溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

前幾日,雷鋒網報道了 武漢大學成立人工智能研究院的消息 后,有讀者看到國內已成立的人工智能學院列表中有「中國人民大學-高瓴人工智能學院」,表示好奇人大成立人工智能學院做什么。雷鋒網在這篇文章中詳解「高瓴人工智能學院」的「思」與「做」。
一千個讀者,就有一千個哈姆雷特。
一千所高校,也將有一千個不同特色的人工智能學院/研究院。
中國人民大學,與清、北并稱三大超一流名校,清華理工,北大文理醫,人大社科。一直以來在人們的印象中,人大是社科的巨無霸,但理工卻幾無存在感。
然而,在今年年初(1月19日),人民大學宣布成立了高瓴人工智能學院,并做如下定位:
“高瓴人工智能學院是學校下屬的二級學院,負責學校人工智能相關學科的規劃與建設,開展本學科領域的人才培養和科學研究工作……充分發揮學校在人工智能相關學科的已有優勢,建設世界一流的人工智能學科,提升學校的國際影響力和競爭力。”
高瓴人工智能學院的副院長張國富教授曾多次表示:“我們想和北面兩所學校(作者注:清、北)做不一樣的 AI。”
如何不一樣?人大有自己的考慮,我們可以先從科學方法范式的變革說起。
(以下部分內容借鑒了高瓴人工智能學院院長文繼榮教授11月19日的演講內容, 未經文繼榮院長本人確認,僅代表個人見解。)
在以往的數百年中,無論是自然科學還是社會科學,思考其研究方法的核心本質,總可以歸結為如下公式:

所有研究都只是為了從紛繁復雜的世界,從多變的樣本當中尋找出隱藏在表象背后的客觀規律,一個不變的、穩定的規律。特別是在自然科學領域,我們總希望能夠將客觀規律表示成一個模型或方程。
這種方法,本質上是一種科學主義傳統或者理性主義傳統,我們希望能夠從直覺或少量樣本中通過歸納、演繹等方法得出這樣的模型、函數或方程。一旦掌握了這樣的模型/函數/方程,我們就可以拿著它來解釋各種各樣看起來比較多變的現象,去分析無常的世界中那些穩定不變的東西。

在人類發展歷史上,尤其是在科學進程上,我們一直在各個領域探尋盡可能簡單優美的模型。這個模型越簡單,越優美,越具有普適性,我們就會覺得這個模型越好。
這種方法在自然科學領域取得了很大的成功,也已經成為現代社會最為核心的推動力。可以說今天生活中的方方面面都是這種思想指導下的科技所帶來的成果。
我們找到了自然中這樣的一些穩定的、不變的、客觀的規律。
但我們也應當注意到,在過去這么多年里,當我們把這種科學方法應用在社會科學當中時,我們發現了很多困難。例如我們用公式來描述經濟規律、預測股市等,常常會出現預測之外的結果。
這說明,這種方法在社會科學中并不適用。
原因在于,社會科學是一個復雜的、非線性的、(超)多變量的系統,通過小數據/直覺,往往難以揭示這樣系統背后真正的不變規律。
更重要的則在于,自然科學可以通過大量的實驗來收集大量數據,而社會科學則很難通過重復實驗來獲取數據,因此存在樣本數據稀少的情況。這也給人們留下了“社會科學并不科學”的印象。
大數據時代的出現,給我們提供一個前所未有的機會。我們突然有機會收集很多數據,尤其是在一些以前很難做實驗的場合來收集數據。我們發現當我們收集數據越來越多的時候,我們甚至可以不用去找數據背后隱藏的模型。

