溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在人工智能領域中的圖像分類問題上,最常用來訓練和測試的數據集是 ImageNet,它也是全球最大的“CV 習題庫”。近日,麻省理工學院和 IBM 研究人員組成的團隊,共同創建了一個與之不同的圖像識別數據集 ObjectNet,難倒了世界上最好的計算機視覺模型。
需要提示的是,這里的最好或最強指的不是某一個模型,而是一類高性能的視覺模型。
在 ImageNet 測試中實現準確率高達 97% 的計算機視覺模型,在 ObjectNet 數據集上檢測的準確率下降到了 50%-55%。測試結果如此“慘烈”,主要原因在于,目前幾乎所有的視覺模型,在類似于物體旋轉、背景變換、視角切換等復雜情境下,識別過程都缺乏穩定性。
麻省理工學院計算機科學與人工智能實驗室 (CSAIL) 和大腦、心智與機器中心 (CBMM) 的研究科學家 Andrei Barbu,是該研究的通訊作者,也是該項目的主持人之一。他在接受 DeepTech 專訪時表示,“我們需要一個數據集能夠具有典型意義地表示你在現實生活中看到的東西,沒有這個東西,誰還有信心做計算機視覺?我們怎么能說計算機視覺已經為黃金時代和關乎安全的關鍵應用做好了準備?”
Andrei Barbu 還表示,ObjectNet 可以向全球研究者分享,“只要聯系我們,我們將發送給你。”(網站: https://objectnet.dev/ )
 圖 | ImageNet(來源:ImageNet)
圖 | ImageNet(來源:ImageNet)
人工智能使用由神經元層組成的神經網絡在大量的原始數據中尋找規律。比如,在看過成百上千張椅子的照片之后,它學會了椅子的形狀。
斯坦福大學每年都會舉行一個比賽,邀請谷歌、微軟、百度等 IT 企業使用 ImageNet 測試他們的系統運行情況。每年一度的比賽也牽動著各大巨頭公司的心弦。
ImageNet 由世界上頂尖的計算機視覺專家李飛飛參與建立,她在一次演講中提到,要讓冰冷的機器讀懂照片背后的故事,就需要讓機器像嬰兒一樣看過足夠多的“訓練圖像”。
ImageNet 從 Flickr 和其他社交媒體網站上下載了接近 10 億張圖片,2009 年,ImageNet 項目誕生了,含有近 1500 萬張照片的數據庫, 涵蓋了 22000 種物品。
計算機視覺模型已經學會了精確地識別照片中的物體,以至于有些模型在某些數據集上表現得比人類還要好。
 圖 | ImageNet 創建者之一李飛飛(來源:Wikipedia)
圖 | ImageNet 創建者之一李飛飛(來源:Wikipedia)
但是,當這些模型真正進入到生活中時,它們的性能會顯著下降,這就給自動駕駛汽車和其他使用計算機視覺的關鍵系統帶來了安全隱患。
因為即使有成百上千張照片,也無法完全顯示物體在現實生活中可能擺出的方向和位置。椅子可以是倒在地上的,T 恤可能被掛在樹枝上,云可以倒映在車身上…… 這時候識別模型就會產生疑惑。
AI 公司 Vicarious 的聯合創始人 Dileep George 曾表示:“這表明我們在 ImageNet 上花費了大量資源來進行過擬合。”過度擬合是指過于緊密或精確地匹配特定數據集的結果,以致于無法擬合其他數據或預測未來的觀察結果。
與 ImageNet 隨意收集的照片不同,ObjectNet 上面提供的照片是有特殊背景和角度的,研究人員讓自由職業者為數百個隨機擺放的家具物品拍照,告訴他們從什么角度拍攝以及是擺在廚房、浴室還是客廳。
因此,數據集中的物品的拍攝角度非常清奇,側翻在床上的椅子、浴室中倒扣的茶壺、 掛在客廳椅背上的 T 恤……
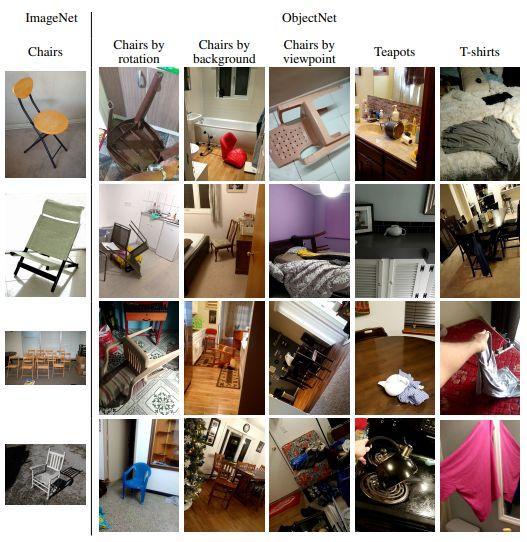
圖 | ImageNet(左欄)經常顯示典型背景上的對象,很少有旋轉,也很少有其他視角。典型的 ObjectNet 對象是從多個視點在不同的背景上進行映像的。前三列顯示了椅子的三個屬性:旋轉、背景和視角。可以看到由于這些操作而引入到數據集的大量變化。由于不一致的長寬比,此圖只略微裁剪了 ObjectNet 圖像。大多數檢測器對 ObjectNet 中包含的大多數圖像都識別失敗了(來源:論文)
