溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

大數據文摘出品
編譯:張睿毅、寧靜
計算機視覺是一門研究如何對數字圖像或視頻進行高層語義理解的交叉學科,它賦予機器“看”的智能,需要實現人的大腦中(主要是視覺皮層區)的視覺能力。
想象一下,如果我們想為盲人設計一款導盲產品,盲人過馬路時系統攝像機拍到了如下的圖像,那么需要完成那些視覺任務呢?

以上已經囊括了計算機視覺(CV)領域的四大任務,在CV領域主要有八項任務,其他四大任務包括:圖像生成、人體關鍵點檢測、視頻分類、度量學習等。
目標檢測作為CV的一大任務之一,其對于圖片的理解也發揮著重要的作用,在本文中,我們將介紹目標檢測的基礎知識,并回顧一些最常用的算法和一些全新的方法。(注: 每個小節展示的論文圖片,均在節末給出了具體的鏈接)
目標檢測定位圖像中物體的位置,并在該物體周圍繪制邊界框,這通常涉及兩個過程,分類物體類型,然后在該對象周圍繪制一個框。現在讓我們回顧一下用于目標檢測的一些常見模型架構:
R-CNN
該技術結合了兩種主要方法:將高容量卷積神經網絡應用于自下而上的候選區域,以便對物體進行局部化和分割,并監督輔助任務的預訓練。接下來是特定領域的微調,從而產生高性能提升。論文的作者將算法命名為R-CNN(具有CNN特征的區域),因為它將候選區域與卷積神經網絡相結合。
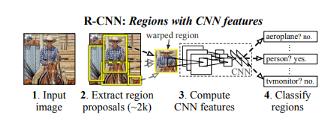
模型接收圖像并提取約2000個自下而上的候選區域,然后,它使用大型CNN計算每個候選區域的特征,此后,它使用特定類的線性支持向量機(SVM)對每個區域進行分類,該模型在PASCAL VOC 2010上實現了53.7%的平均精度。
模型中的物體檢測系統有三個模塊:第一個負責生成與類別無關的候選區域,這些候選區域定義了模型檢測器可用的候選檢測器集;第二個模塊是一個大型卷積神經網絡,負責從每個區域提取固定長度的特征向量;第三個模塊由一類支持向量機組成。

