溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
https://www.toutiao.com/a6716402400925581836/

2018 全球人工智能與機器人峰會(CCF-GAIR)在深圳召開,商湯科技聯合創始人、港中文-商湯聯合實驗室主任林達華教授分享了計算機視覺研究中的新探索。
演講中,林達華對計算機視覺過去幾年的發展進行了總結、反思與展望。他表示,深度學習開啟了計算機視覺發展的黃金時代。這幾年里計算機視覺取得了長足發展,但這種發展是粗放式的,是用數據和計算資源堆出來的。這種發展模式是否可以持續,值得深思。
他指出,隨著計算機視覺在準確率方面觸頂,行業應該尋求更多層面的發展。商湯的嘗試主要有三方面:一、提高計算資源的使用效率;二、降低數據資源的標注成本;三、提高人工智能的品質。
以下是林達華的全部演講內容:
今天非常榮幸能夠在這里分享港中文-商湯聯合實驗室過去幾年的工作。剛才幾位講者從商業角度做了精彩分享,相信大家都獲益良多,我的演講可能有點不一樣。我是商湯的聯合創始人,但我并沒有直接介入商湯在商業領域的運作。如果大家關心的問題是商湯什么時候上市,我恐怕回答不了。
但我可以告訴大家,商湯公司不是一天建成的。它的成功靠的不只是過去三年半的努力,還有它背后這個實驗室18年如一日的原創技術積累。這個實驗室所做的事情,決定的不是商湯今天拿什么出去賺取利潤;而是如果商湯想成為一家偉大的科技公司,未來3年、5年甚至10年應該朝哪個方向走。
人工智能發展很快,但卻是粗放型發展
下面這張圖想必大家都非常熟悉。
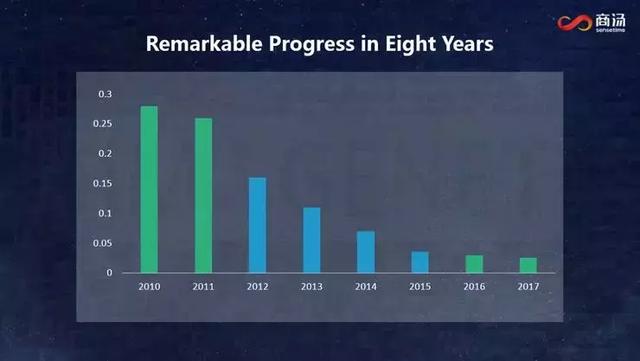
過去8年,計算機視覺可以說取得了突破性進展,其中技術上最重要的進展是引入了深度學習。這個領域有一個非常高級別的比賽——Image Net。2012年之前,這個比賽中的識別錯誤率比較高,2012年引入深度學習技術后,計算機視覺經歷了長達4年的黃金期。這4年黃金期中,Image Net比賽中的識別錯誤率從20%下降到了接近3%,之后就停滯不前了,直到去年這個比賽停辦。
所以我想問一個問題:深度學習確實推動計算機視覺在這幾年黃金期里取得了長足和突破性的進展,但這是否意味著計算機視覺發展到今天的水平已經走到了終結?站在今天的基礎上往前展望3年、5年、10年,我們未來應該朝哪個方向研究?這是我們實驗室,也是商湯一直在思考的。
人工智能在過去幾年取得的成功不是偶然的,也不僅僅是算法發展的結果,而是很多因素歷史性地交匯在一起促成的。第一個因素是數據,我們擁有海量的數據。第二個因素是GPU的發展,促進了計算能力大幅躍升。在數據和算力的基礎上,算法的進展帶來了今天人工智能的成功,以及它在眾多應用場景的落地。我想向大家傳遞的信息是,雖然我們看到人工智能的成功和算法的巨大進展,但人工智能不是一個魔術,某種意義上,它是龐大數據量和強大計算能力支撐下的性能進步。
