溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何使用pycharm實現連接Databricks?針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
在本地使用pycharm連接databricks,大致步驟如下:
首先,為了讓本地環境能夠識別遠端的databricks集群環境,需要收集databricks的基本信息和自己databricks的token,這些信息能夠讓本地環境識別databricks;接著,需要使用到工具 anaconda創建一個虛擬環境,連接databricks;最后,將虛擬環境導入pycharm。
(下面的圖渣渣,因為直接拖進來的)
第0步:檢查
檢查java版本,需要時1.8開頭的版本,如果不是,請到這里下載:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html

第1步:收集databricks的信息
查看python版本 (還不知道怎么看,這里cluster的python版本為3.7)
查看Runtime Version
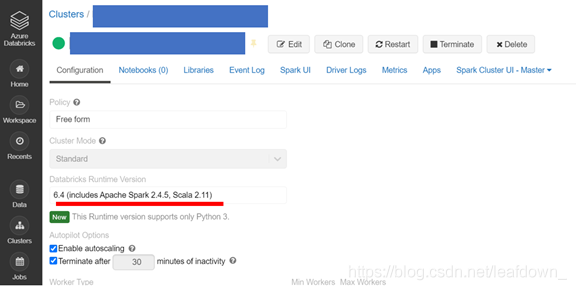
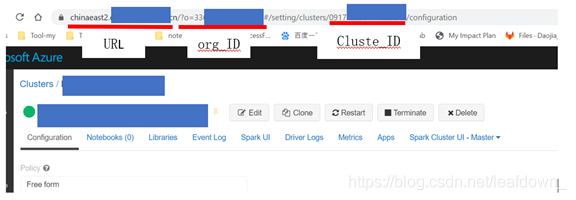
查看cluster ulr,解析出下面信息
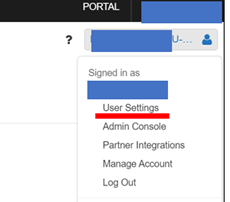
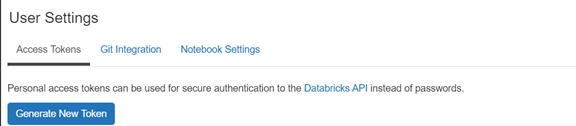
生成token,點擊這個小人-user setting
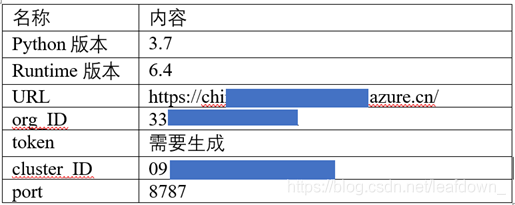
最后,這是我們收集到的所有信息
第2步:安裝anaconda
如果已經安裝anaconda,請略過這一步
沒有安裝,可以看這個教程
https://www.jb51.net/article/196286.htm
第3步:使用anaconda創建虛擬環境
下面的參數信息,使用第一步收集的信息
打開anaconda的命令行
創建一個3.7版本的虛擬隔離環境
conda create -n dbconnect python=3.7

使用環境
conda activate dbconnect

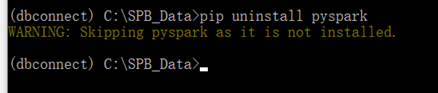
卸載pyspark,如果是新創建的環境,可以不用執行這步(這是為了確保,創建的環境不能有pyspark的包,因為會產生包的問題)
pip uninstall pyspark
下面開始安裝包,但是為了讓安裝速度快一些,使用清華鏡像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro/ conda config --set show_channel_urls yes
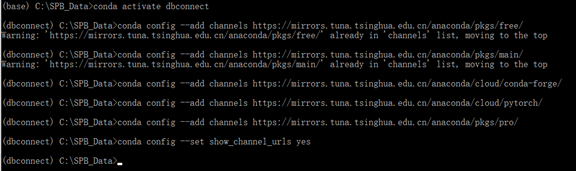
查看是否切換到鏡像
conda config --show channels
可以看到已經切換
安裝connect包,第一步中確定的run的版本為6.4,故選擇6.4.* (用公司的網絡,下載很慢,我用自己的熱點)
pip install -U databricks-connect==6.4.*

