溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python extract及contains的使用方法?很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
一,extract方法的使用
extract函數主要是對于數據進行提取。場景一般對于DataFrame中的一列中的數據進行提取的場合比較多。
例如一列中包含了很長的字段,我們希望在這些字段中提取出我們想要的字段時,就可以通過extract方法進行數據的提取了。
好了,廢話不多說直接上代碼。
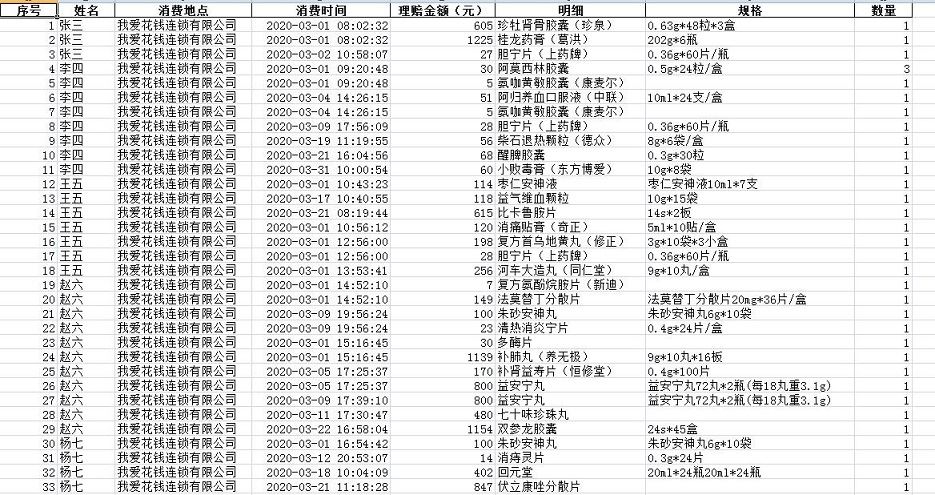
數據源
序號 姓名 服務卡卡號 消費地點 消費時間 理賠金額(元) 交易明細 數量 1 張三 8100001 我愛花錢連鎖有限公司 2020/3/1 8:02 605 珍牡腎骨膠囊(珍泉)0.63g*48粒*3盒 1 2 張三 8100001 我愛花錢連鎖有限公司 2020/3/1 8:02 1225 桂龍藥膏(葛洪)202g*6瓶 1 3 張三 8100001 我愛花錢連鎖有限公司 2020/3/2 10:58 27 膽寧片(上藥牌)0.36g*60片/瓶 1 4 李四 8100002 我愛花錢連鎖有限公司 2020/3/1 9:20 30 阿莫西林膠囊0.5g*24粒/盒 3 5 李四 8100002 我愛花錢連鎖有限公司 2020/3/1 9:20 5 氨咖黃敏膠囊(康麥爾)12粒/盒 1 6 李四 8100002 我愛花錢連鎖有限公司 2020/3/4 14:26 51 阿歸養血口服液(中聯)10ml*24支/盒 1 7 李四 8100002 我愛花錢連鎖有限公司 2020/3/4 14:26 5 氨咖黃敏膠囊(康麥爾)12粒/盒 1 8 李四 8100002 我愛花錢連鎖有限公司 2020/3/9 17:56 28 膽寧片(上藥牌)0.36g*60片/瓶 1 9 李四 8100002 我愛花錢連鎖有限公司 2020/3/19 11:19 56 柴石退熱顆粒(德眾)8g*6袋/盒 1 10 李四 8100002 我愛花錢連鎖有限公司 2020/3/21 16:04 68 醒脾膠囊0.3g*30粒 1 11 李四 8100002 我愛花錢連鎖有限公司 2020/3/31 10:00 60 小敗毒膏(東方博愛)10g*8袋 1 12 王五 8100003 我愛花錢連鎖有限公司 2020/3/1 10:43 114 棗仁安神液10ml*7支 1 13 王五 8100003 我愛花錢連鎖有限公司 2020/3/17 10:40 118 益氣維血顆粒(紅珊瑚)10g*15袋 1 14 王五 8100003 我愛花錢連鎖有限公司 2020/3/21 8:19 615 比卡魯胺片(雙益安)50mg*14s*2板 1 15 王五 8100003 我愛花錢連鎖有限公司 2020/3/1 10:56 120 消痛貼膏(奇正)1.2g:2.5ml*10貼/盒 1 16 王五 8100003 我愛花錢連鎖有限公司 2020/3/1 12:56 198 復方首烏地黃丸(修正)3g*10袋*3小盒 1 17 王五 8100003 我愛花錢連鎖有限公司 2020/3/1 12:56 28 膽寧片(上藥牌)0.36g*60片/瓶 1 18 王五 8100003 我愛花錢連鎖有限公司 2020/3/1 13:53 256 河車大造丸(同仁堂)9g*10丸/盒 1 19 趙六 8100004 我愛花錢連鎖有限公司 2020/3/1 14:52 7 復方氨酚烷胺片(新迪)12片/盒 1 20 趙六 8100004 我愛花錢連鎖有限公司 2020/3/1 14:52 149 法莫替丁分散片20mg*36片/盒 1 21 趙六 8100004 我愛花錢連鎖有限公司 2020/3/9 19:56 100 朱砂安神丸6g*10袋 1 22 趙六 8100004 我愛花錢連鎖有限公司 2020/3/9 19:56 23 清熱消炎寧片0.4g*24片/盒 1 23 趙六 8100004 我愛花錢連鎖有限公司 2020/3/1 15:16 30 多酶片100s/盒 1 24 趙六 8100004 我愛花錢連鎖有限公司 2020/3/1 15:16 1139 補肺丸(養無極)9g*10丸*16板 1 25 趙六 8100004 我愛花錢連鎖有限公司 2020/3/5 17:25 170 補腎益壽片(恒修堂)0.4g*100片 1 26 趙六 8100004 我愛花錢連鎖有限公司 2020/3/5 17:25 800 益安寧丸72丸*2瓶(每18丸重3.1g) 1 27 趙六 8100004 我愛花錢連鎖有限公司 2020/3/9 17:39 800 益安寧丸72丸*2瓶(每18丸重3.1g) 1 28 趙六 8100004 我愛花錢連鎖有限公司 2020/3/11 17:30 480 七十味珍珠丸(甘露)1g*6s 1 29 趙六 8100004 我愛花錢連鎖有限公司 2020/3/22 16:58 1154 雙參龍膠囊45盒裝0.3g*24s*45盒 1 30 楊七 8100005 我愛花錢連鎖有限公司 2020/3/1 16:54 100 朱砂安神丸6g*10袋 1 31 楊七 8100005 我愛花錢連鎖有限公司 2020/3/12 20:53 14 消痔靈片0.3g*24片 1 32 楊七 8100005 我愛花錢連鎖有限公司 2020/3/18 10:04 402 回元堂 固本回元口服液 20ml*24瓶20ml*24瓶 1 33 楊七 8100005 我愛花錢連鎖有限公司 2020/3/21 11:18 847 伏立康唑分散片(復銳)0.2g*6s 1 34 楊七 8100005 我愛花錢連鎖有限公司 2020/3/1 17:36 30 多酶片100s/盒 1
