溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
https://www.toutiao.com/i6713143613334749703/

今年是中國人工智能四十年,在這四十年間發生了很多事情,聽聽張正友博士講一講計算機視覺的前世、今生和可能的未來。
文 | 汪思穎
AI 科技評論按: 7 月 12 日-7 月 14 日,2019 第四屆全球人工智能與機器人峰會(CCF-GAIR 2019)于深圳正式召開。峰會由中國計算機學會(CCF)主辦,雷鋒網、香港中文大學(深圳)承辦,深圳市人工智能與機器人研究院協辦,得到了深圳市 政府 的大力指導,是國內人工智能和機器人學術界、工業界及投資界三大領域的頂級交流博覽盛會,旨在打造國內人工智能領域極具實力的跨界交流合作平臺。
7 月 12 日,騰訊 AI Lab & Robotics X 主任,ACM Fellow, IEEE Fellow, CVPR 2017 大會主 席張正友博士為 CCF-GAIR 2019 主會場「AI 前沿專場」做了題為「計算機視覺的三生三世」的大會報告。以下為張正友博士所做的大會報告全文,感謝張正友博士的修改與確認。

大家好!非常感謝雷鋒網的邀請,讓我有這個機會給大家做個分享。今年是中國人工智能四十周年,在這四十年間發生了很多事情,雷鋒網讓我跟大家講一講計算機視覺的前世、今生和可能的未來。其實這個報告應該由我的好朋友香港科技大學權龍教授來講,他比我早一年出國,而且他現在還在港科大潛心研究計算機視覺。我這些年間,還有好多年在做語音處理和識別、多媒體處理和機器人,所以我在計算機視覺上的研究史還不算很長。不過權龍教授有事沒法參加,我只能濫竽充數,給大家講講計算機視覺的一些故事。
雷鋒網找我是聽說我開始研究計算機視覺比較早。我 198 5 年浙大本科畢業, 198 6 年去法國,參與研發了可能是世界上第一臺用立體視覺導航的移動機器人。
圖像處理
198 6 年其實發生了很多事情, 198 6 年是我第一次參加國際會議,是在巴黎召開的 ICPR(世界模式識別大會)。在這次大會上,我碰到了復旦大學的吳立德教授,他帶領了一支中國的代表團,并在會上做了一場大會報告,介紹了中國在模式識別上的研究現狀,他們準備申請 198 8 年的 ICPR 在中國召開。

這里需要提到一個關鍵性的人物,那就是普渡大學的傅京孫教授,他是模式識別領域的鼻祖。他是 19 73 年第一屆 ICPR 的主 席,1976 年創建了 IAPR,1978 年創刊了 IEEE TPAMI,并擔任第一屆主編。本來他是支持 198 8 年 ICPR 在中國召開的,但不幸的是 198 5 年他去世了,所以 198 8 年的申請沒有成功。如果 198 8 年 ICPR 能在中國召開,也許中國在模式識別和計算機視覺上的發展會更提前。當然歷史沒有如果。ICPR 在中國的召開等到了三十年以后,2018 年在譚鐵牛院士的帶領下,ICPR 第一次在中國召開。

198 6 年還有一個很重要的事件,就是我的法國學長馬頌德回國,他創立了 NLPR(國家模式識別重點實驗室)。NLPR 創立之后,吸引了大批國外的學者回國,同時邀請了很多國外的訪問學者,中國計算機視覺領域開始與國際接軌。當然馬頌德是中國科技界重要人物,后來擔任科技部副部長。 199 7 年他還創立了中法聯合實驗室,這個實驗室一半的研究人員都是法國人,這在中國也是一個壯舉。
提到計算機視覺,離不開一個標志性人物,MIT 的教授 David Marr。19 79 年,剛好 40 年前,他提出了視覺計算的理論框架。Marr 的理論框架有三個層次,從計算什么,到如何表達和計算,到硬件的實施。
具體到三維重建,Marr 認為從圖像要經過幾個步驟,第一個步驟叫 primal sketch,也就是圖像處理,比如邊緣提取。所以到八十年代中葉,計算機視覺的主要工作是圖像處理。最有名的工作可能是 198 6 年 MIT 一個碩士生發表的 Canny 邊緣檢測算子,基本上解決了邊緣提取的問題。如下圖所示,左邊是原始圖像,右邊是檢測出的邊緣。

那時候還有一個比較有名的工作是華人科學家沈俊做的,他那時在法國波爾多大學。他比較了不同的算子。他的算子在有些圖像方面要比 Canny 檢測器要好。所以到了八十年代中葉,當我留學法國的時候,圖像處理已經做的差不多了。

