溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關python如何實現調用有道智云API實現文件并批量翻譯,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
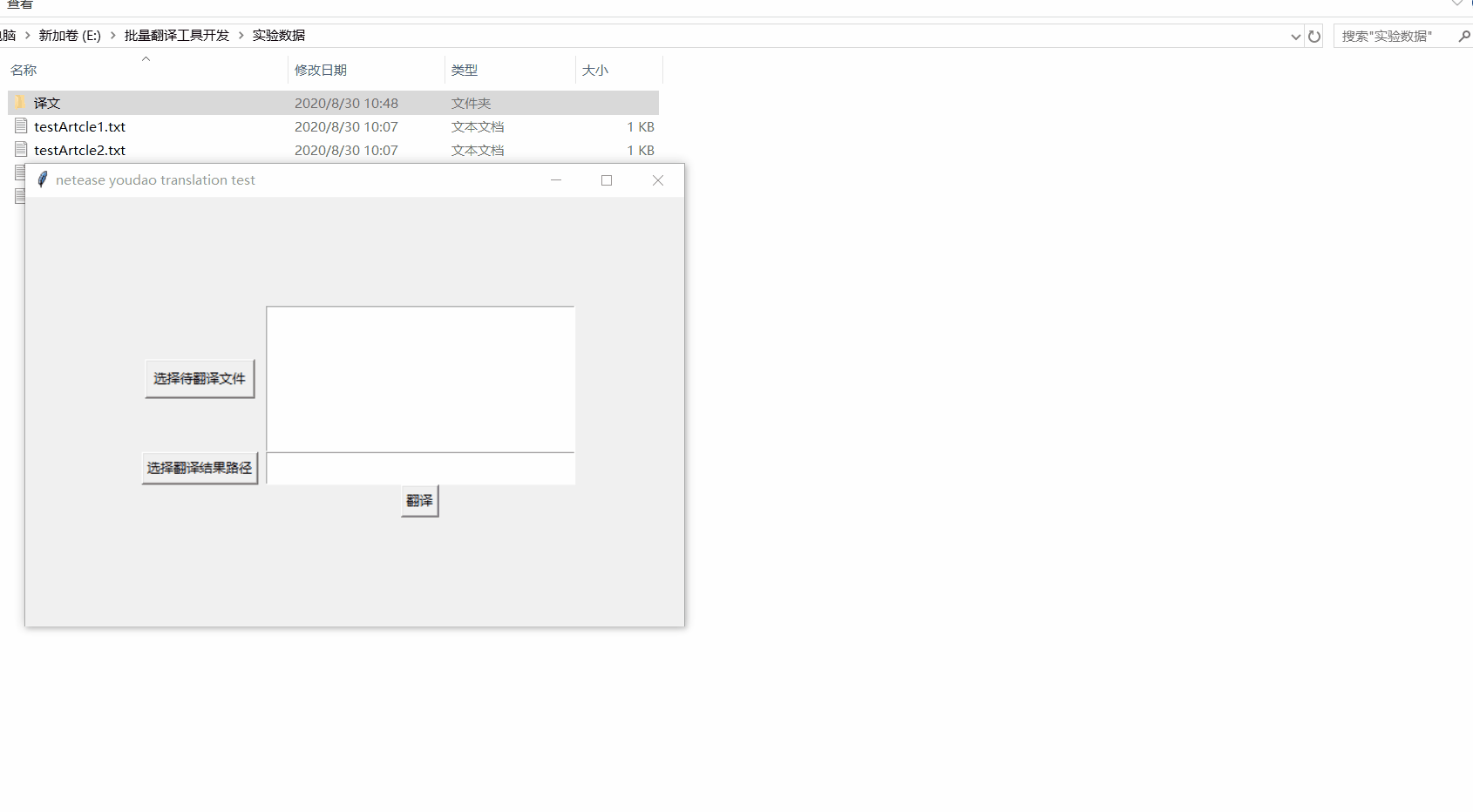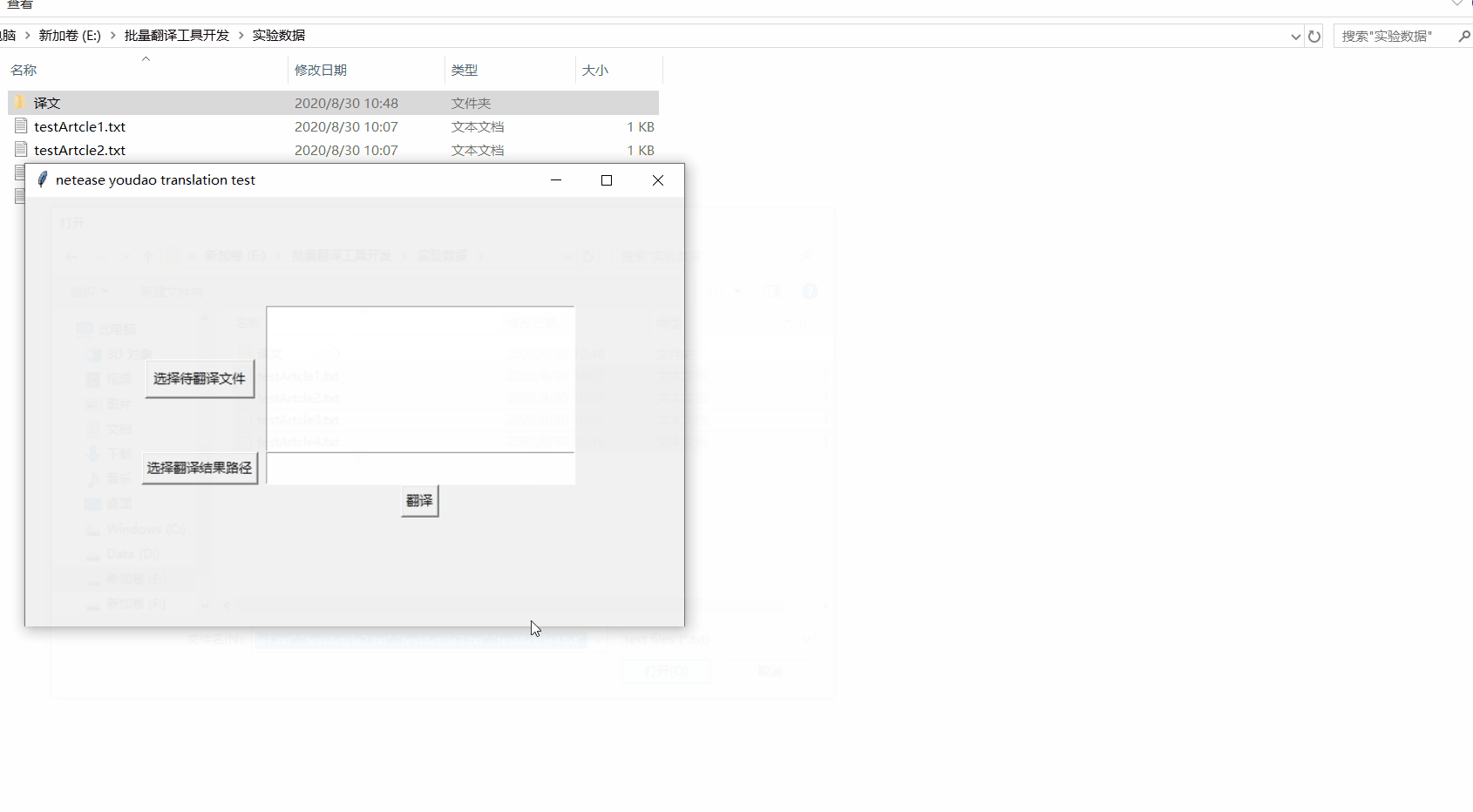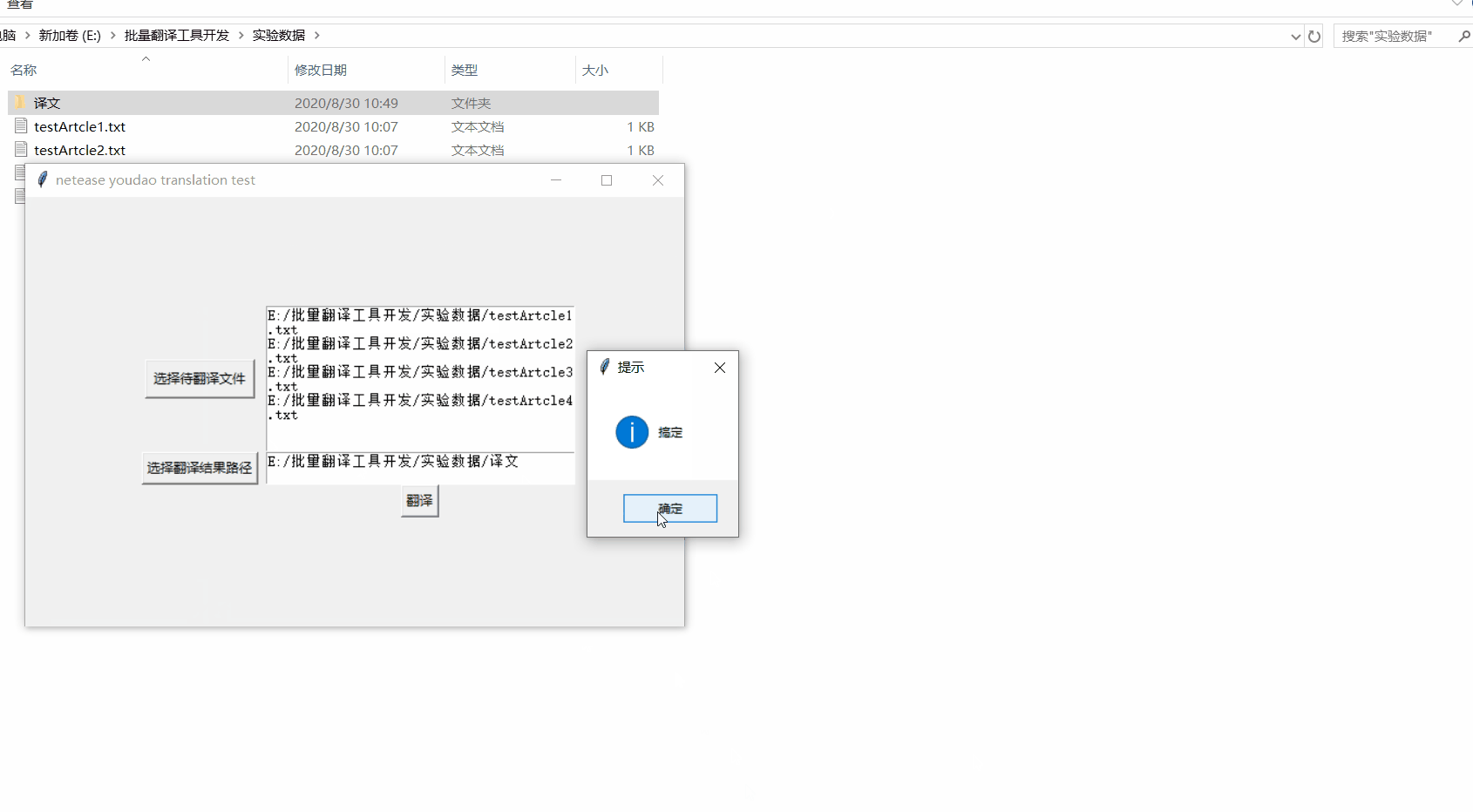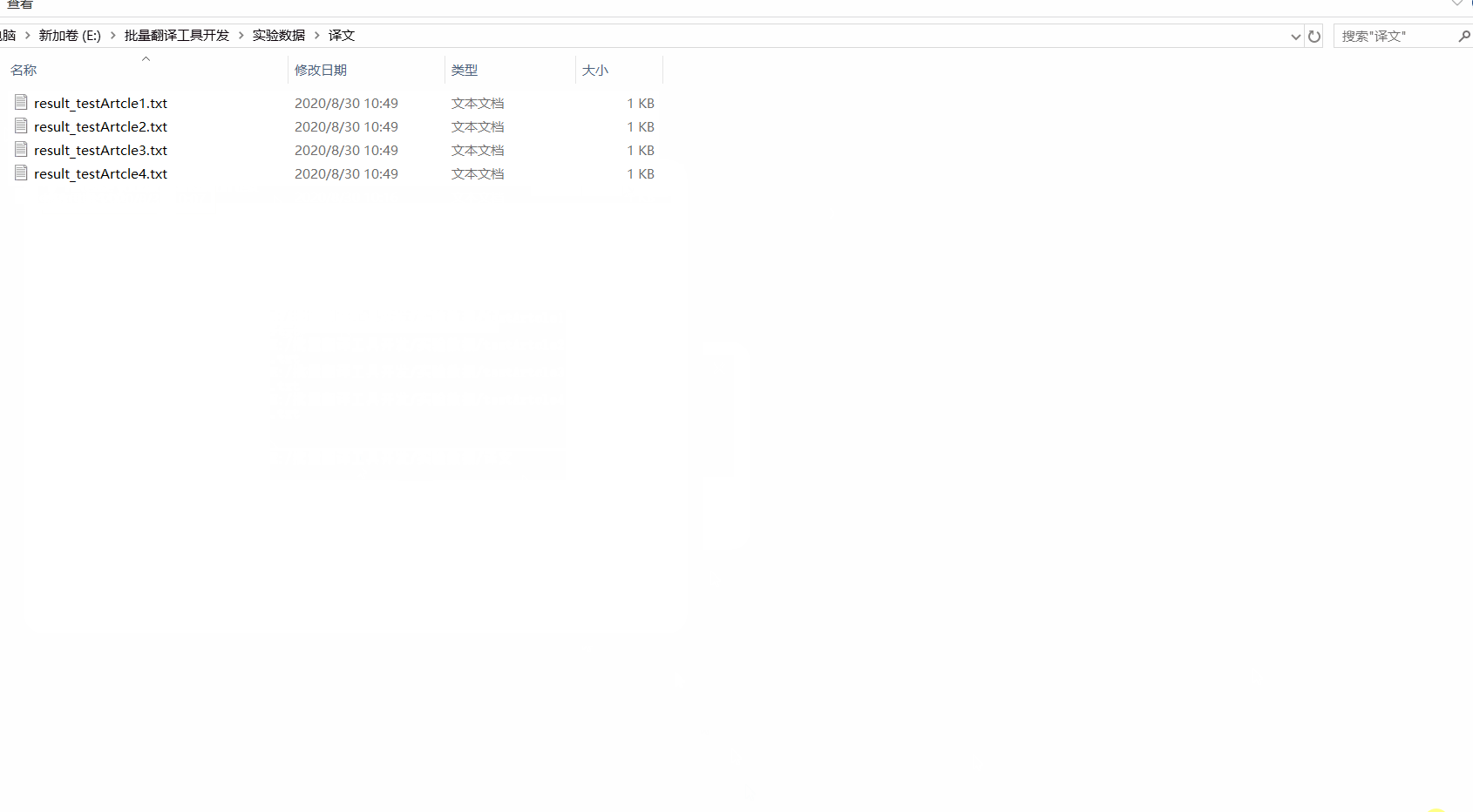
批量文檔翻譯工具的使用
我這里開發批量文檔翻譯工具使用python作為開發工具,功能如下:
     1)通過文件夾選擇多個文檔;
     2)可以將多個文檔的翻譯結果存到目標文件夾下。
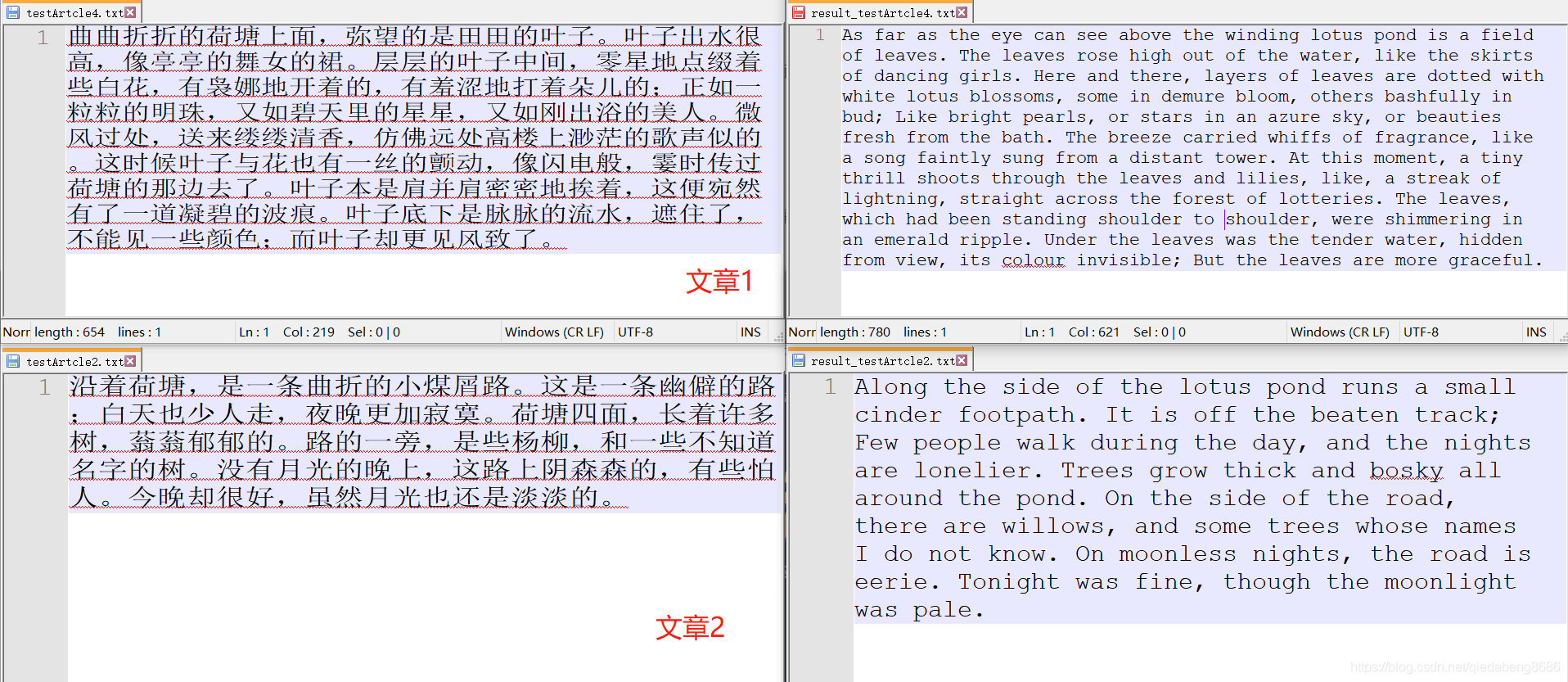
話不多說,看圖↓↓↓↓↓
部分翻譯結果展示(涉及工作內容的保密性,這里用荷塘月色作為樣例):
開發過程
下面開始詳細介紹調用有道智云API接口的步驟和軟件開發的過程:
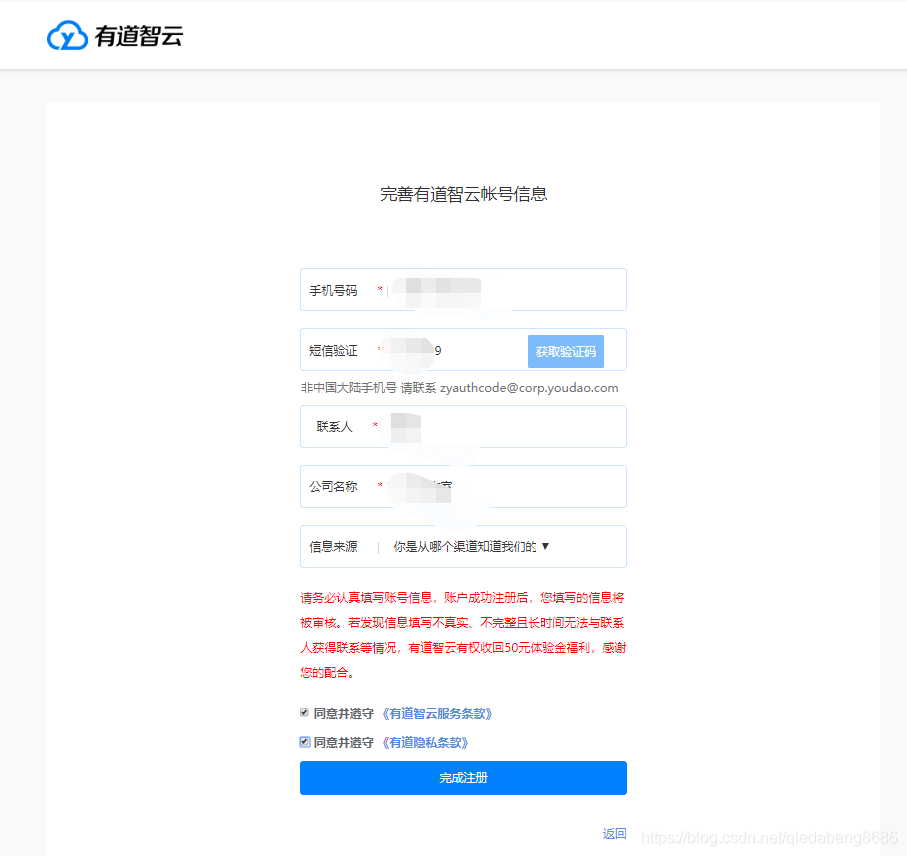
1、個人開發者賬號注冊
首先,需要注冊個人的開發者賬號。
在官網點擊注冊,然后填寫個人資料。即可完成注冊,官網地址:http://ai.youdao.com/gw.s#/
2、 創建應用和實例
注冊成功并登錄后個人中心頁面如下圖,有道智云提供了自然語言翻譯、文字識別、語音合成、語音測評等服務接口。 這些服務接口都是通過以實例的方式運行的,通過應用進行管理的。需要分別創建實例、創建應用,通過應用獲取應用ID和應用密鑰等信息。