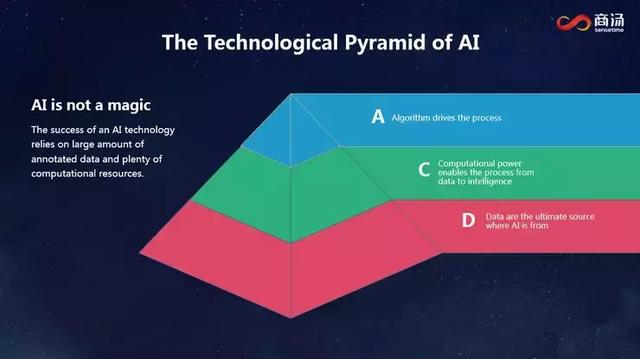
回過頭來看人工智能這幾年輝煌的發展歷程,我們可以看到,某種意義上這是一種非常粗放型的發展。大家都在追求正確率和性能,所有比賽榜單上,中國公司都排進了前三名。我們雖然登上了不少榜單,但行業利潤基本都被制定標準的公司賺去了。這種發展模式是否可以持續?這值得我們深思。
除了準確率,還要追求效率、成本和品質
回顧過去幾年深度學習或人工智能的發展,我覺得我們還有很多事情要做,有很長的路要走。
接下來和大家分享我的幾個思考方向:一、學習效率,我們是否充分利用了現有的計算資源?二、如何解決數據和標注的成本問題?三、我們雖然在榜單中達到了99.9%的準確率,但這樣訓練出的模型是否真的能夠滿足我們生活或社會生產的需要?這些都是我們推動人工智能更好、更快發展和落地需要解決的問題。

下面,我首先詳細談談第一個方面——效率。
前面提到,我們現在走的是粗放型發展路線,是靠堆積數據和計算資源來換取高性能,這是資源而不是效率的競賽。行業發展到今天,制定標準的公司賺取了大部分利潤,面對這種情況,我們未來該如何發展?要回答這個問題,首先要回顧現在的模型和技術模式,看是否還有優化的空間。優化的原理非常簡單,就是把好鋼用在刀刃上。
舉一個例子來說明。兩年前我們開始進入視頻領域,視頻對效率的要求非常高,因為視頻的數據量非常龐大,一秒鐘視頻有24幀,一分鐘就是1500幀,相當于一個中型數據庫。用傳統處理圖像的方式處理視頻顯然不合適。
2013、2014年的時候,大部分視頻分析方法都比較簡單粗暴:把每一幀都拿出來跑一個卷積網絡,最后把它們綜合到一起進行判斷。雖然說過去幾年計算資源發展非常快,但是GPU的顯存還是有限的,如果每一層都放到CNN里去跑,GPU顯存只能容納10幀到20幀左右,一秒鐘的視頻就把GPU占滿了,沒辦法長時間對視頻進行分析,這是一種非常低效的模式。
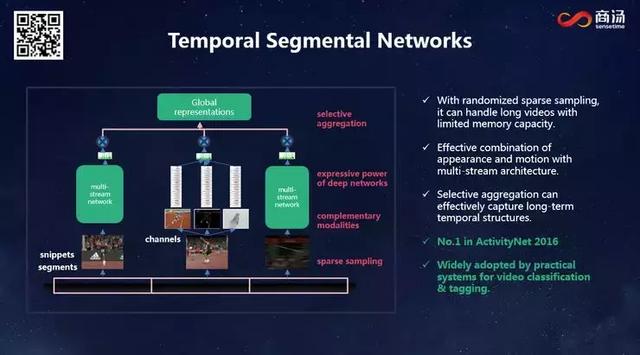
我們知道,視頻相鄰幀之間的重復度非常高,如果每一幀都跑一次,其實大量計算資源都被浪費了。意識到這種重復計算模式的低效后,我們對采樣方法進行了改變,改用稀疏采樣:無論多長的視頻,都劃分成等長的段落,每個段落只取一幀。這樣一來就能在時間上對視頻形成完整覆蓋,分析出的結果自然具有較高的可靠性和準確性。憑借這個網絡,我們拿到了2016年的ActivityNet冠軍。現在大部分視頻分析架構都已經采用了這種稀疏采樣的方法。
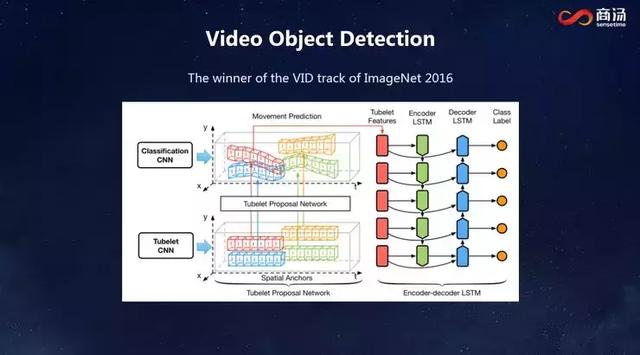