大數據提供了這樣一種方法,可以直接從輸入到輸出的映射,相當于是純經驗的方法。我們知道如果經驗足夠多,我們可以不用去尋找模型,繞開模型,直接用經驗解決問題。這是用大數據解決辦法的本質。
這種方法在很多領域已經取得成功,但是這個方法有一個問題,即,很多時候數據不夠多。很多情況下,你會發現你的數據不能覆蓋到所有的情況。
人工智能,是在大數據背景下出現的新方法:盡管問題很復雜,我還是能夠找到數據背后的模型,從而把握事物的不變性和規律性。它的方法與傳統方法的不同,它是從“海量的樣本數據”中尋求“復雜模型”。
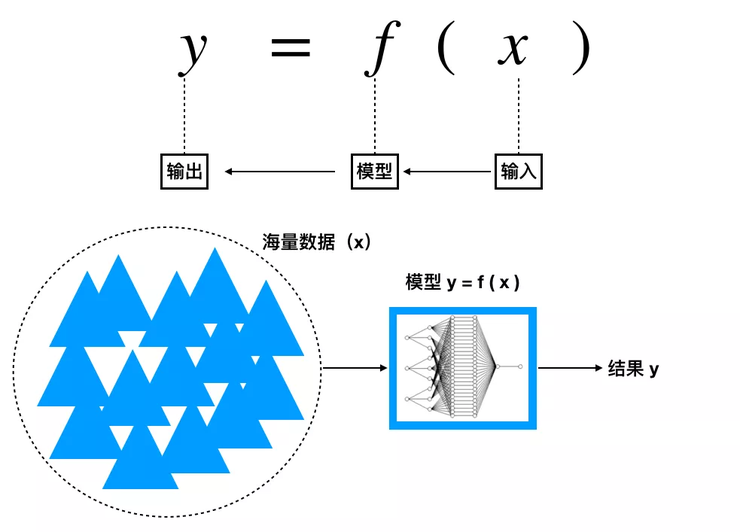
以前自然科學的方法是從少量的數據、少量的實驗樣本里面尋求簡單的模型,它可以用在自然科學方面,但是社會科學不可以,因為問題太復雜、變量太多。
但是現在有了基于大數據的人工智能方法,我們會發現可以從海量的數據里面尋求復雜的模型。
一個系統可能有幾千萬、幾十億的變量,背后可能是非常復雜的非線性問題,沒有關系,我們仍然可以構建出來這樣的模型。
深度學習,正是這種方法的代表,它能夠從海量數據中非常高效地學習出復雜模型。事實上,深度學習不僅僅只是去做人臉識別、自動駕駛,它對社會科學同樣有效,將之應用于社會科學,將產生顛覆性的革命。因為它給我們提供了一種有效的研究復雜問題的新方法。
這種新的科學范式就是:大數據+人工智能的研究范式。
深度神經網絡,可以理解為一個非常復雜的函數 f。在計算機視覺中,我們用它來表征建模人看見一個物體時發生了什么,現在我們在這方面已經取得了非常好的成績,在特定領域已經能夠超過人類的表現。
那么將這種方法應用到社會科學中會有什么不一樣的呢?
文繼榮教授舉了幾個例子:
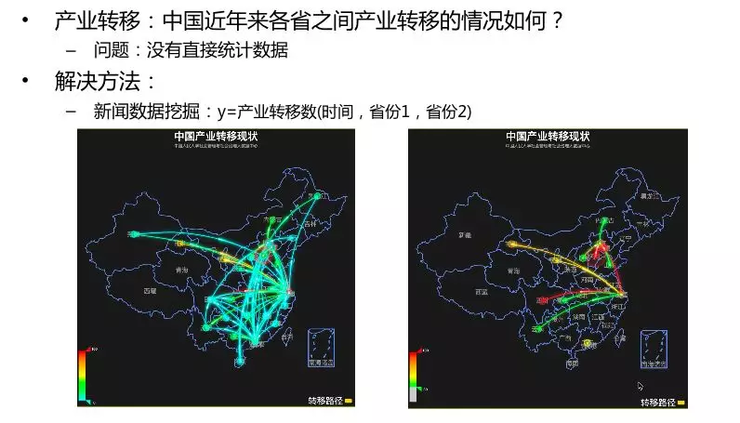
文繼榮介紹,他們從30萬條新聞中,將產業轉型的數據抽取出來。其中的 x 就是這 30萬的新聞數據,而通過建立模型,繪制除了如圖所示的產業轉移結果 y = 產業轉移數(時間,省份1,省份2)。把其中低頻的數據去掉后,得到右邊的圖。
從中便可以很容易地看出,中國的產業轉移是以北、上、廣為中心;而三地轉移情況卻各不相同,北京往周邊轉,上海往中東部轉,而廣州則仍然轉在本地。通過這種方式,便可以將原有的數據變得形象化、可視化,從而揭示出原來不可能發現的經濟規律。
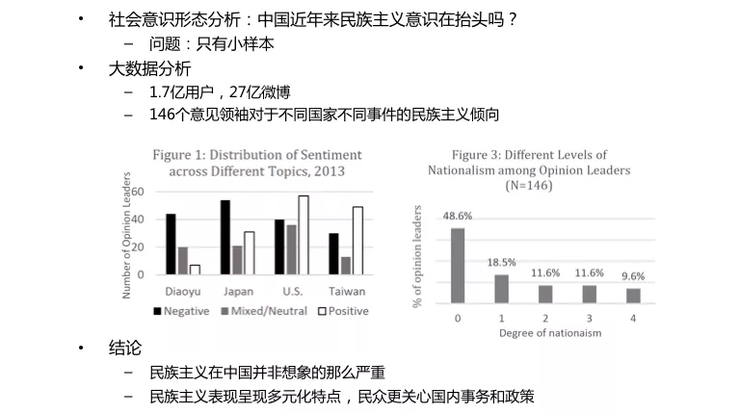
文繼榮繼續舉了與社科院合作的一個成果,研究意識形態問題。他們根據 1.7億用戶、27億的微博數據(其中有幾百萬的大V),發現很多有意思的現象。例如他們從微博數據中發現事實上中國近年來并沒有嚴重的民粹主義,且呈現民粹主義呈現多元化,民眾更關心國內事務和政策。