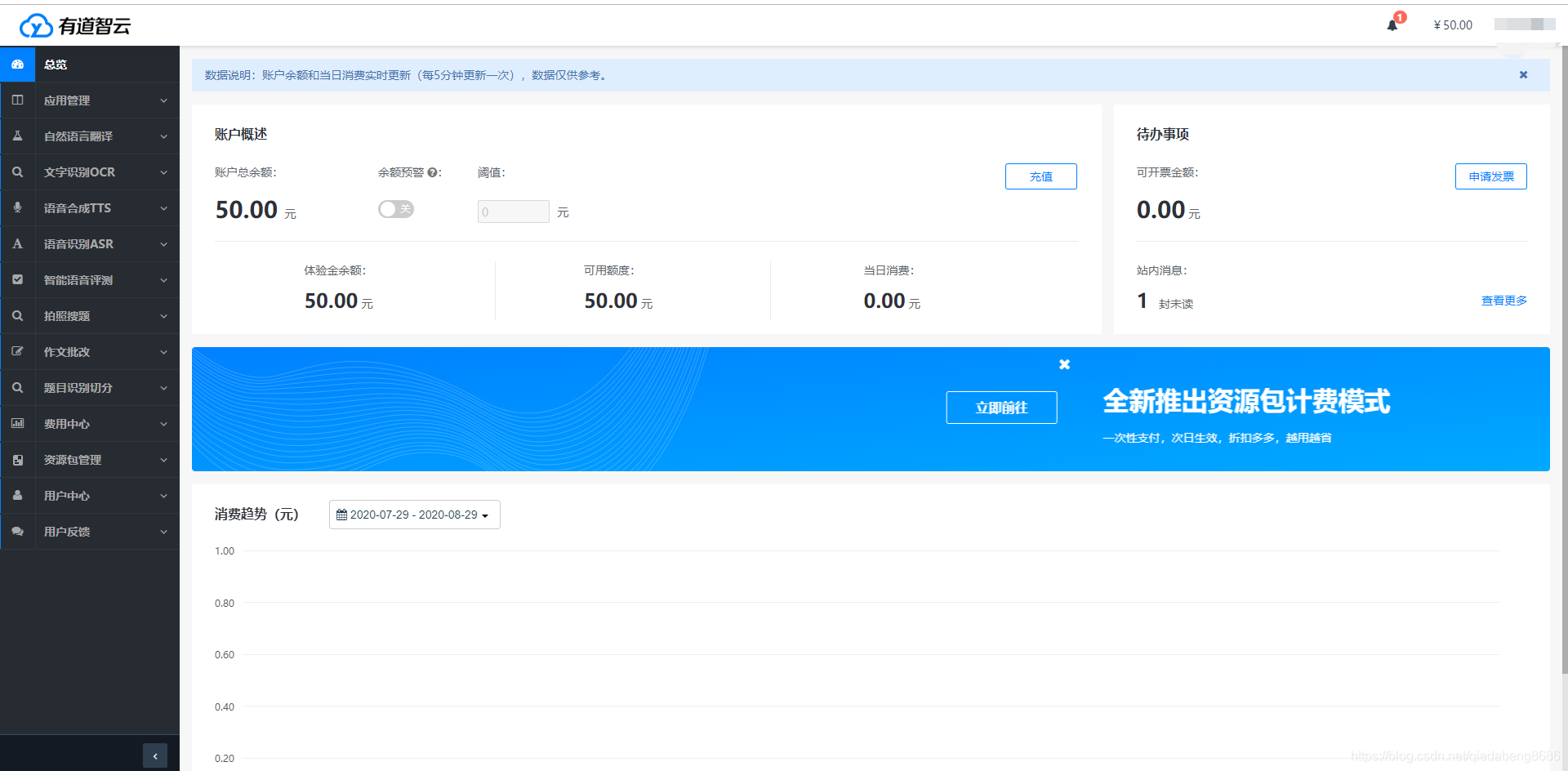
我這里用到的是自然語言翻譯服務,首先,需要分別創建一個應用、創建一個自然語音翻譯的實例;其次,需要將實例綁定到應用上。最后,就可以通過應用的應用ID、應用密鑰調用自然語音翻譯api接口了。有道平臺會對不同的實例、應用的使用情況進行記錄、分析、收費。剛剛注冊的體驗者會有免費體驗字數和50元的體驗金哦(加客服貌似還會有額外的50元的)。
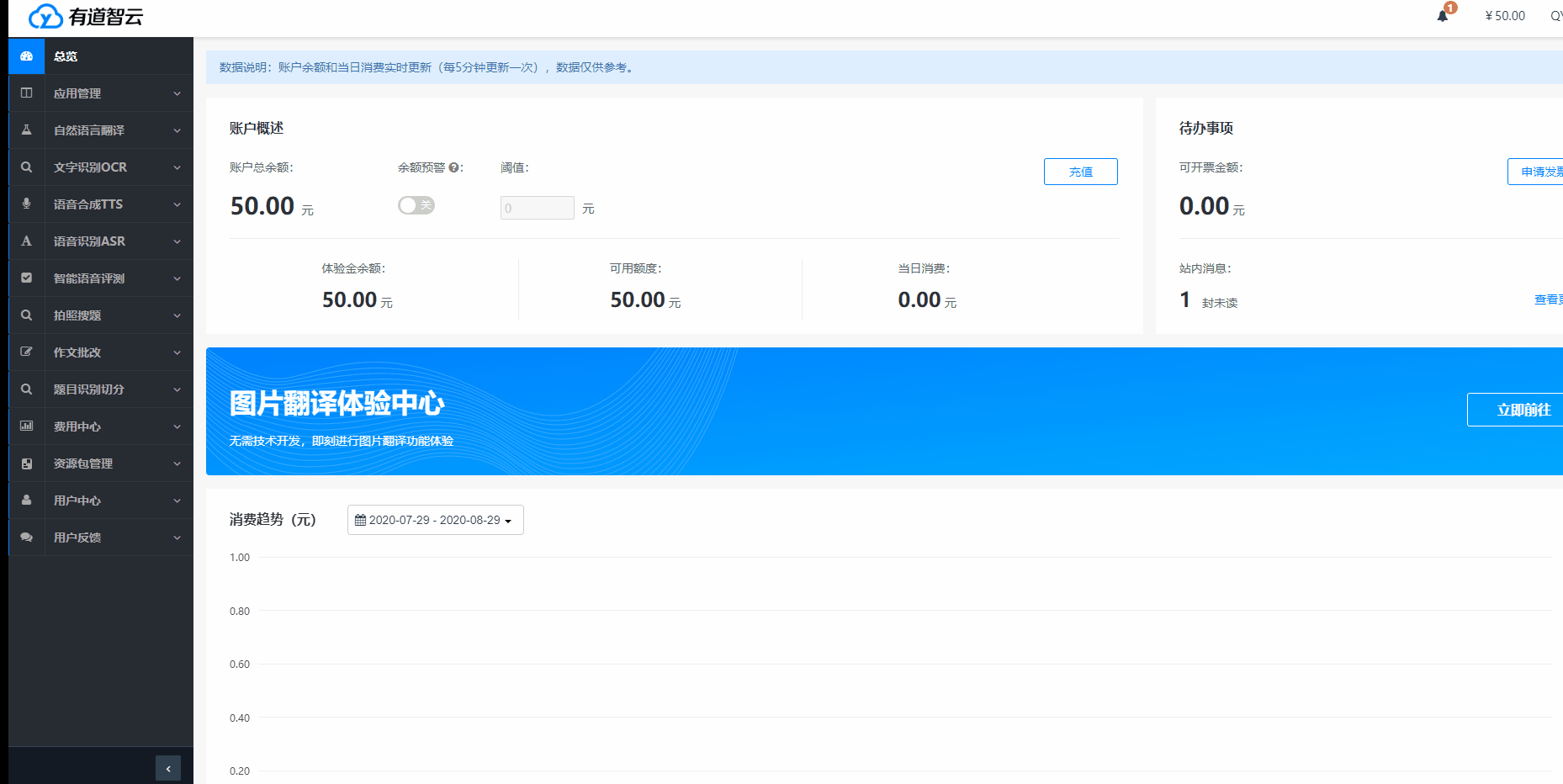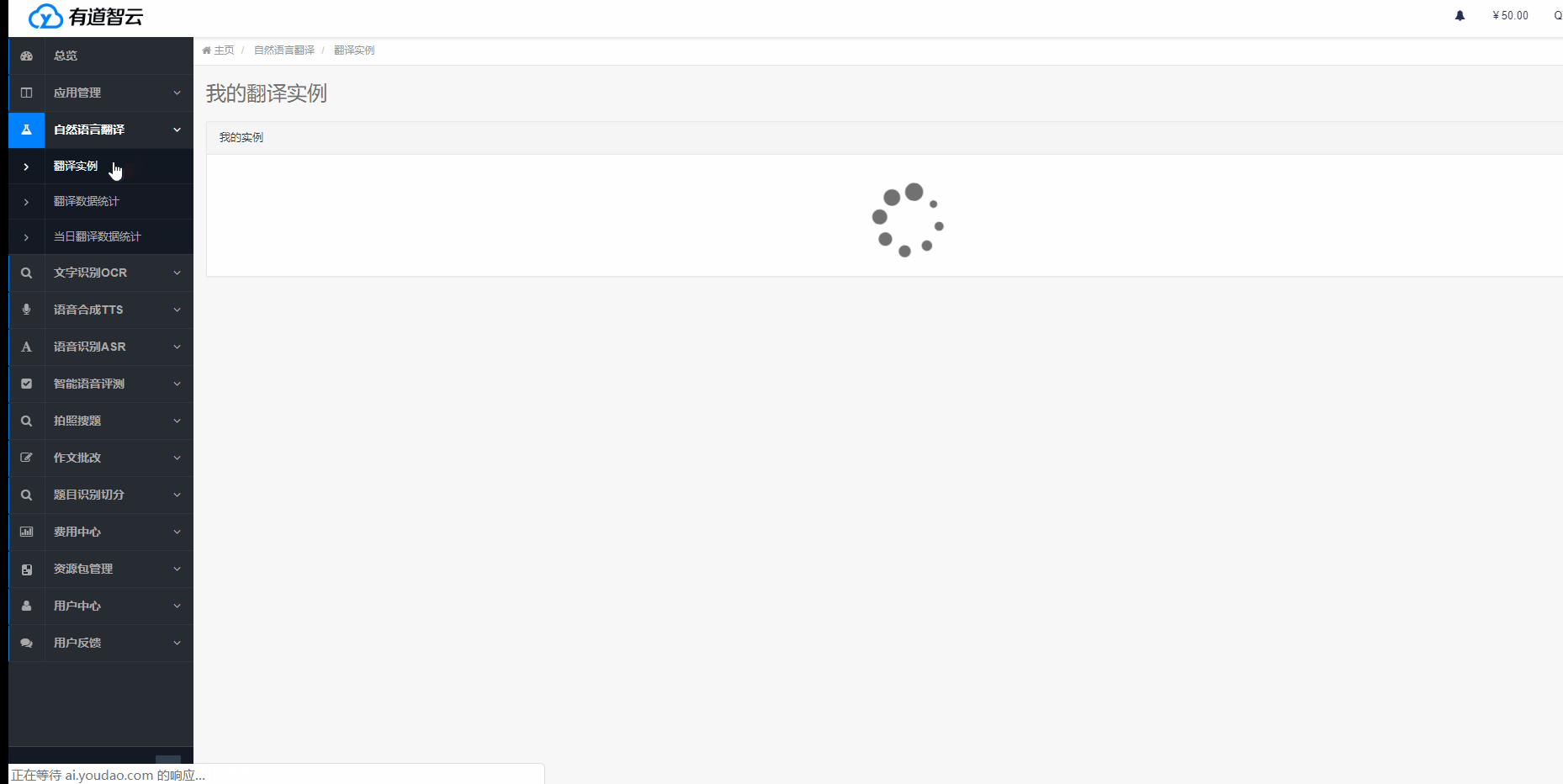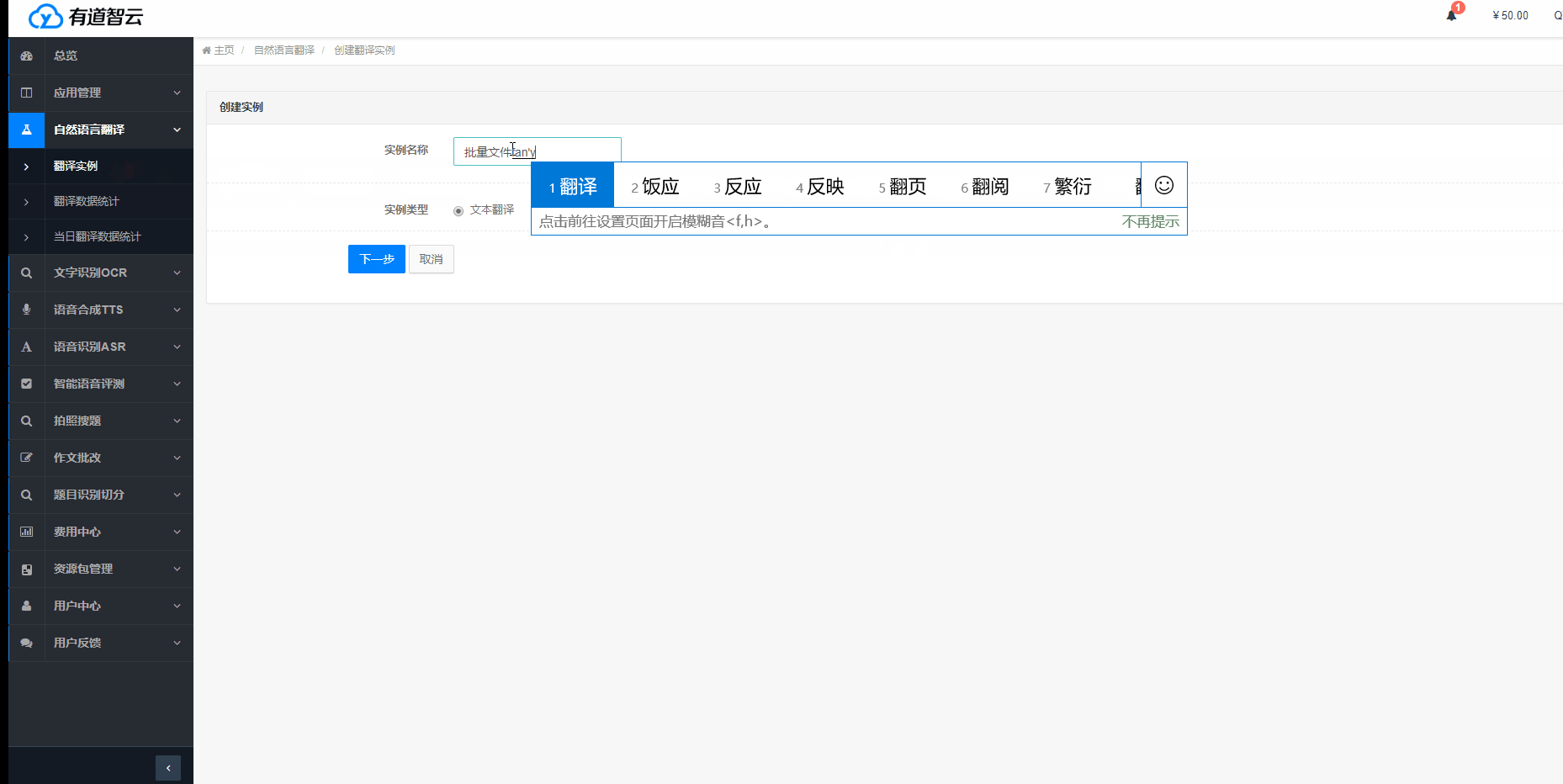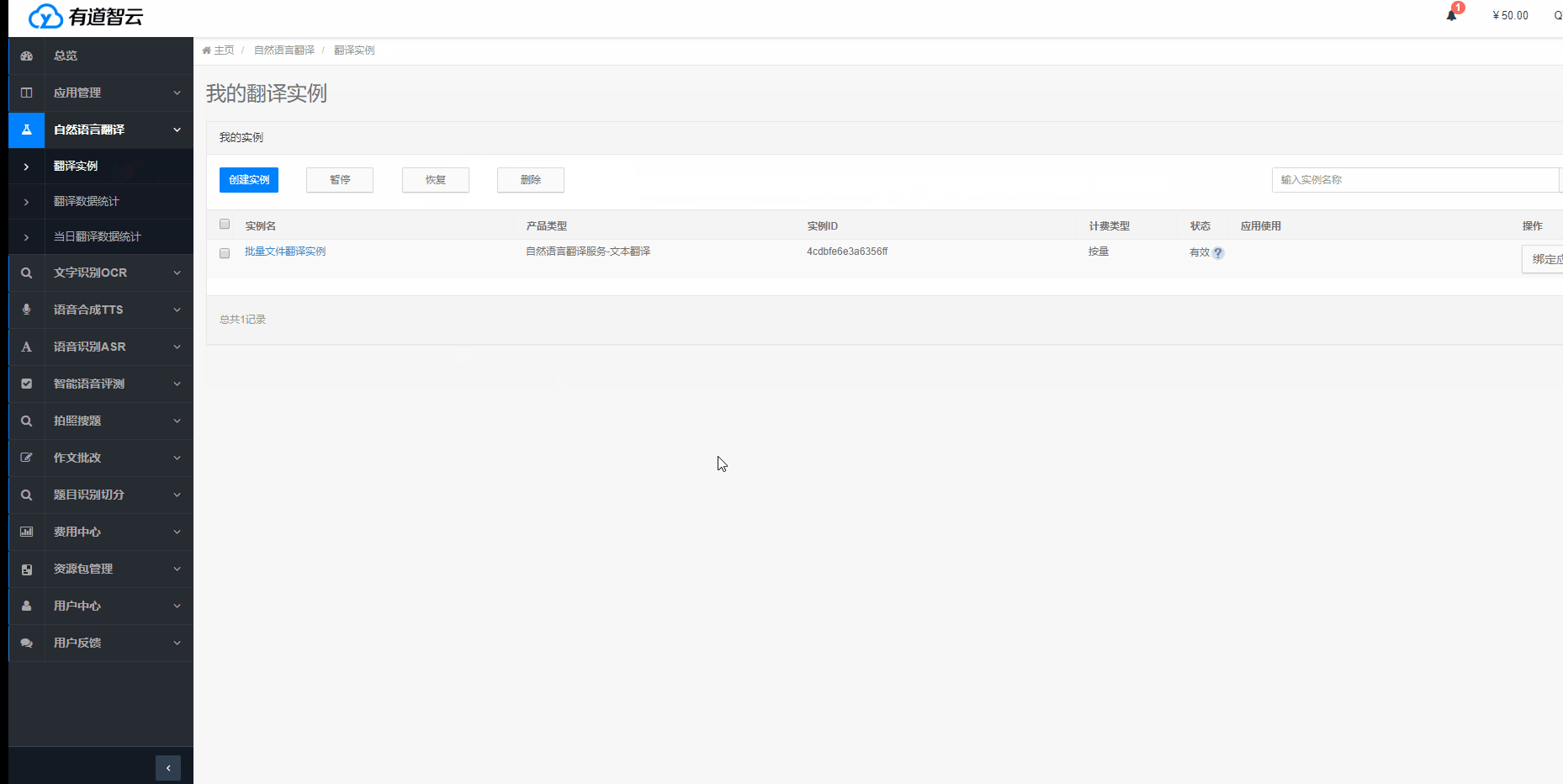
創建實例的步驟:
根據使用需求,選擇對應服務(“自然語言翻譯”/“文字識別OCR”/“語音合成TTS”/“語音識別ASR”/“智能語音評測”/“多平臺編輯器”)->“創建實例”,按步驟完成實例創建。
創建應用并綁定實例(應用接口分為三種:API、安卓、ios接口):
點擊“應用管理”->“我的應用”->“創建應用”,填寫應用名稱等相關信息,選擇接入方式,并綁定我們所創建的實例,完成應用創建。我們這里用到的是API方式接入,安卓、ios接口需要根據提示填寫相應的信息,詳見官網新手指南。
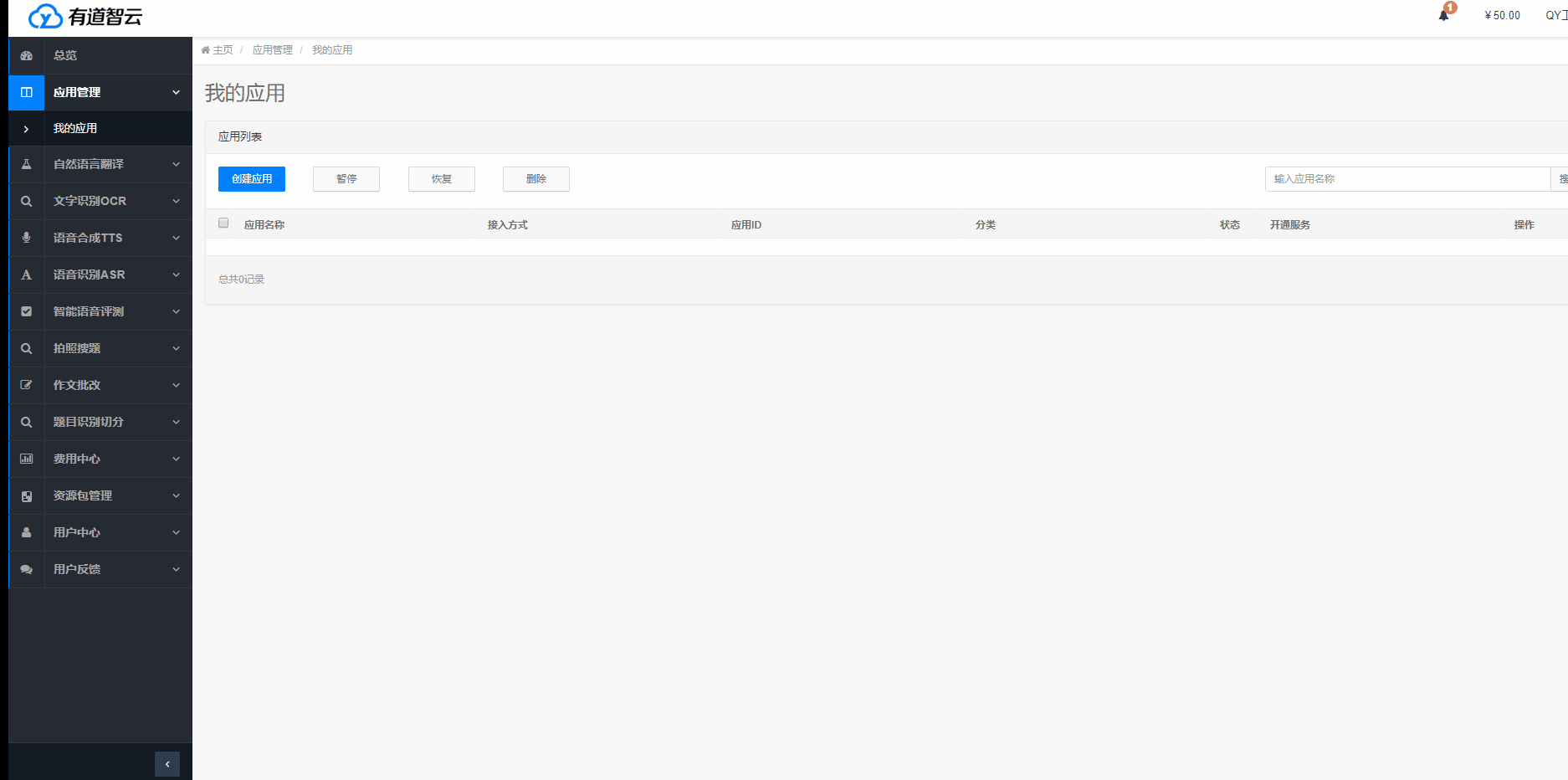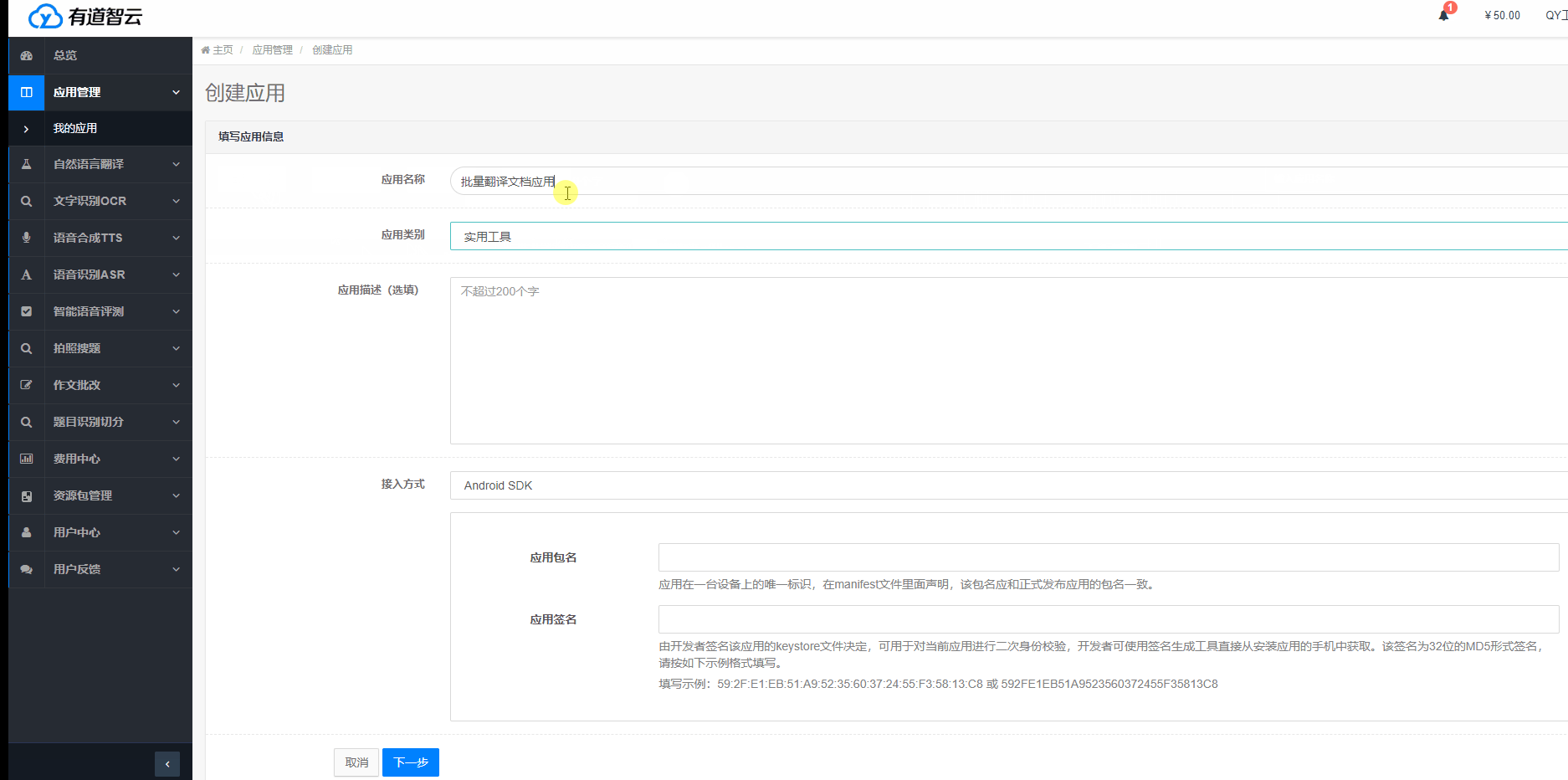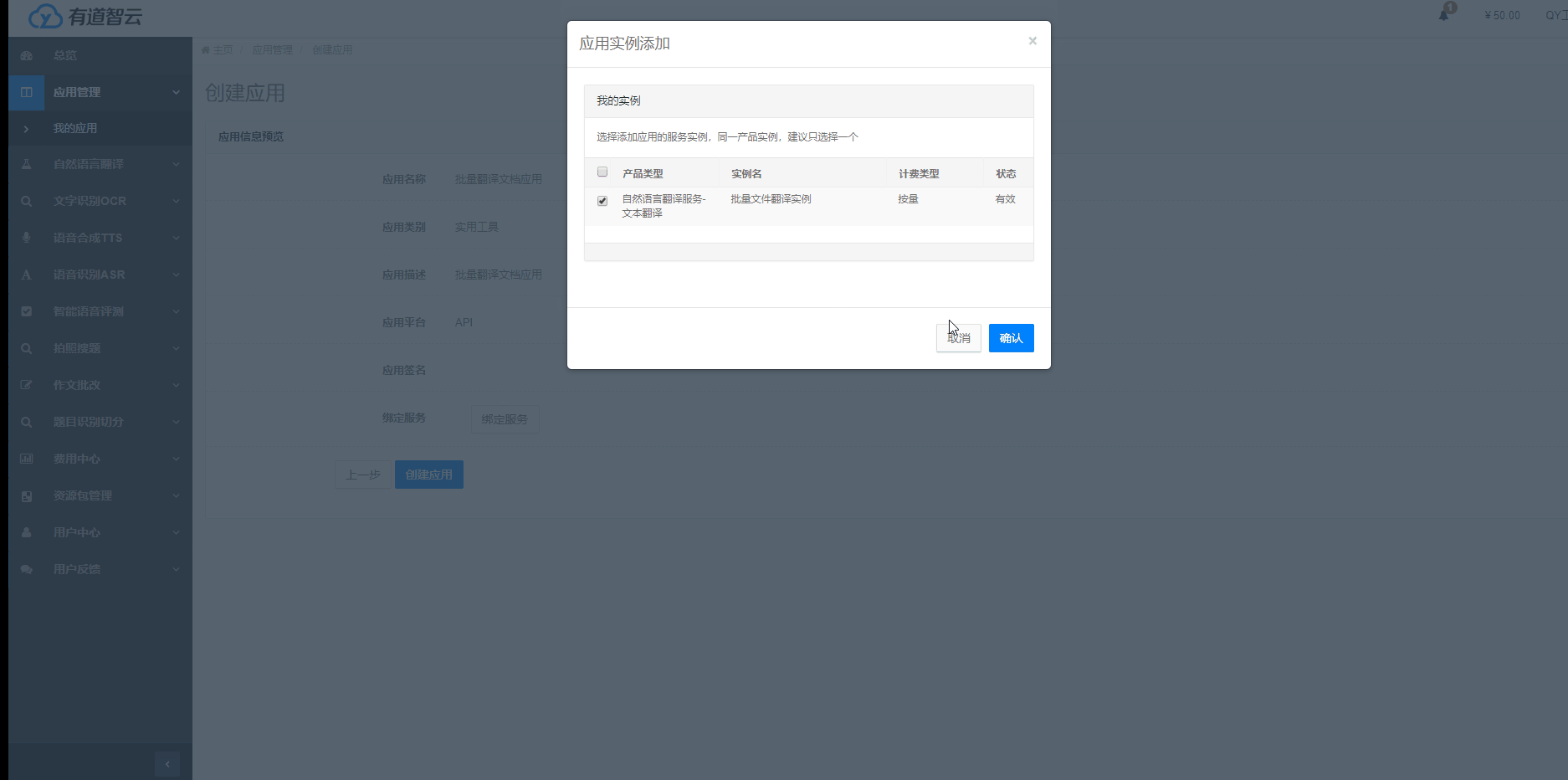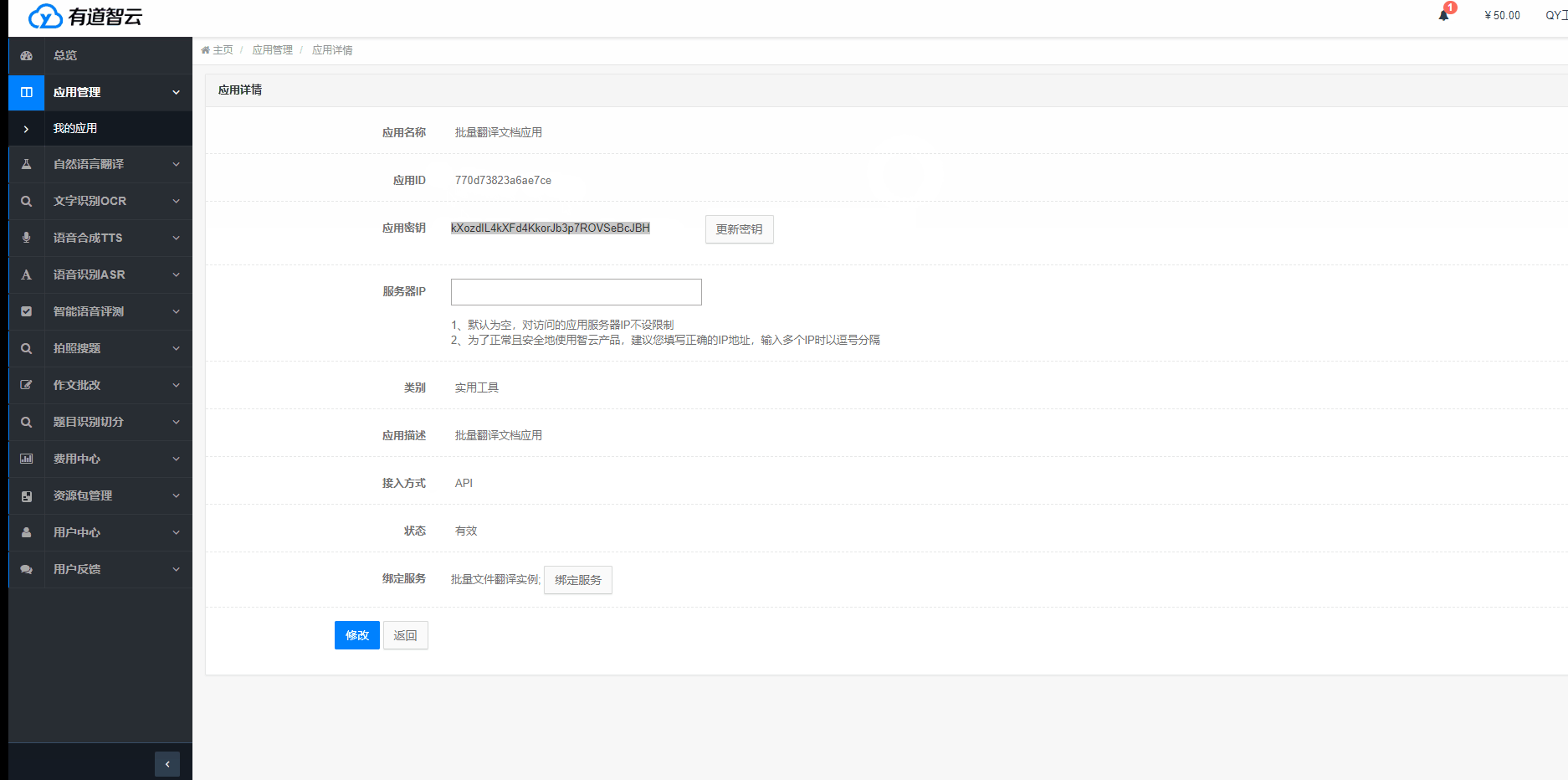