模型內部使用選擇性搜索來生成區域類別,選擇性搜索根據顏色、紋理、形狀和大小對相似的區域進行分組。對于特征提取,該模型通過在每個候選區域上應用Caffe CNN(卷積神經網絡)得到4096維特征向量,227×227 的RGB圖像,通過五個卷積層和兩個全連接層前向傳播來計算特征,節末鏈接中的論文解釋的模型相對于PASCAL VOC 2012的先前結果實現了30%的改進。
R-CNN的一些缺點是:
相關論文和參考內容鏈接:
https://arxiv.org/abs/1311.2524?source=post_page
http://host.robots.ox.ac.uk/pascal/VOC/voc2010/index.html?source=post_page
https://heartbeat.fritz.ai/a-beginners-guide-to-convolutional-neural-networks-cnn-cf26c5ee17ed?source=post_page
Fast R-CNN
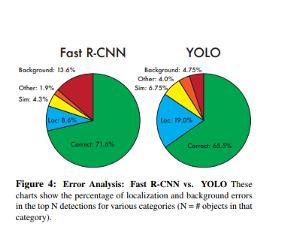
下圖中展示的論文提出了一種基于快速區域的卷積網絡方法(Fast R-CNN)進行目標檢測,它在Caffe(使用Python和C ++)中實現,該模型在PASCAL VOC 2012上實現了66%的平均精度,而R-CNN則為62%。
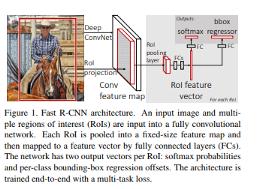
與R-CNN相比,Fast R-CNN具有更高的平均精度,單階段訓練,更新所有網絡層的訓練,以及特征緩存不需要磁盤存儲。
在其結構中,Fast R-CNN將圖像作為輸入同時獲得候選區域集,然后,它使用卷積和最大池化圖層處理圖像,以生成卷積特征圖,在每個特征圖中,對每個候選區域的感興趣區域(ROI)池化層提取固定大小的特征向量。
這些特征向量之后將送到全連接層,然后它們分支成兩個輸出層,一個產生幾個對象類softmax概率估計,而另一個產生每個對象類的四個實數值,這4個數字表示每個對象的邊界框的位置。
相關內容參考鏈接:
https://github.com/rbgirshick/fast-rcnn?source=post_page
Faster R-CNN
Faster R-CNN:利用候選區域網絡實現實時目標檢測,提出了一種訓練機制,可以對候選區域任務進行微調,并對目標檢測進行微調。
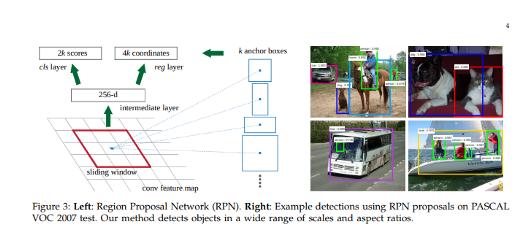
Faster R-CNN模型由兩個模塊組成:提取候選區域的深度卷積網絡,以及使用這些區域FastR-CNN檢測器, Region Proposal Network將圖像作為輸入并生成矩形候選區域的輸出,每個矩形都具有檢測得分。
相關論文參考鏈接:
https://arxiv.org/abs/1506.01497?source=post_page
Mask R-CNN
下面論文中提出的模型是上述Faster R-CNN架構的擴展,它還能夠估計人體姿勢。
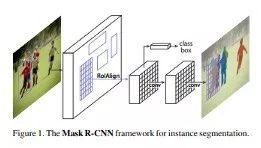
在此模型中,物體通過邊界框和語義分割實現分類和局部化,語義分割是將圖片中每個像素分類。該模型通過在每個感興趣區域(ROI)添加分割掩模的預測來擴展Faster R-CNN, Mask R-CNN產生兩個輸出,類標簽和邊界框。
相關論文參考鏈接:
https://arxiv.org/abs/1703.06870?source=post_page
SSD: Single Shot MultiBox Detectorz
下面的論文提出了一種使用單個深度神經網絡預測圖像中物體的模型。網絡使用特征圖的小卷積濾波器為每個對象類別生成分數。
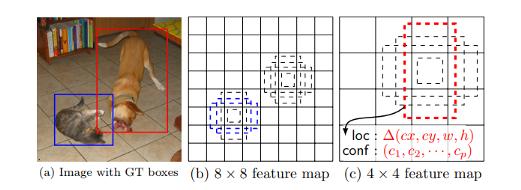
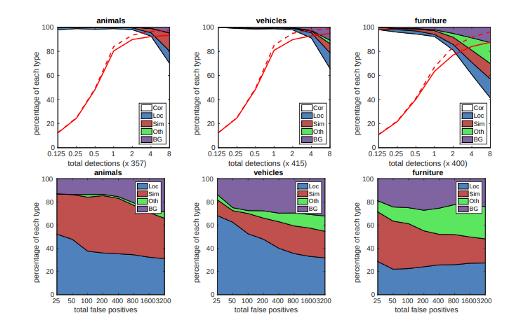
該方法使用前饋卷積神經網絡,產生特定目標的一組邊界框和分數,添加了卷積特征圖層,允許在多個尺度上進行特征檢測,在此模型中,每個特征圖單元格都關聯到一組默認邊界框,下圖顯示了SSD512模型在動物,車輛和家具上的表現。
相關內容參考鏈接:
https://arxiv.org/abs/1512.02325?source=post_page
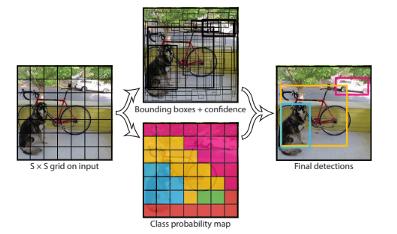
You Only Look Once (YOLO)
下圖中展示的文章提出了一種單一的神經網絡,可以在單次評估中預測圖像中的邊界框和類概率。
YOLO模型實時處理每秒45幀,YOLO將圖像檢測視為回歸問題,這使得其管道非常簡單因此該模型非常快。
它可以實時處理流視頻,延遲小于25秒,在訓練過程中,YOLO可以看到整個圖像,因此能夠在目標檢測中包含上下文。