麻省理工學院 CSAIL 和 CBMM 的研究科學家 Boris Katz 說:“我們創建這個數據集是為了告訴人們,物體識別問題仍然是個難題。”“我們需要更好、更智能的算法。”
Katz 和他的同事將在正在召開的 NeurIPS 會議上展示他們的成果,NeurIPS 是人工智能和機器學習領域的國際頂級會議。
 圖 | ObjectNet 研究團隊。這項研究由美國國家科學基金會,麻省理工學院大腦、心智和機器中心,麻省理工學院 - IBM 沃森人工智能實驗室,豐田研究所和 SystemsThatLearn@CSAIL 倡議資助(來源:ObjectNet)
圖 | ObjectNet 研究團隊。這項研究由美國國家科學基金會,麻省理工學院大腦、心智和機器中心,麻省理工學院 - IBM 沃森人工智能實驗室,豐田研究所和 SystemsThatLearn@CSAIL 倡議資助(來源:ObjectNet)
另外,ObjectNet 與傳統圖像數據集還有一個重要的區別:它不包含任何訓練圖像。也就是說,練習題和考試題重合的幾率變小了,機器很難“作弊”。大多數數據集都分為訓練集和測試集,但是訓練集通常與測試集有細微的相似之處,實際上是讓模型在測試中占了先機。
乍一看,ImageNet 有 1500 萬張圖片,似乎非常龐大。但是當去除掉訓練集部分時,它的大小與 ObjectNet 相當,差不多有 5 萬張照片。
“如果我們想知道算法在現實世界中的表現如何,我們應該在沒有偏見的圖像上測試它們,這些圖像應該是它們從未見過的,”Andrei Barbu 說。
圖 | 亞馬遜的“土耳其機器人”Amazon Mechanical Turk(MTurk)是一種眾包網絡集市,能使計算機程序員調用人類智能來執行目前計算機尚不足以勝任的任務。ImageNet 和 ObjectNet 都通過這些平臺來標記圖片(來源:Amazon Mechanical Turk)
研究人員說,結果表明,機器仍然很難理解物體是三維的,物體也可以旋轉和移動到新的環境中。“這些概念并沒有被構建到現代對象探測器的架構中,”研究的合著者、IBM 的研究員 Dan Gutfreund 說。
模型在 ObjectNet 上的測試結果如此“慘烈”,并不是因為數據量不夠,而是模型對類似于旋轉、背景變換、視角切換等等的認知缺乏穩定性。研究人員是如何得出這個結論的呢?他們讓模型先用 ObjectNet 的一半數據進行訓練,然后再用另一半數據進行測試。在相同的數據集上進行訓練和測試,通常可以提高性能,但是這次,模型只得到了輕微的改進,這表明模型沒有完全理解對象在現實世界中是如何存在的。
所以,研究人員認為,即使設計一個更大版本的、包含更多視角和方向的 ObjectNet,也不一定能教會人工智能理解物體的存在。ObjectNet 的目標是激勵研究人員提出下一波革命性的技術,就像最初推出的 ImageNet 挑戰一樣。他們下一步會繼續探究為何人類在圖像識別任務上具有良好的泛化能力和魯棒性,并希望這一數據集能夠成為檢驗圖像識別模型泛化能力的評估方法。
“人們向這些物體檢測器輸入了大量數據,但回報卻在遞減,”Katz 說。“你不可能把一個物體的每一個角度和每一個可能存在的環境都拍出來。我們希望這個新的數據集能夠在現實世界中催生出一個不會出現意外失敗的、強大的計算機視覺系統。”
 圖 | Andrei Barbu 是麻省理工學院研究科學家,主要研究語言、視覺和機器人技術,同時還涉獵神經科學。(來源:MIT)
圖 | Andrei Barbu 是麻省理工學院研究科學家,主要研究語言、視覺和機器人技術,同時還涉獵神經科學。(來源:MIT)
DeepTech 對該研究合作者、CSAIL 和 CBMM 的研究科學家 Andrei Barbu 進行了專訪(以下為不改變原意的采訪實錄):
DeepTech:這個構思是在什么時候產生的,目的是什么?現在可以下載使用了嗎?