應用創建成功后,可獲取應用ID(appKey)和應用密鑰等信息,這些信息是調用API接口必不可少的參數。
3、接口調用及代碼實現
1)API接口介紹
下面介紹API接口的調用方法
文本翻譯API HTTPS地址:https://openapi.youdao.com/api
調用規則:在調用集成文本翻譯API時,需遵循以下規則。
| 規則 | 描述 |
|---|---|
| 傳輸方式 | HTTPS |
| 請求方式 | GET/POST |
| 字符編碼 | 統一使用UTF-8 編碼 |
| 請求格式 | 表單 |
| 響應格式 | JSON |
調用傳參:調用API需要向接口發送以下字段來訪問服務。
| 字段名 | 類型 | 含義 | 必填 | 備注 |
|---|---|---|---|---|
| q | text | 待翻譯文本 | True | 必須是UTF-8編碼 |
| from | text | 源語言 | True | 參考下方 支持語言 (可設置為auto) |
| to | text | 目標語言 | True | 參考下方 支持語言 (可設置為auto) |
| appKey | text | 應用ID | True | 可在 應用管理 查看 |
| salt | text | UUID | True | UUID |
| sign | text | 簽名 | True | sha256(應用ID+input+salt+curtime+應用密鑰) |
| signType | text | 簽名類型 | True | v3 |
| curtime | text | 當前UTC時間戳(秒) | true | TimeStamp |
| ext | text | 翻譯結果音頻格式,支持mp3 | false | mp3 |