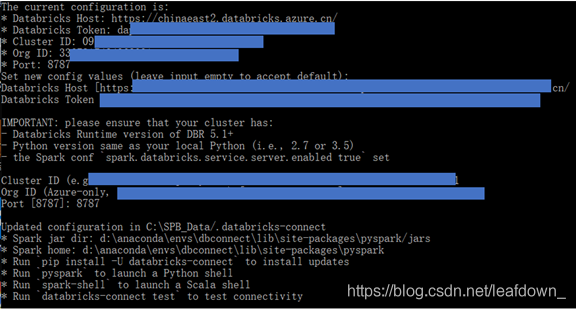
連接遠端databricks,并輸入第一步收集的相關信息
databricks-connect configure
測試是否已經連接上:
databricks-connect test
已經在啟動節點了

查看databricks,可以看到

第4步:pycharm導入虛擬環境
打開pycahrm,點擊setting
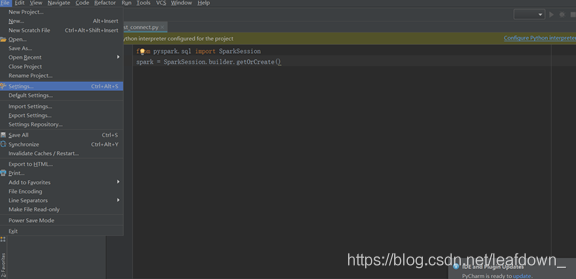
選擇解釋器,點擊小齒輪的add'
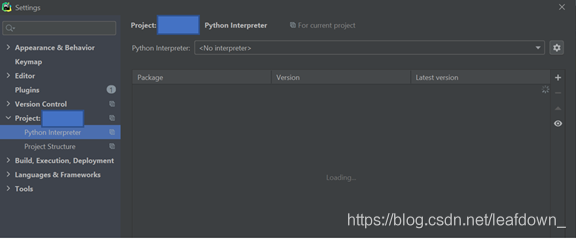
選擇剛才我們創建好的dbconnect

點擊ok,可以看到已經選好了環境
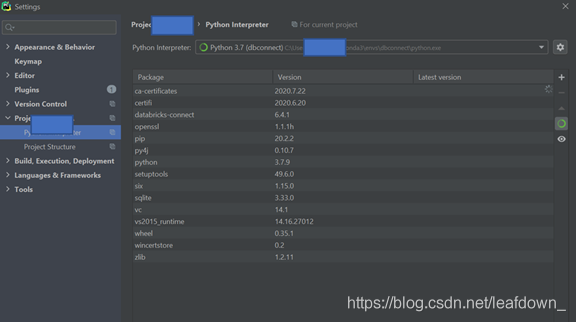
不知道為啥連接不到遠端的包,我的項目還需要在本地安裝一些用的包
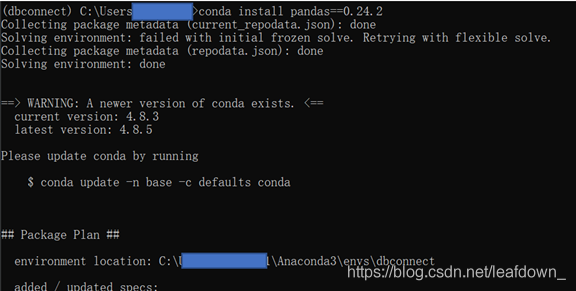
conda install scikit-learn==0.22.1 conda install pandas==0.24.2 conda install pyarrow==0.15.1
在pycharm測試運行一下:
import pandas as pd import numpy as np # Generate a pandas DataFrame pdf = pd.DataFrame(np.random.rand(100, 3)) from pyspark.sql import * spark = SparkSession.builder.getOrCreate() df = spark.createDataFrame(pdf) print(df.head(5))
去databrick的cluster log看一下,已經啟動了節點,正在運行

關于如何使用pycharm實現連接Databricks問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