立體視覺及三維重建
幸運的是,幾何視覺剛開始興起。有兩位代表人物,一位是法國的 Olivier Faugeras,他是我的博士導師,另一位是美國的 Thomas Huang,我們叫他 Tom。他們是好朋友,還一起寫過文章。我 198 7 年就認識 Tom,他對我有非常大的幫助。他培養了 100 多位博士,包括不少活躍在中國學術界和工業界的計算機視覺專家,他對中國計算機視覺的貢獻是非常巨大的。
我很榮幸師從 Olivier Faugeras,參與開發了世界上第一臺用立體視覺導航的移動機器人。 198 8 年我的第一個研究成果發表在第二屆 ICCV 上,右邊是在美國 Florida 開會的一張照片。那時候計算機視覺還沒有紅火,那屆 ICCV 大概只有 200 個參會者,華人就更少了,大概只有我,權龍,還有 Tom 的學生翁巨揚。我在博士期間圍繞三維動態場景分析做了不少工作, 199 2 年把這些整合成一本書發表。

現在我想舉一個簡單的例子,不定性的建模和計算,希望通過下面這一頁 PPT 你們就能明白什么是三維計算機視覺。
這里需要用到概率與統計,這非常重要,但現在做視覺的人往往忽略了。下面兩條線代表了兩個圖像平面。左邊圖像上一個白點對應右邊圖像上一個白點。每個圖像點對應空間一條直線,兩條直線相交就得到一個三維點,這就是三維重建。同樣,左邊圖像的黑點對應右邊圖像的黑點,兩線相交得到一個三維點。但是圖像的點是檢測出來的,是有噪聲的。我們用橢圓來代表不定性,那么圖像的一個點就不對應一條線了,而是一個椎體。兩個椎體相交,就代表了三維重建的點的不定性。這里可以看到,近的點要比遠的點精確。當我們用這些三維重建點的時候就需要考慮這些不定性。比如當機器人從一個地方移動到另一個地方,需要估計它的運動時就必須考慮數據的不定性。
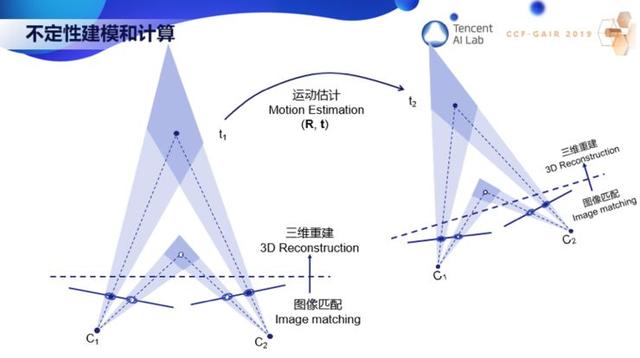
90 年代初我提出了 ICP 算法,通過迭代點的匹配來對齊不同的曲線或曲面。這個算法也用在很多地方。我們現在經常聽到的 SLAM,它其實就是我們以前做的從運動中估計結構,三維重建,不定性估計,ICP。事實上,SLAM 在 90 年代初理論上已經解決了。
199 5 年我提出了魯棒的圖像匹配和極線幾何估計方法,同時把程序放到網上,大家都以此作為參照。這可能是世界上第一個,至少是之一,把計算機視覺的程序放到網上讓別人用真實圖像來測試的。所以這個算法那時候就成為計算機視覺的通用方法。
199 8 年我提出了一個新的攝像機標定法,后來大家都稱它為「張氏方法」,現在它已經在全世界的三維視覺、機器人、自動駕駛上普遍應用,也獲得了IEEE Helmholtz 時間考驗獎。