| voice | text | 翻譯結果發音選擇 | false | 0為女聲,1為男聲。默認為女聲 |
| strict | text | 是否嚴格按照指定from和to進行翻譯:true/false | false | 如果為false,則會自動中譯英,英譯中。默認為false |
簽名生成方法如下:
signType=v3;
sign=sha256(應用ID+input+salt+curtime+應用密鑰);
其中,input的計算方式為:input=q前10個字符+q長度+q后10個字符(當q長度大于20)或input=q字符串(當q長度小于等于20);
返回結果格式:返回的結果是json格式,具體說明如下:
| 字段名 | 類型 | 含義 | 備注 |
|---|---|---|---|
| errorCode | text | 錯誤返回碼 | 一定存在 |
| query | text | 源語言 | 查詢正確時,一定存在 |
| translation | Array | 翻譯結果 | 查詢正確時,一定存在 |
| basic | text | 詞義 | 基本詞典,查詞時才有 |
| web | Array | 詞義 | 網絡釋義,該結果不一定存在 |
| l | text | 源語言和目標語言 | 一定存在 |
| dict | text | 詞典deeplink | 查詢語種為支持語言時,存在 |
| webdict | text | webdeeplink | 查詢語種為支持語言時,存在 |
| tSpeakUrl | text | 翻譯結果發音地址 | 翻譯成功一定存在,需要應用綁定語音合成實例才能正常播放 否則返回110錯誤碼 |
| speakUrl | text | 源語言發音地址 | 翻譯成功一定存在,需要應用綁定語音合成實例才能正常播放 否則返回110錯誤碼 |