之后,我們進一步擴展研究領域,不僅做視頻理解,還做視頻中的物體檢測。這帶來了新的挑戰:之前做分類識別,我們可以分段,把每一段拿出來都可以獲得一個大體上的理解;但是物體檢測沒辦法這么做,必須把每一幀中的物體位置輸出來,時間上是不能稀疏的。
下圖展示了我們獲得2016年ImageNet比賽視頻物體檢測項目冠軍的網絡。這個網絡的做法基本是把每一幀的特征拿出來,判斷它的類型是什么,對物體框的位置做出調整,然后把它串起來。這里面每一幀都需要處理,當時最厲害的GPU每秒鐘只能處理幾幀,需要大量的GPU才能訓練出這個網絡。
我們希望把這樣一個技術用在實際場景,得到實時性的物體檢測的框架。如果我們每一幀都是按剛才的方法處理,需要140毫秒,完全沒有辦法做到實時。但如果稀疏地去采,比如說每20幀采一次,中間的幀怎么辦呢?
大家可能想到用插值的方法把它插出來,但是我們發現這個方法對準確度影響很大,隔10幀采一次,中間的準確度差距很大。在新提出的方法里,我們利用幀與幀之間相互的關系,通過一個代價小得多的網絡模塊,只需要花5毫秒,在幀與幀之間傳遞信息,就能很好地保持了檢測精度。這樣我們重新改變了做視頻分析的路徑之后,整體的代價就得到了大幅度的下降。這里面沒有什么新鮮的東西,網絡都是那些網絡,只是說我們重新去規劃了視頻分析的計算路徑,重新設計了整個框架。
大家可以看看結果。上面是7毫秒逐幀處理的,我們2016年比賽就是用的這個網絡,后面我們經過改進之后,超過62幀每秒,而且它的結果更加可靠、更加平滑,因為它使用了多幀之間的關聯。


商湯也在做自動駕駛,需要對駕駛過程中的場景自動地進行理解和語義分割,這也是一個非常成熟的領域。但大家一直沒關注到點子上,大家關注的是分割的準確率,像素級的準確率,這是沒有意義的。我們真正做自動駕駛,關心的是人在你車前時,你能以多快的速度判斷出有個人在那里,然后做出緊急處理。所以在自動駕駛的場景,判斷的效率、判斷的速度是非常重要的。之前的方法處理一幀要100多毫秒,如果真有一個人出現在車前面,是來不及做出反應的。
利用剛才所說的方法,我們重新改造了一個模型,充分地使用了幀與幀之間的聯系,我們可以把每一幀處理的效能從600毫秒降低到60毫秒,大幅度地提高了這個技術對于突發情景響應的速度。這里面其實也用到了剛才類似的方法,技術細節我就不說了。
剛才說到如何提高效率,接下來談談如何降低數據成本。
人工智能是先有人工才有智能,有多少人工才有多少智能。人工智能有今天的繁榮,不能忘記背后默默奉獻的成千上萬的數據標注人員。今天商湯有近800名標注員在日夜不斷地標注數據,一些大公司的標注團隊更是多達上萬人,這也是一塊巨大的成本。
如何降低數據標注的成本,是我們每天都在思考的事情。既然很多東西沒法通過人工標注,是否可以換個思路,從數據、場景中尋找它本身就蘊含的標注信息?
