溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了如何分析用pt-stalk定位MySQL短暫的性能問題,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
【背景】
MySQL出現短暫的3-30秒的性能問題,一般的監控工具較難抓到現場,很難準確定位問題原因。
對于這類需求,我們日常的MySQL分析工具都有些不足的地方:
1、 性能監控工具,目前粒度是分鐘級,無法反應秒級的性能波動;
2、 MySQL Performance_schema工具采集是3秒落地10000行記錄,對于QPS大于3000以上的服務器采集會丟失數據;
Performance_schema數據通常用來分析語句級的性能問題,比如CPU高消耗,掃描行數等語句問題,對于系統內部mutex,lock,thread等資源競爭的問題無法定位。
3、 Table DML工具(5分鐘粒度)
4、 Slow Log記錄大于1秒的慢查詢,反應的可能是果,而不是因
5、 MySQL Guard工具實現是依賴報警系統觸發,一般對于持續在1分鐘以上的問題可以抓取到現場
前面擴展過一個功能,對高CPU的監控,粒度可以到10秒左右
pt-stalk工具可以解決更細粒度的故障現場采集,守護進程的方式試用了一下,可以幫助我們解決一些問題。
【pt-stalk工具的使用】
嘗試用pt-stalk工具做故障現場的快照采集
1、自定義腳本,定義CPU作為觸發條件
function trg_plugin(){
a=$(sar 1 1 | grep -i "Average:"| awk '{print $8}');echo 100 - $a |bc
}
2、用pt-stalk開啟守護進程,下面命令實現了用自定義的pt_cpu.sh腳本做為判斷條件,當CPU的值(100-%idle)大于50,判斷的間隔時間為1秒,連續3次滿足條件時觸發快照采集,觸發后會sleep 60秒
pt-stalk --daemonize --dest=/tmp/log/pt-stalk --user= --password= --port= --function=/tmp/pt_cpu.sh --variable highcpu --cycles=3 --interval=1 --threshold 50 --sleep=60 --log=/var/log/pt-stalk.log
具體的參數可參考man pt-stalk。
【案例分析】
有臺服務器出現短暫的線程和CPU告警的問題,現在每天在9點多都有CPU的告警,但持續時間較短,MySQL Guard工具很難采集到現場。
按照之前性能計數器反應的指標,猜測是由于binlog備份導致的IO上升,又導致了線程積壓,但實際不是這個原因,binlog備份時間重合只是巧合。
在這臺服務器開啟pt-stalk守護進程后,今天早上CPU告警時觸發了采集

抓取的快照信息如下:
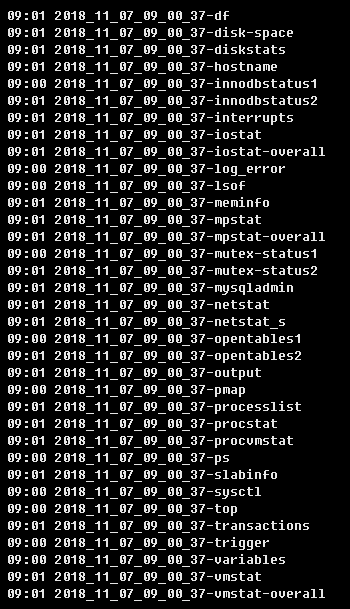
依據故障快照信息,再結合slow log和performance_schema語句明細,有足夠的信息可以定位出問題原因。
1、在9:01分CPU出現上升
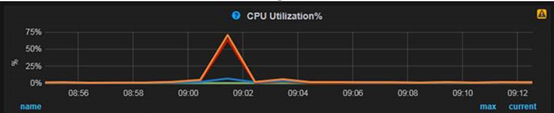
2、pt-stalk采集的CPU信息記錄了更細粒度,連續30秒的信息,其中連續30秒CPU sys占比都在80%以上,通常是并發線程較高,context switch過高導致的sys消耗

3、連續30秒的Threads_running確實比較高
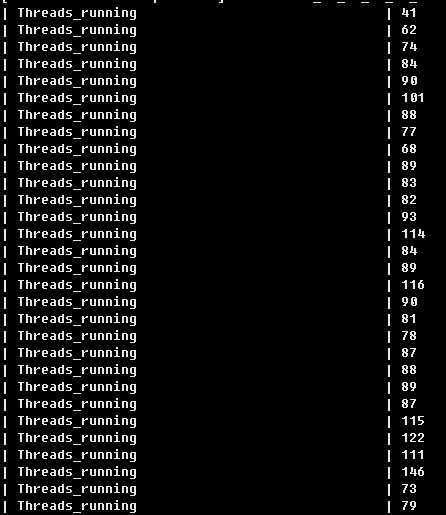
4、進一步分析,容易找到問題原因是由于每天9:00定時job運行,有一句高并發的慢查詢SQL導致了線程積壓
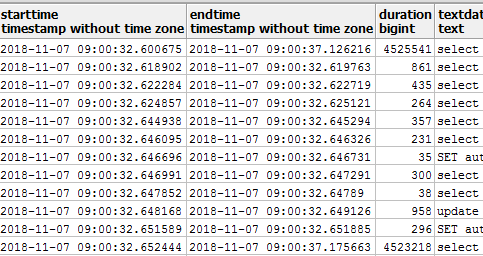
6、 慢查詢SQL是由于缺失索引導致,補建索引后再觀察
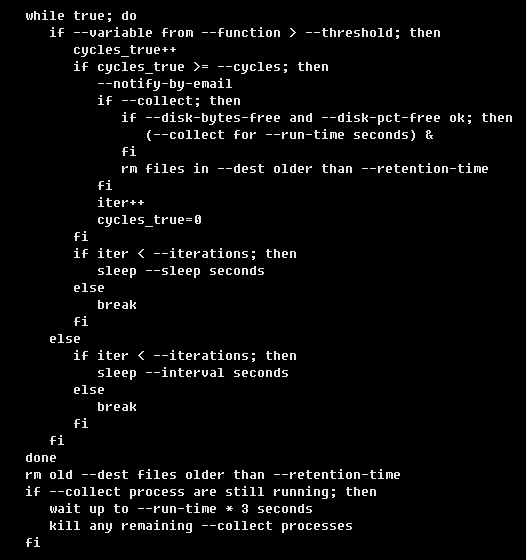
【pt-stalk的性能】
正常情況下守護進程的性能開銷并不大,建議可以在有需要排障時再定制開啟。下面是它的處理邏輯
上述內容就是如何分析用pt-stalk定位MySQL短暫的性能問題,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