| returnPhrase | Array | 單詞校驗后的結果 | 主要校驗字母大小寫、單詞前含符號、中文簡繁體 |
當返回的結果errorCode為 0 時說明調用成功,不為0時,則會出現不同含義的錯誤碼。詳細含義可查閱官方開發文檔。
2)批量文檔翻譯開發
批量翻譯demo使用python3實現,為了方便測試,我用tkinter做了簡單的界面,用來讀取待翻譯文檔,指定結果存儲路徑,為了最大化簡化開發過程,降低測試的時間成本,目前只實現了讀取.txt類型文件的方法。
整個demo分為三個文件,mainwindow.py,translate.py和translatetool.py,mainwindow為UI部分的代碼,translate中實現了批量讀取文檔并翻譯保存的邏輯,translatetool為根據示例代碼改造后的翻譯方法,需調用其他平臺API時,亦可封裝相應方法,增加了項目的擴展性。
mainwindow的元素如下:
root=tk.Tk()
root.title("netease youdao translation test")
frm = tk.Frame(root)
frm.grid(padx='50', pady='50')
btn_get_file = tk.Button(frm, text='選擇待翻譯文件', command=get_files)
btn_get_file.grid(row=0, column=0, ipadx='3', ipady='3', padx='10', pady='20')
text1 = tk.Text(frm, width='40', height='10')
text1.grid(row=0, column=1)
