溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹Python中Pandas數據清洗的流程,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
針對數據統計分析來講,數據信息是無可置疑的核心內容。但并非是全部的數據信息都是有價值的,絕大部分數據信息是良莠不齊的,基本概念層次不清的,量級有所不同的,這就給后期的數據統計分析和數據挖掘造成 了很大的不便,甚至是造成不正確的理論依據。因此很有必要對數據信息開展預處理。
說到python與數據分析,那肯定少不了pandas的身影。
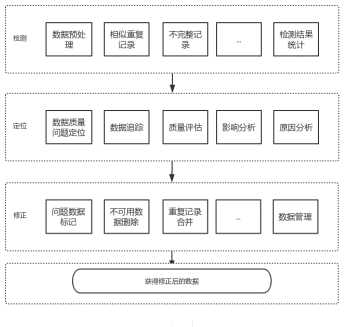
數據清洗是指發現并糾正數據文件中可識別的錯誤的最后一道程序,包括檢查數據一致性,處理無效值和缺失值等。與問卷審核不同,錄入后的數據清理一般是由計算機而不是人工完成。
數據清洗從名字上也看的出就是把“臟”的“洗掉”,指發現并糾正數據文件中可識別的錯誤的最后一道程序,包括檢查數據一致性,處理無效值和缺失值等。因為數據倉庫中的數據是面向某一主題的數據的集合,這些數據從多個業務系統中抽取而來而且包含歷史數據,這樣就避免不了有的數據是錯誤數據、有的數據相互之間有沖突,這些錯誤的或有沖突的數據顯然是我們不想要的,稱為“臟數據”。我們要按照一定的規則把“臟數據”“洗掉”,這就是數據清洗。而數據清洗的任務是過濾那些不符合要求的數據,將過濾的結果交給業務主管部門,確認是否過濾掉還是由業務單位修正之后再進行抽取。不符合要求的數據主要是有不完整的數據、錯誤的數據、重復的數據三大類。數據清洗是與問卷審核不同,錄入后的數據清理一般是由計算機而不是人工完成。
1.導入方法read_excel
# 導入數據
import pandas as pda
import matplotlib.pylab as pyl
a = pda.read_excel("D:\\迅雷下載\\工具\\表格\\練習.xls") # 路徑使用雙反斜杠,否則會報錯
print(len(a)) # 數據框的長度,是按行統計的
1234562.發現缺失值
先打開excel表,查看下有多少缺失值,缺失值是指值為0或空統計發現有10個缺失值,同理其他列也有部分缺失值然后著手把0值置空,保證所有的缺失值都是統一形式,方便處理
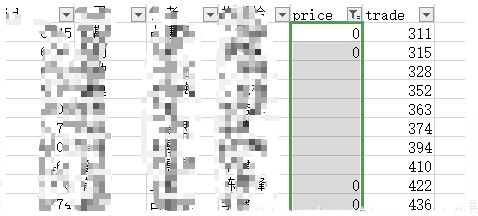
b = ["price", "trade"] for i in b: a[i][(a[i] == 0)] = None # a["price"] == 0 判斷語句,返回True或False ,對列表的每一個值進行判斷,如果有0,該處值置為none,然后進行判斷直至完成 1234
3.缺失值處理
遍歷所有的空值,統一賦值
x = 0 for j in b: for k in range(len(a)): if (a[j].isnull())[k]: a[j][k] = 36 x += 1 print(x)
異常數據指數據庫或數據倉庫中未滿足一般規律的數據信息對象,又叫作孤立點。異常的數據信息可由執行程序出現失誤形成,也可能會因設施設備內部故障造成的。異常數據信息可能是刪去的噪聲,也可能是帶有重要信息的數據單元。異常的數據信息的監測具體有根據統計學、根據距離和根據偏離3類方法。采取數據信息審時的辦法能夠實現異常的數據信息的智能化監測,該辦法也叫作數據質量挖掘(DOQM)。DQM具體由2步組成:第1步,采取數理統計辦法對數據分布展開概化描述,自動獲得數據信息的總體分布特征;第2步針對特定的數據質量問題展開挖掘以發現數據信息異常的。
以上是Python中Pandas數據清洗的流程的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