在YOLO中,每個邊界框都是通過整個圖像的特征來預測的,每個邊界框有5個預測,x,y,w,h和置信度,(x,y)表示相對于網格單元邊界的邊界框中心, w和h是整個圖像的預測寬度和高度。
該模型通過卷積神經網絡實現,并在PASCAL VOC檢測數據集上進行評估。網絡的卷積層負責提取特征,而全連接的層預測坐標和輸出概率。
該模型的網絡架構受到用于圖像分類的GoogLeNet模型的啟發,網絡有24個卷積層和2個完全連接的層,模型的主要挑戰是它只能預測一個類,并且它在諸如鳥類之類的小物體上表現不佳。

此模型的平均AP精度為52.7%,但能夠達到63.4%。
參考鏈接:
https://arxiv.org/abs/1506.02640?source=post_page
將目標看做點
下圖中的論文提出將對象建模為單點,它使用關鍵點估計來查找中心點,并回歸到所有其它對象屬性。
這些屬性包括3D位置,姿勢方向和大小。它使用CenterNet,這是一種基于中心點的方法,與其它邊界框檢測器相比,它更快,更準確。

對象大小和姿勢等屬性根據中心位置的圖像特征進行回歸,在該模型中,圖像被送到卷積神經網絡中生成熱力圖,這些熱力圖中的最大值表示圖像中對象的中心。為了估計人體姿勢,該模型檢查2D關節位置并在中心點位置對它們進行回歸。
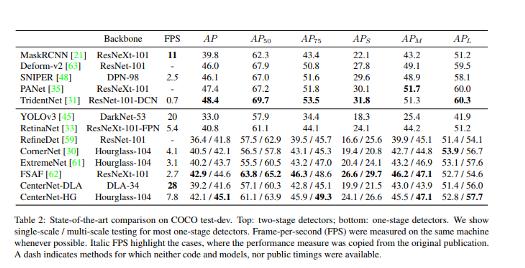
此模型以每秒1.4幀的速度實現了45.1%的COCO平均精度,下圖顯示了這與其他研究論文中的結果進行比較的結果。
論文參考鏈接:
https://arxiv.org/abs/1904.07850v2?source=post_page
用于目標檢測的數據增強策略
數據增強通過旋轉和調整原始圖片大小等方式來創建新圖像數據。
雖然該策略本身不是模型結構,但下面這篇論文提出了轉換的創建,轉換是指可應用于轉移到其他目標檢測數據集的對象檢測數據集。轉換通常應用在訓練中。

在此模型中,增廣策略被定義為在訓練過程中隨機選擇的一組n個策略,在此模型中應用的一些操作包括顏色通道畸變,幾何圖像畸變,以及僅邊界框注釋中的像素畸變。對COCO數據集的實驗表明,優化數據增強策略能夠將檢測精度提高超過+2.3平均精度,這允許單個推理模型實現50.7平均精度的準確度。
相關論文參考鏈接:
https://arxiv.org/abs/1906.11172v1?source=post_page
總結
我們現在應該跟上一些最常見的——以及一些最近在各種環境中應用的目標檢測技術。上面提到并鏈接到的論文/摘要也包含其代碼實現的鏈接。不要自我設限,目標檢測也可以存在于智能手機內部,總之,需要我們不停地探索學習。
相關報道:
https://heartbeat.fritz.ai/a-2019-guide-to-object-detection-9509987954c3
https://www.toutiao.com/a6720074844945252867/
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