代碼
這里是通過jupyter來分段顯示的。第一次看我文章的小伙伴如果不了解jupyter可以在復制下面代碼的時候把所有輸出改成通過print()的方式輸出
#%%
import pandas as pd
import re
#需求:
# 1. 把交易明細分成明細跟規格兩列并刪除交易明細這列
# 2. 明細中把例如珍牡腎骨膠囊(珍泉)的作為明細,0.63g*48粒*3盒作為規格拆分提取
#讀取源數據
df = pd.read_excel("./datas/extract案例演示數據.xlsx")
#%%
#提取交易明細這一列
get_column = df["交易明細"]
#通過正則提取數據(?P<名字>)為固定寫法給數據加新列名
df01 = get_column.str.extract(R"(?P<明細>[\u4E00-\u9FA5]+\(*[\u4E00-\u9FA5]+\)*)")
df02 = get_column.str.extract(R"(?P<規格>(?:0.|\w*)\w*\*\w*[\u4e00-\u9fa5](?:\S+|))")
#%%
#通過join函數合并2個DataFrame
join_data = df01.join(df02)
join_data
#%%
#刪除原有交易明細數據
del df["交易明細"]
df
#%%
#二次合并,刪除后交易明細的dataframe合并拆分后數據的dataframe
two_join = df.join(join_data)
#%%
#因為合并后存在排序問題,列名為漢字所以我通過loc方法進行的列名指定排序
#loc方法這里不再講解,請參照loc,iloc篇章
result = two_join.loc[:,["序號","姓名","消費地點","消費時間",
"理賠金額(元)","明細","規格","數量"]]
result
#%%
#輸出到Excel
result.to_excel("./datas/extract_結果.xlsx",index=False)
print("文件寫入完畢!!")
#%%結果
二,contains方法的使用
contains對比extract而言更多的不是提取,而是一種篩選。有種想python中的in的關系。
只要查詢的DataFrame的某列或者某行包含查詢字符串的部分字段就可以匹配出所有匹配到的數據。當然可以直接傳字符串也可以通過正則來進行篩選。
數據源
學員編號 學生姓名 學生年齡 手機號碼 E-mail地址 家庭住址 101 劉鵬 18 13599713364 www.zhangsan@qq.com 江蘇省蘇州市工業園區津梁街 102 李四 20 15923796671 www.lisi.163.com 北京市朝陽區西北路石井街22幢 103 趙五 17 18655301183 www.zhaofive.yahoo.com 山東省煙臺市芝罘區北大街55號 104 tony 30 15877563321 www.tonyliu.ibm.com 江蘇省蘇州市姑蘇區山塘街177號 105 馬云 47 15977560013 www.mayun.alibaba.com 浙江省杭州市西湖路110號1888 106 Jack 20 13677569901 www.jack123@qq.com 廣東省深圳市南山區西麗1592幢12 107 tom 19 18622349971 www.tom456@qq.com 山東省青島市人民路1234幢
代碼:這里通過jupyter分段來顯示結果
#%%
import pandas as pd
import re
df = pd.read_excel("./datas/Person_info1.xlsx")
#%%
#傳入正則匹配只要包含的數據
df.loc[df["家庭住址"].str.contains(r"\d")]結果

通過字符串篩選數據
#%%
#傳入字符串,contains屬于模糊查找.只要包含就篩選
df.loc[df["家庭住址"].str.contains(r"津梁街")]
#%%
df.loc[df["家庭住址"].str.contains("江蘇省")]結果

另外contains可以二次多次運用。因為涉及到保密數據不方便展示復雜數據。大家可以先嘗試按照上面的簡單數據,先過濾出家庭地址,再過濾出來年齡。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