btn_get_result_path=tk.Button(frm,text='選擇翻譯結果路徑',command=set_result_path)
btn_get_result_path.grid(row=1,column=0)
text2=tk.Text(frm,width='40', height='2')
text2.grid(row=1,column=1)
btn_sure=tk.Button(frm,text="翻譯",command=translate_files)
btn_sure.grid(row=2,column=1)其中translate_files()方法最終調用了translate類的translate_files()方法:
def translate_files():
if translate.file_paths:
translate.translate_files()
tk.messagebox.showinfo("提示","搞定")
else :
tk.messagebox.showinfo("提示","無文件")類translate定義如下:
import os
from translatetool import connect
class Translate():
def __init__(self,name,file_paths,result_root_path,trans_type):
self.name=name
self.file_paths=file_paths # 待翻譯文件路徑
self.result_root_path=result_root_path # 翻譯結果存儲路徑
self.trans_type=trans_type
# 翻譯過程:讀取文件-掉用有道api-解析返回信息-保存
def translate_files(self):
for file_path in self.file_paths:
file_name=os.path.basename(file_path)
file_content=open(file_path,encoding='utf-8').read()
trans_reult=self.translate_use_netease(file_content)
resul_file=open(self.result_root_path+'/result_'+file_name,'w').write(trans_reult)
def translate_use_netease(self,file_content):
result=','.join(connect(file_content,'zh-CH','EN')) # 翻譯API返回結果為一個數組
return result調用有道API主要方法為connect(),根據API的簽名信息等要求組成data并發送請求,解析返回的json:
# input輸入待翻譯字段,fromlanguage待翻譯的語言,tolanguage翻譯成的目標語言
# 返回翻譯的字段
def connect(inputtext,fromlanguage,tolanguage):
q=inputtext
data = {}
data['from'] = fromlang
data['to'] = tolang
data['signType'] = 'v3'
curtime = str(int(time.time()))
data['curtime'] = curtime
salt = str(uuid.uuid1())
signStr = APP_KEY + truncate(q) + salt + curtime + APP_SECRET