199 8 年我和馬頌德對日益成熟的幾何視覺做了總結,作為研究生教材由科學出版社出版。
199 8 年還發生了很多事情,一個是 MSRA(微軟亞洲研究院)的成立,一個是騰訊公司的成立。這兩家看似無關的機構其實對中國計算機視覺的發展,對中國人工智能的發展,起了不可估量的作用。MSRA 給中國帶來了國際先進的研究方法和思路,培養了一大批中國的優秀學者,同時也請了一些國外的研究學者來到中國。騰訊促進了中國互聯網的發展,因為有互聯網,中國研究人員能夠幾乎實時地接觸到國際最頂尖的研究成果。所以這兩個結合,對中國人工智能領域的發展起到了很大的作用。
中國計算機視覺界一個重要的標志性事件是 2005 年 ICCV 在北京召開,馬頌德和 Harry Shum 擔任大會主 席,這標志著中國計算機視覺的研究水平已經得到國際的認同。我也很榮幸地從 Tom Huang 前輩手中接過 IEEE Fellow 的證書。
深度學習的崛起
可能幾何視覺的理論已經比較成熟了,90 年代末,計算機視覺的研究開始進入物體和場景的檢測和識別,主要方法是傳統特征加上機器學習。
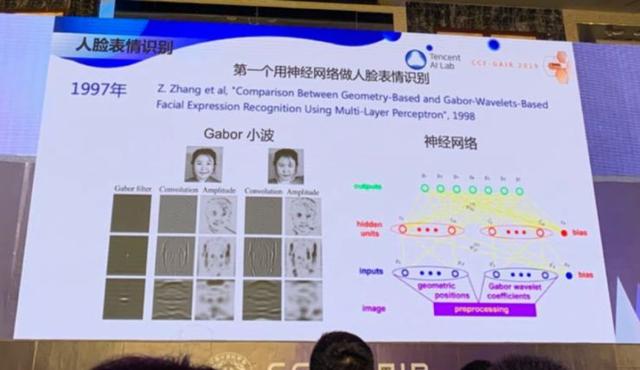
那時候我做幾何視覺做了很長時間, 199 7 年,我也開始嘗試,開發了世界上第一個用神經網絡來識別人臉表情的系統,用的特征是 Gabor 小波 。雖然 20 多年前就開始人臉表情識別,但那時數據太少,一直到 2016 年我們才在微軟把人臉表情識別技術商業化,在微軟的認知服務上,大家都可以調用。
在傳統特征加機器學習的年代,需要提一下一個里程碑的工作,那就是 2001 年的 Viola-Jones Detector。通過 Harr 特征加級聯分類器,人臉的檢測能夠做得非常快,在 20 年前的機器上就能做到實時。這對計算機視覺產生了很大的影響。此后的循環是一波一波的新數據集推出,加一波一波的算法刷榜。
2009 年一個叫 ImageNet 的數據集出現了,這是斯坦福大學李飛飛團隊推出的,這個數據集非常重要,它的意義不在于這個數據集很大,而在于幾年后催生了深度學習時代。
2012 年,Geoffrey Hinton 的兩個學生開發了 AlexNet,用了 8 層神經網絡,6 千萬參數,誤差比傳統方法降了十幾個百分點,從 26% 降到 15%,從此開啟了計算機視覺的深度學習時代。這個 AlexNet 結構其實和 198 9 年 Yann LeCun 用于手寫數字識別的神經網絡沒有很大區別,只是更深更大。
由于 Geoffrey Hinton, Yoshua Bengio, Yann LeCun 對深度學習的貢獻,他們共同獲得了 2018 年的圖靈獎。這個獎他們當之無愧。要知道 Geoffrey Hinton 198 6 年就提出了 backpropagation,坐了 25 年的冷 板凳 。