Andrei Barbu:ObjectNet 是在大約 4 年前提出的。因為即使許多數據集 (如 ImageNet) 的準確率高達 95% 以上,但是在現實世界中的性能可能比你預期的要差得多。
我們的想法是將其他學科的優秀實驗設計直接引入機器學習,比如物理學和心理學。我們需要一個數據集能夠具有典型意義地表示你在現實生活中看到的東西,沒有這個東西,誰還有信心做計算機視覺?我們怎么能說計算機視覺已經為黃金時代和關乎安全的關鍵應用做好了準備?
ObjectNet 已經可以使用了,只要聯系我們,我們將發送給你。
DeepTech:收集實際數據用了多長時間?數據的有效性如何?
Andrei Barbu:我們花了大約 3 年的時間來弄清楚怎么做,花了大約 1 年的時間來收集數據。現在我們可以更快地收集另一個版本,時間跨度為幾個月。
我們在土耳其機器人上收集大約 10 萬張圖片,其中大約一半我們保存了下來。許多照片都是在美國以外的地方拍攝的,因此,有些物體可能看起來很陌生。成熟的橙子是綠色的,香蕉有不同的大小,衣服有不同的形狀和質地。
DeepTech:成本是多少?在收集數據時遇到了什么問題?
Andrei Barbu:在學術界,成本是復雜的。人力成本高于在土耳其機器人上的成本,單在土耳其機器人上的成本就很可觀。
收集這些數據遇到很多問題。這個過程很復雜,因為它需要在不同的手機上運行;指令很復雜,我們花了一段時間才真正理解如何以一種穩定的方式解釋這個任務;數據驗證也很復雜,小問題幾乎層出不窮。我們需要很多實驗來學習如何有效地做到這一點。
DeepTech:ObjectNet 與 Imagenet 的區別和聯系是什么?
Andrei Barbu:與 ImageNet 的不同之處在于:1、我們收集圖像的方式可以控制偏差。我們告訴人們如何旋轉物體,在什么背景中放置物體,以及在哪個角度拍照。在大多數的數據集中,圖像背景的信息會導致機器不自覺的“欺騙”,它們會憑借對于廚房背景的了解來預測某個東西可能是平底鍋。
2、這些照片不是從社交媒體上收集的,所以它們不是那種好看的照片,人們也不想分享。我們還確保收集來自印度、美國以及不同社會經濟階層的圖像。我們還有損壞或破碎物體的圖像。
3、沒有訓練集。
這在 10 年前并不是什么大問題,但我們的方法在發現模式方面是如此強大,以至于沒有人能夠識別,所以我們需要這些變化來避免簡單地調整我們的模型,以適應來自相同數據集的訓練和測試集之間的偏見。
DeepTech:沒有訓練集 會帶來什么影響?
Andrei Barbu:由于沒有訓練集,所有的方法都需要泛化。他們需要在一個數據集上進行培訓,并在 ObjectNet 上進行測試。這意味著他們利用偏差的可能性要小得多,而他們成為強大的目標探測器的可能性要大得多。我們想說服每個人,至少在機器學習的既定領域,收集訓練集的小組應該與收集測試集的小組分開。
由于我們已經成為一個數據驅動的研究領域,我們需要改變收集數據的方法,以推動科學的發展。
DeepTech:3D 對象太復雜了,我認為它很難表示。比如如何去表示旋轉的椅子?
Andrei Barbu:我不認為 3D 很復雜。
顯然你和我對物體的三維形狀有一定的認識,因為我們可以從新的角度想象物體。
我認為這也是計算機視覺的未來,ObjectNet 的設計就是在對這個存疑。它不關心你構建模型的基準,真正重要的是,它為你提供了一個更可靠的工具,用來檢測你的模型是不是足夠強。
DeepTech:你們接下來的研究計劃是什么?
Andrei Barbu:我們正在使用 ObjectNet 來理解人類的視覺。對人類在大規模物體識別方面的研究還不多,還有很多空白需要填補。我們將向成千上萬的在土耳其機器人上有短暫演示的人展示 ObjectNet,讓人們了解人類處理圖片的各個階段。
這也將有助于回答一些我們現在還不太了解的關于人類視覺和物體探測器之間關系的基本問題,比如,物體探測器的行為是否就像人類只能很快地看到一個物體?我們的初步結果表明,情況并非如此,這些差異可以用來建造更好的探測器。
我們還在開發下一個版本的 ObjectNet,我認為它對于檢測器來說會更加困難:帶有部分遮擋的 ObjectNet。對象將被其他對象部分覆蓋。我們和其他許多研究小組有理由懷疑探測器對有遮擋的物體的識別還不夠穩定,但是還需要一個嚴肅的基準來刺激下一波的進展。
https://zhuanlan.zhihu.com/p/97000888
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