sign = encrypt(signStr)
data['appKey'] = APP_KEY
data['q'] = q
data['salt'] = salt
data['sign'] = sign
print(data)
response = do_request(data)
print(response.content)
j = json.loads(str(response.content, encoding="utf-8"))["translation"]
return j完整demo代碼地址:https://github.com/LemonQH/BatchFileTraslationProgram/tree/master
得益于API的學習成本之低,接口調用部分的開發過程十分順利,僅有一個小插曲,最開始調用API總是返回錯誤碼206(即時間戳錯誤),最后發現是我的系統時間比標準時間慢了十分鐘 - - #
總結
對于我此次的需要翻譯的文檔需求來說,有道智云贈送的字數和賬戶額度,已經夠用了,但是如果想長期的使用下去,還是要付費的。最后發現,有道智云在個人主頁中還提供了按小時統計當日實例調用次數和查詢字符數和按天統計歷史天數內實例的調用次數和字符數,對有需求的小伙伴,還可以記錄查看自己接口的翻譯量、實時調用量等狀態。
如上是我整個demo的開發過程。整體來說從注冊到調用有道智云API的過程還是比較順利的,而且每一步都有官方的詳細文檔可以參照。以至于主要開發時間都分配給了tkinter排版(順便吐槽下tkinter的“好用” :p)。
上述就是小編為大家分享的python如何實現調用有道智云API實現文件并批量翻譯了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