下圖展示了我們去年的一項研究成果,這一成果發表在CVPR上,它嘗試了一種全新的學習方式。過去圖片的標注成本非常高,每張圖片不僅要標注,還要把目標物體框出來。比如學習識別動物,需要人工把動物標出來。我們小時候學習辨認動物的過程不是這樣的,不是老師給我一個帶框的圖片去學習,而是通過看《動物世界》學習的。這促使我產生了一個想法:能否讓模型通過看《動物世界》,把所有動物識別出來?紀錄片中有字幕,如果把它跟視覺場景聯系在一起,模型是否就能自動學習?為此我們設計了框架,建立起視覺與文本之間的聯系,最后得出了下圖中的結果。
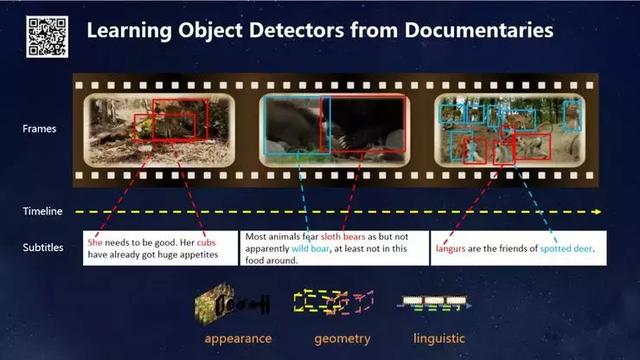
下圖是我們在沒有任何標注和人工干預的情況下,靠看《動物世界》和《國家地理》雜志,能夠精確識別的幾十種動物。

此外,做人臉識別也需要標注大量人臉數據。其中有一些數據,比如我們的家庭相冊,這些相冊雖然沒有標注,但卻蘊含很多信息。
大家看下面這張圖,這是電影《泰坦尼克號》中的一些場景。左上角這個場景,如果光看人臉很難認出這兩個人是誰。再看右上角第一個場景,我們可以認出左邊這個人是Rose,但右邊這個穿西裝的人還是看不清。如果我們能識別出電影背后的場景,就會發現Jack和Rose經常出現在同一個場景。基于這種社交互動信息,我們可以推斷,那個穿黑西裝的男子可能是Jack。這樣一來,在不用標注人臉的情況下,我們就獲取了大量有意義的數據。

我們還把這項技術用到了視頻監控領域:一個人從深圳的街道這頭走到那頭,人臉圖像經常會發生變化,但只要能追蹤到他的軌跡,我們就能判斷所拍攝到的人臉屬于同一個人,這對訓練人臉模型是非常寶貴的信息。這項成果剛剛發表在了CVPR的論文中。
最后談談質量。
人工智能的最終目的是為生活帶來便利,提高生活質量。但最近幾年人工智能的發展好像步入了誤區,認為人工智能的質量和準確率掛鉤。我覺得人工智能的質量是多方面、多層次的,不僅僅是準確率。
給大家看幾個例子。“看圖說話”是近幾年特別火的領域,即向計算機展示一張圖片,讓它自動生成描述。下圖是我們用最新方法得出的結果。

大家發現,我們向這個最好的模型展示三張不同的圖片,它會說同一句話,這句話在標準測試中的得分非常高,沒有任何問題。但我們把它和人類的描述放在一起后發現,人類不是這樣說話的。人類描述一張圖片的時候,即使面對同一張圖片,不同人的表述是不一樣的。也就是說,人工智能在追求識別準確度的時候忽略了其他的品質,包括語言的自然性和圖片的特征。
為了解決這個問題,去年我們提出了一個新方法。它不再把內容描述看成翻譯問題,而是把它當做一個概率采樣問題。它承認描述的多樣性,承認每個人看到同一張圖片會說不同的話。我們希望把這個采樣過程學習出來。關于這個模型的細節,大家可以查閱相關論文。這里只展示結果:針對同樣三張圖片,模型生成了三句更生動、更能描述圖片特征的語句。

我們再發散延伸一下:既然AI模型能生成一句話,那么是不是也能生成一段動作?下圖展示了我們的一項最新研究,很多AI公司都在做這方面的研究,讓AI生成一段生動的舞蹈。下面是一些簡單的動作,這些動作都是計算機自動生成的,不是我們用程序描述出來的。

最后,對前面的分享做一個總結。過去幾年,人工智能和深度學習都取得了突飛猛進的發展,這種發展既體現在標準數據集上的準確率提升,也體現在商業場景的落地。但回顧這一段發展歷程,我們發現,朝著準確率高歌猛進的過程中我們也遺忘了很多東西。我們的效率是否足夠高?我們是否在透支數據標注的成本?我們訓練出的模型是否能夠滿足現實生活對品質的要求?從這些角度來看,我覺得我們才剛剛起步。雖然我們實驗室和世界上許多其他實驗室取得了一些重要進展,但我們仍然處在起步階段,前面還有很長的路要走。以上,希望與大家共勉,謝謝!