在深度學習時代還有一個里程碑的工作,2015 年,微軟亞洲研究院的何愷明和孫劍提出 ResNet,用了 152 層神經網絡,在 ImageNet 測試集上的誤差比人還低,降到了 4% 以下。
我在深度學習領域也有一點貢獻。2014 年我和 UCSD 的屠卓文合作,提出了 DSN(Deeply- Supervised Nets)深度監督網絡,雖然影響沒有 ResNet 大,但也有近一千次引用。我們的想法是直接讓輸出監督中間層,使得最底層盡可能最大逼近要學習的函數,同時也緩解梯度「爆炸」或「消失」。
剛剛過去的 CVPR2019 可以被稱為是華人的盛典,在組織者里面有很多華人面孔,包括大會主 席朱松純、程序委員會主 席華剛和屠卓文。在五千多篇投稿中,40% 來自大陸,最佳論文獎和最佳學生論文獎的第一作者也都是華人。所以中國的計算機視覺能力還是很強的,這一點值得驕傲。
計算機視覺的研究要回歸初心
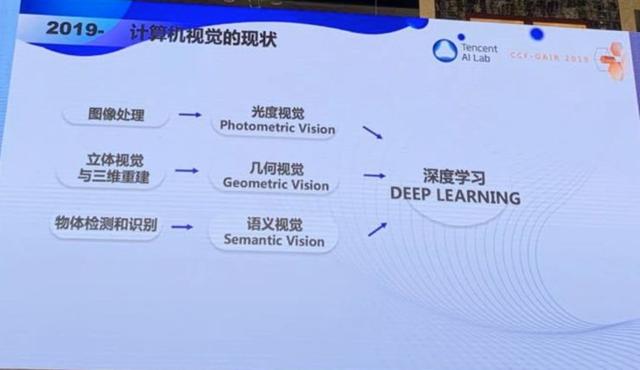
現在讓我們回顧一下計算機視覺研究的演變,從最初的圖像處理、立體視覺與三維重建、物體檢測和識別,到光度視覺、幾何視覺和語義視覺,到現在的深度學習打遍天下。這是讓我擔憂的。深度學習有很多局限性。
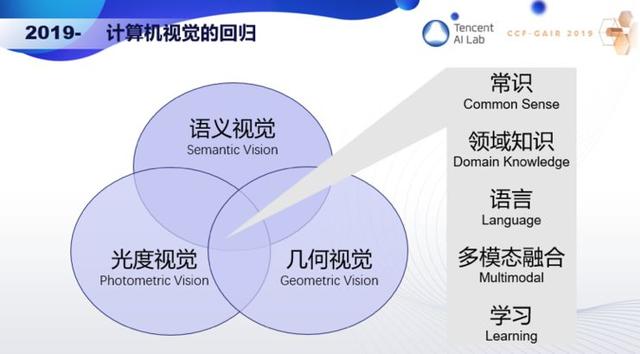
我認為接下來應該要回歸初心,讓光度視覺、幾何視覺和語義視覺緊密結合起來,同時注入常識和領域知識,和語言進行多模態融合,通過學習不斷演變。
我們騰訊 AI Lab 在這方面也開始做了一點點工作。比如我們的看圖說話項目能夠用語言描述一張照片的內容,2018 年 1 月,我們上線 QQ 空間 app 讓視障用戶「看到」圖片。

我們還整合了計算機視覺、語音識別和自然語言處理技術,開發了一個虛擬人產品,探索多模態人機交互,賦能其他場景,助力社交。我們還開發了二次元的虛擬人來做游戲解說,它能實時理解游戲場景并將它描述出來。
那么現在的人工智能真的智能嗎?想象一下,如果一個人想要蓋住你的眼睛,你會怎么做?我是會躲開的。但是從我剛才播放的視頻中可以看到,現在的監控系統顯然沒有這樣的舉止。現在的人工智能只是機器學習:從大量的標注數據去學習一個映射。
什么是真正的智能?我想目前還沒有定論,而且我們對我們自己的智能還沒有足夠的了解。不過我很認同瑞士認知科學家 Jean Piaget 說的,智能是當你不知道如何做的時候你用的東西。我認為這個定義是非常有道理的。當你無法用你學到的東西或天賦去面對時,你動用的東西就是智能。如何去實現有智能的系統呢?可能有很多條路,但我認為一條很重要的路是需要把載體考慮進去,做有載體的智能,也就是機器人。

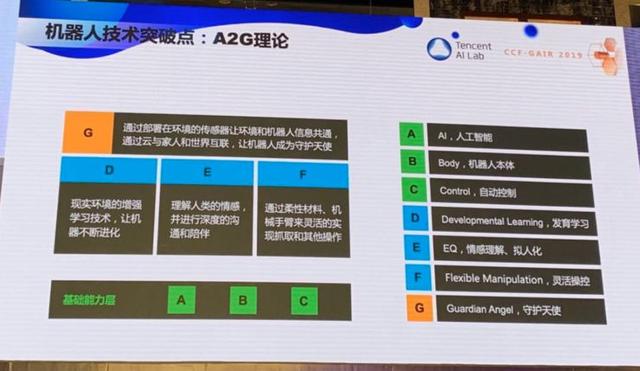
在機器人領域,我提出了 A2G 理論。A 是 AI,機器人必須能看能聽能說能思考,B 是 Body 本體,C 是 Control 控制,ABC 組成了機器人的基礎能力。D 是 Developmental Learning,發育學習,E 是 EQ,情感理解、擬人化,F 是 Fle xi ble Manipulation,靈活操控。最后要達到 G,G 是 Guardian Angel,守護天使。
騰訊做了三款機器人:絕藝圍棋機器人、桌上冰球機器人,還有機器狗。可以為大家展示機器狗的視頻,機器狗具備感知系統,能夠繞開障礙物,看到懸空的障礙物能匍匐前進,看到前面一個人能蹲下來看著人。
我的報告就到這里,騰訊的 AI 使命是 Make AI Everywhere,我們一定會善用人工智能,讓人工智能造福人類,因為科技向善。謝謝大家。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