第三個例子是文繼榮在微軟期間的工作。2012年文繼榮通過公開的網絡數據來分析奧巴馬和羅姆尼的民意基礎,從而預測美國總統大選,結果相當準確。文繼榮打趣說,這個模型放到現在再去預測已經不準了,“因為美國水軍已經成長起來了”。

注:右側的災害分布圖來源于網絡,此處僅為示例
歷史,也同樣可以做。我們可以把史料數據化,通過各種方式來建模,比如說災害(水災、旱災、蝗災)在歷朝歷代是怎么發生的,產生什么樣的影響,跟人口出生、GDP、戰爭、瘟疫等等有什么關系等。我們可以把這些問題轉化成數據分析的問題來做,現在的技術已經可以做到,但距離真正的數據化歷史還很遙遠,這涉及到如何去構建一個龐大的技術平臺。

法律方面,文繼榮有頗多成果。舉例來講,如上圖,他們利用幾千萬法律文本判決書做了分析系統,輸入“黑社會”,就會得出如上圖右側的分布圖,其中顏色越深表示相應的案件越多。從中可以看出江西很特別,而東三省和大家想象的似乎不太一樣。
以上僅為部分社會學科與新范式科學方法的結合,且只是初步。實際上目前已經有很多人在作者相似的事情,很多社會科學研究也正受益于大數據 + 人工智能。
但目前這種方法在與各個學科結合的過程中仍然存在著一系列的問題。例如往往沒有直接數據,或者數據是以非結構化的文本形式而存在的。
此外,目前懂得使用這種技術的計算機專家并不懂得相應的社會科學,而反過來其他的領域專家往往又并不擅長對大數據和人工智能的利用。抽取什么數據來分析?分析什么問題?怎么分析?領域專家應當與計算機專家進行深度合作。
人大最不缺的就是社科領域專家。
這正是人大的優勢所在,也正是人大高瓴人工智能學院的優勢所在。
正如前面提到,高瓴人工智能學院若想“充分發揮學校在人工智能相關學科的已有優勢”,就必須與其他學院緊密協作。
在本月19日,在中國科協的支持下,由中國人民大學主辦了“首屆智能社會治理論壇”。
這次論壇的參與方包括中國科協-中國人民大學智能社會治理研究中心、中國人民大學國家發展與戰略研究院、中國人民大學文化科技園、民盟中國人民大學委員會、高瓴人工智能學院、經濟學院、法學院、社會與人口學院、新聞學院、勞動人事學院、未來法治研究院、新聞與社會發展研究中心等。
這次會議,事實上可以看做是人大高瓴人工智能學院與各個兄弟學院正式“結盟”的一次標志。
文繼榮作為高瓴人工智能學院院長,在會議上宣布了十個“智能社會治理的前沿問題”,作為他們在未來與兄弟學院共同合作的靶標。分別為:
第一個課題:智能社會治理大數據平臺建設(人工智能學院)。
第二個課題:智能社會治理的算法與機制設計(人工智能學院)。
第三個課題:是智能社會算法和數據的法律規制(法學院)。
第四個課題:智能社會互聯網平臺的法律責任(法學院)。
第五個課題:智能社會的經濟規制和競爭政策(經濟學院)。
第六個課題:智能社會數字經濟與中國經濟轉型(經濟學院)。
第七個課題:智能社會公共理性與輿論治理(新聞學院)。
第八個課題:智能社會公共倫理建設與規范(新聞學院)。
第九個課題,智能社會互聯網與人際關系重塑(社會與人口學院)。
第十個課題:智能社會秩序與智能化治理(社會與人口學院)。
從這個列表中,我們可以看出人大在人工智能的發展定位上,與清、北完全不同。人大更加強調人工智能技術與各個社會科學之間的結合,通過新的技術、新的研究范式來改變傳統的社會科學。在這個過程中,人工智能學院即是中心,又是邊緣。
或許我們可以認為,人大把 AI 技術視作為社會科學的「新數學」。
https://www.leiphone.com/news/201911/5enGTF6LCAB1oL4V.html
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





