溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如果我們要鍛煉一個人類小孩最基本的運動智力,比如抓握抬舉,或者是疊被子疊衣服這樣的家務活兒,幾乎是不需要指導的。
很多時候只要將嬰孩放置到日常生活情境中,讓他與周圍的環境和物體互動,大多數就能在玩耍中自動掌握判斷空間、重力、協調等能力了。
與之相比,機器人就比較“嬌生慣養”了。
目前絕大多數機器人,都無法自我適應和從對復雜的環境中學習通用運動能力。
這就帶來了一個難題:機器人只能很“笨拙”地完成一些程序員率先編程好的動作,并且是用單一的物體來完成單一的技能,這個特定的任務和道具就是它的全世界。比如,會遞杯子就不會疊被子。

這意味著,我們可能要設計成千上萬種機器人,只為了應對某一個具體任務。這實在是太蠢了。
不過,要讓機器學會自主感知世界,并根據環境變化做出相應的動作,那可是個大工程。
最近,伯克利大學就研究出了一種新的算法,基于視覺模型的強化學習,讓全能機器人成為可能。
換句話說,原本獨屬于人類的“元運動智力”,也有望在機器身上打開。
當機器人具有了掌握一般性技能并將其內化成“經驗”的能力,能夠靈活地執行多種同類任務,不需要每次都重新學習或編程,前景顯然是值得驚喜的。
那么,這么神奇的事情究竟是怎么實現的?
新算法是如何指導機器工作的?
簡要來說,這種算法可以通過一個預測墨西哥,使用沒有標簽的感官數據集,讓機器自主學習大量多樣化的圖像,進而在完成任務時更靈活地預測和判斷。這樣,它就能執行在各種不同的物體上執行很多不同任務,而不需要針對每個對象或每個任務都重新學習一次。
在伯克利大學的研究人員眼中,能夠在單一模式下獲得這種通用型運動能力,是智力的一個基本體現。
那么,這種方法究竟是如何指導機器人完成工作的呢?
首先,研究人員為機器人制作一個龐大且豐富多彩的數據集合,不局限于某一個物體或某一項技能;
然后,為機器人裝上了能夠感知圖像像素(視覺)、手臂位置(自我感覺)和發送電機指令(動作)的各種傳感器。
完成這些準備工作之后,就讓兩個機器人同時在資源庫中自主收集數據和學習,并且實時進行分享。
由于兩個機器人可以分享彼此的感覺和數據,這就使其掌握了預測接下來手臂移動路線的能力,從而使得動作的運動范圍具備了更大的伸縮彈性,以完成操作不同類型物體的多樣任務。
比如他們就讓一臺機器完成了移動蘋果這樣的剛性物體,以及折疊衣服這樣的柔性物體,機器人都表現的還不錯。
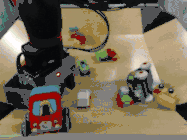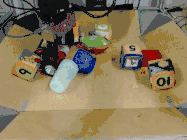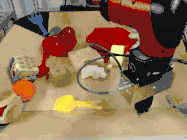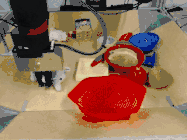

而且,即使面對以前從未見過的目標,雖然做出的預測并非和人類一樣十全十美,但仍然可以有效地完成指定任務。
比如下圖中,研究人員給出的任務是把蘋果放在盤子里,中間是機器人做出的計劃,然后是執行的情況。



這個算法模型在想法上絕對是別具一格。一直以來,基于預期結果來規劃行動路線,并根據不同步驟和觀察狀況來實時迭代和改進計劃,是人類應對復雜世界意外的獨特技能。如今,機器人也有望學會這樣的“高智力”游戲,在應用性上帶來的改變令人真實心動了。
重建機器效率的坐標系:新模型的應用場景
現實環境是復雜多樣的,提高機器人對環境的適應能力,讓任務執行更加靈活,這個新算法確實給機器人應用帶來了極大的想象空間。
最大的亮點在于,對機器的功能設想更符合現實情況。通用能力可以很容易地被遷移到不同的任務上,大大減少了完成特定任務所需要開發和部署的算法數量。
目前看來,新模型至少會在以下領域革新機器人的表現:
1.客服機器人。大多數客服機器人對環境不具備適應性,需要程序員將各種情況考慮在內,有的甚至直接由人工在后臺進行交互操作。但有了通用模型算法之后,機器人就能夠在與人類用戶的交互中自主學習,學會解決一些開放型問題,變得更加自主靈活。
2.醫學機械。目前,醫學機器人只能作為醫生雙手的延伸來協助完成手術任務。要自主完成高精度手術,幫助減少醫生的勞力,醫學機器人必須能夠感知手術部位的空間位置、處理更精細、更高復雜度的操作,新的模型顯然提供了更多的可能性。

3.工業機械。工業機器人已經擁有了一定的通用性和適應性,但往往都需要跟隨其工作環境變化的需求再編程,或者是更換不同的操作器來執行不同任務,都會帶來一定的成本。如果新算法被真實應用起來,工業生產的成本和效率都將變得更低。
4.個性化視頻生成。除了在現實世界中進行動作感知和理解預測,該算法在視頻生成領域也有極大空間。比如系統可以通過大量無需標記的視頻資源自主學習,根據視頻中的人物進行體態識別和模仿,讓AI量身定制高擬人度的視頻成為可能。
掌握了通用技能的機器應用還有很多,其背后的商業前景也十分廣闊,畢竟效率才是人類發明機器的初衷。
品嘗果實之前,還需應對哪些挑戰?
說了這么多,感覺新算法的實現并不難,應用端也有著足夠的承托力。是不是很快就可以成為現實了呢?
目前來看,在“摘桃子”之前,該算法還有一些特殊的限制,可能會使其在實際應用中受阻。
一是需要的訓練數據量很大。機器做出實際可執行的操作預測,完全依賴于龐大多元化數據集。
為了讓機器能夠根據預測先前幀的運動分布來想象和模擬接下來的像素運動,研究人員引入了59,000個機器人交互的數據集,進行大規模自監督學習。
如何在成本控制之下獲取龐大優質的數據資源,恐怕會成為算法落地的頭號門檻。

二是無監督學習帶來的一系列問題。比如,由于訓練數據完全沒有標簽和獎勵機制,如何保證機器人能夠理解并接受指定任務,再以結果導向展開行動,在現實層面有很多未知性。
伯克利的解決方案是設置一個自我監督算法,讓機器保持對目標的興趣,持續跟蹤并不斷重試,直至成功。但是否能夠穩定輸出,還需要更多的補充研究。
再比如,無監督下機器做出的預測都是人類無法用自主經驗來解釋的,有可能并不是最優的傳輸方案,還可能因為“黑箱”帶來不可預知的風險。

當我們還不理解自己的“元智力”是如何運作的時候,又如何保證可以將機器的“元智力”控制的很好呢?
總而言之,這一算法雖然很令人驚喜,但也并非完美。想象很美好,實用性也不算差,但從實驗室到商業場景之間,還有很長的一段路要走。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