以下是問答環節的精彩內容:
提問:我想知道,商湯在基礎研發和產品落地方面是如何進行資源分配的?
林達華: 這個問題非常好。我認為這不是一個簡單的分配問題,而是一個正循環的過程。我們前線的同事會接觸很多具體的落地場景,從場景中發現問題。我前面提到的很多問題都是他們從落地場景中發現的,這些問題可以為學術界提供不一樣的視角。前線的同事受制于產品落地的壓力,無法解決這些問題,這些問題就會轉移到實驗室,做長期的技術探討。探討的結果最終又會反哺產品落地。這使得商湯的技術具有領先和超前性,我們不僅僅跟友商拼數據和計算資源,還有技術上領先的視角。這就是我們基礎研究部門和前線產品部門之間的互動關系。
提問:cv廠商和傳統安防廠商在技術上合作是不是一種趨勢?合作模式是“AI+安防”還是“安防+AI”?
林達華: 傳統安防廠商提供的是集成解決方案和攝像頭,過去他們不怎么涉及AI技術。而商湯是從一個實驗室發展起來的,是從學術做起,然后慢慢走向落地。現在cv廠商和傳統安防廠商都在朝技術落地的方向走,大家交匯在了一起。所以我認為,傳統安防廠商和掌握先進AI技術的公司、實驗室深度合作是一種重要趨勢。
但中間也存在風險:一邊是從應用端往前走,一邊是從技術端往后走,大家都想占領技術上的制高點。這需要大家建立一種信任和共贏機制,只有這樣合作才能長久。
提問:在深度學習大行其道的環境下,傳統的機器學習方法還有沒有研究的價值?
林達華: 我在學術會議和公開場合演講時經常被問到這個問題。我覺得大家不要把深度學習看成一種全世界通吃的方法,某種意義上它是一種新的研究模式。我們最終面對場景和應用時,還是要提出一套解決問題的方案。深度學習的建模能力非常強,但它也有短板。比如我們面對一個復雜問題,涉及不同設備間的交互和多個變量的建模,可能傳統的概率學習、隨機過程就能發揮作用。如果把它跟深度學習結合在一起,就能實現性能上的突破。
我回香港任教之前,有很長一段時間在研究統計學習和概率圖模型。那時候概率圖模型很郁悶,雖然它有很多數據基礎,但使用基礎達不到數據需求。其實它是一個非常好的模型,可以讓我們對世界進行深度建模。有了深度學習后,它們可以配合使用,把一些變量的簡單假設——比如高斯分布這樣的假設——切換成利用深度網絡構造的模型。這樣一來,傳統模型就會得到升級迭代,為我們的具體問題和應用提供更高效的解決方案。所以他們不是一種取代關系,而是結合的關系。近幾年的很多研究都呈現出這種趨勢,把傳統理念和方法用深度學習進行武裝,最終得到了很好的效果。
提問:近年來圖像領域的深度學習遇到了一些瓶頸,而且短期來看也沒有突破性的進展,您從學術角度怎么看待?
林達華: 其實我整個演講都在談這件事。我覺得大家要把追求的面稍微擴大一些,機器學習的目標不只是數據,還有很多層面的研究值得我們探索。比如商湯過去做人臉識別只關注準確率,但后來我們發現很多問題,包括時間成本、數據標注、可靠性、模型壓縮等。這些之前的研究都沒有涉及,但現在成了一個非常大、非常有前景的領域。比如模型壓縮,之前并沒有這個需求,但我們在實際應用過程中發現原來的方法解決不了問題,才想到能不能把模型壓縮一下。這些來源于現實的想法,開拓了近幾年一些新的研究方向。單從準確率來看,目前確實已經到了很高的水平,再往前走的空間不大。但在具體應用中還有許多新的挑戰,每一個挑戰都是一個研究方向,還有很大的研究空間。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





