溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了MySQL中 btree索引與hash索引的區別,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
在MySQL中,大多數索引(如 PRIMARY KEY,UNIQUE,INDEX和FULLTEXT)都是在BTREE中存儲,但使用memory引擎可以選擇BTREE索引或者HASH索引,兩種不同類型的索引各自有其不同的使用范圍。
顯然,如果值的差異性大,并且以等值查找(=、 <、>、in)為主,Hash索引是更高效的選擇,它有O(1)的查找復雜度。
如果值的差異性相對較差,并且以范圍查找為主,B樹是更好的選擇,它支持范圍查找。
一、HASH索引
利用哈希函數,計算存儲地址,檢索時不需要像Btree那樣,從根節點開始遍歷,逐級查找。
Hash 索引結構的特殊性,其檢索效率非常高,索引的檢索可以一次定位,不像B-Tree 索引需要從根節點到枝節點,最后才能訪問到頁節點這樣多次的IO訪問,所以 Hash 索引的查詢效率要遠高于 B-Tree 索引。
可能很多人又有疑問了,既然 Hash 索引的效率要比 B-Tree 高很多,為什么大家不都用 Hash 索引而還要使用 B-Tree 索引呢?任何事物都是有兩面性的,Hash 索引也一樣,雖然 Hash 索引效率高,但是 Hash 索引本身由于其特殊性也帶來了很多限制和弊端,主要有以下這些。
(1)Hash 索引僅僅能滿足”=”,”IN”和”<=>”查詢,不能使用范圍查詢(查詢范圍時 慢)。
由于 Hash 索引比較的是進行 Hash 運算之后的 Hash 值,所以它只能用于等值的過濾,不能用于基于范圍的過濾,因為經過相應的 Hash 算法處理之后的 Hash 值的大小關系,并不能保證和Hash運算前完全一樣。
(2)Hash 索引無法被用來避免數據的排序操作。
由于 Hash 索引中存放的是經過 Hash 計算之后的 Hash 值,而且Hash值的大小關系并不一定和 Hash 運算前的鍵值完全一樣,所以數據庫無法利用索引的數據來避免任何排序運算;
(3)Hash 索引不能利用部分索引鍵查詢。
對于組合索引,Hash 索引在計算 Hash 值的時候是組合索引鍵合并后再一起計算 Hash 值,而不是單獨計算 Hash 值,所以通過組合索引的前面一個或幾個索引鍵進行查詢的時候,Hash 索引也無法被利用。
(4)Hash 索引在任何時候都不能避免表掃描。
前面已經知道,Hash 索引是將索引鍵通過 Hash 運算之后,將 Hash運算結果的 Hash 值和所對應的行指針信息存放于一個 Hash 表中,由于不同索引鍵存在相同 Hash 值,所以即使取滿足某個 Hash 鍵值的數據的記錄條數,也無法從 Hash 索引中直接完成查詢,還是要通過訪問表中的實際數據進行相應的比較,并得到相應的結果。
(5)Hash 索引遇到大量Hash值相等的情況后性能并不一定就會比B-Tree索引高。
對于選擇性比較低的索引鍵,如果創建 Hash 索引,那么將會存在大量記錄指針信息存于同一個 Hash 值相關聯。這樣要定位某一條記錄時就會非常麻煩,會浪費多次表數據的訪問,而造成整體性能低下。
二、B+樹
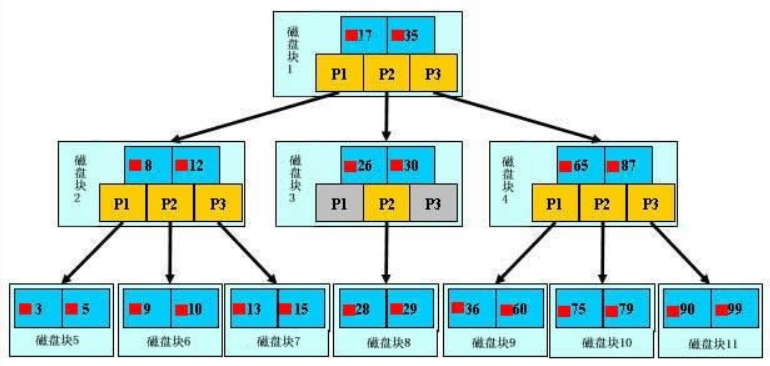
如圖所示,如果要查找數據項29,那么首先會把磁盤塊1由磁盤加載到內存,此時發生一次IO,在內存中用二分查找確定29在17和35之間,鎖定磁盤塊1的P2指針,內存時間因為非常短(相比磁盤的IO)可以忽略不計,通過磁盤塊1的P2指針的磁盤地址把磁盤塊3由磁盤加載到內存,發生第二次IO,29在26和30之間,鎖定磁盤塊3的P2指針,通過指針加載磁盤塊8到內存,發生第三次IO,同時內存中做二分查找找到29,結束查詢,總計三次IO。真實的情況是,3層的b+樹可以表示上百萬的數據,如果上百萬的數據查找只需要三次IO,性能提高將是巨大的,如果沒有索引,每個數據項都要發生一次IO,那么總共需要百萬次的IO,顯然成本非常非常高。
1.索引字段要盡量的小:
通過上面的分析,我們知道IO次數取決于b+數的高度h,假設當前數據表的數據為N,每個磁盤塊的數據項的數量是m,則有h=㏒(m+1)N,當數據量N一定的情況下,m越大,h越小;而m = 磁盤塊的大小 / 數據項的大小,磁盤塊的大小也就是一個數據頁的大小,是固定的,如果數據項占的空間越小,數據項的數量越多,樹的高度越低。這就是為什么每個數據項,即索引字段要盡量的小,比如int占4字節,要比bigint8字節少一半。這也是為什么b+樹要求把真實的數據放到葉子節點而不是內層節點,一旦放到內層節點,磁盤塊的數據項會大幅度下降,導致樹增高。當數據項等于1時將會退化成線性表。
2.索引的最左匹配特性(即從左往右匹配):
當b+樹的數據項是復合的數據結構,比如(name,age,sex)的時候,b+數是按照從左到右的順序來建立搜索樹的,比如當(張三,20,F)這樣的數據來檢索的時候,b+樹會優先比較name來確定下一步的所搜方向,如果name相同再依次比較age和sex,最后得到檢索的數據;但當(20,F)這樣的沒有name的數據來的時候,b+樹就不知道下一步該查哪個節點,因為建立搜索樹的時候name就是第一個比較因子,必須要先根據name來搜索才能知道下一步去哪里查詢。比如當(張三,F)這樣的數據來檢索時,b+樹可以用name來指定搜索方向,但下一個字段age的缺失,所以只能把名字等于張三的數據都找到,然后再匹配性別是F的數據了, 這個是非常重要的性質,即索引的最左匹配特性。
上述內容就是MySQL中 btree索引與hash索引的區別,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





