完畢。
以上是python中多線程是什么的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





