溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
上篇文章 《Eureka 緩存機制》 介紹了Eureka的緩存機制,相信大家對Eureka 有了進一步的了解,本文將詳細介紹API網關如何實現服務下線的實時感知。
在基于云的微服務應用中,服務實例的網絡位置都是動態分配的。而且由于自動伸縮、故障和升級,服務實例會經常動態改變。因此,客戶端代碼需要使用更加復雜的服務發現機制。
目前服務發現主要有兩種模式:客戶端發現和服務端發現。
服務端發現:客戶端通過負載均衡器向服務注冊中心發起請求,負載均衡器查詢服務注冊中心,將每個請求路由到可用的服務實例上。
客戶端發現:客戶端負責決定可用服務實例的網絡地址,并且在集群中對請求負載均衡, 客戶端訪問服務登記表,也就是一個可用服務的數據庫,然后客戶端使用一種負載均衡算法選擇一個可用的服務實例然后發起請求。
客戶端發現相對于服務端發現最大的區別是:客戶端知道(緩存)可用服務注冊表信息。如果Client端緩存沒能從服務端及時更新的話,可能出現Client 與 服務端緩存數據不一致的情況。
Netflix OSS 提供了一個客戶端服務發現的好例子。Eureka Server 為注冊中心,Zuul 相對于Eureka Server來說是Eureka Client,Zuul 會把 Eureka Server 端服務列表緩存到本地,并以定時任務的形式更新服務列表,同時zuul通過本地列表發現其它服務,使用Ribbon實現客戶端負載均衡。
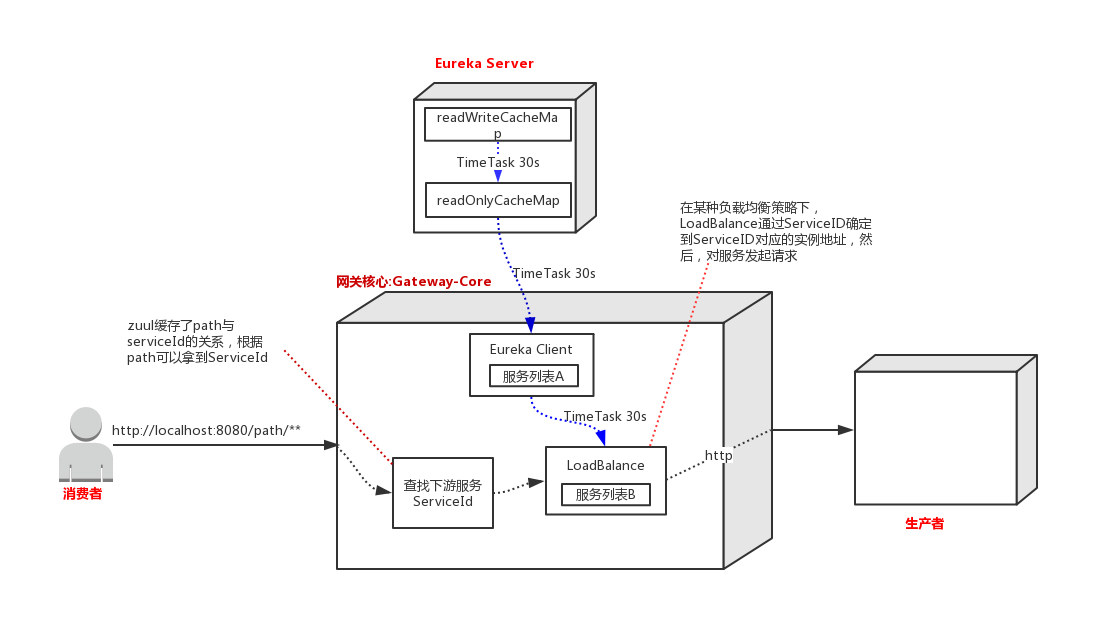
正常情況下,調用方對網關發起請求即刻能得到響應。但是當對生產者做縮容、下線、升級的情況下,由于Eureka這種多級緩存的設計結構和定時更新的機制,LoadBalance 端的服務列表B存在更新不及時的情況(由上篇文章 《Eureka 緩存機制》 可知,服務消費者最長感知時間將無限趨近240s),如果這時消費者對網關發起請求,LoadBalance 會對一個已經不存在的服務發起請求,請求是會超時的。
生產者下線后,最先得到感知的是 Eureka Server 中的 readWriteCacheMap,最后得到感知的是網關核心中的 LoadBalance。但是 loadBalance 對生產者的發現是在 loadBalance 本地維護的列表中。
所以要想達到網關對生產者下線的實時感知,可以這樣做:首先生產者或者部署平臺主動通知 Eureka Server, 然后跳過 Eureka 多級緩存之間的更新時間,直接通知 Zuul 中的 Eureka Client,最后將 Eureka Client 中的服務列表更新到 Ribbon 中。
但是如果下線通知的邏輯代碼放在生產者中,會造成代碼污染、語言差異等問題。
借用一句名言:
“計算機科學領域的任何問題都可以通過增加一個間接的中間層來解決”
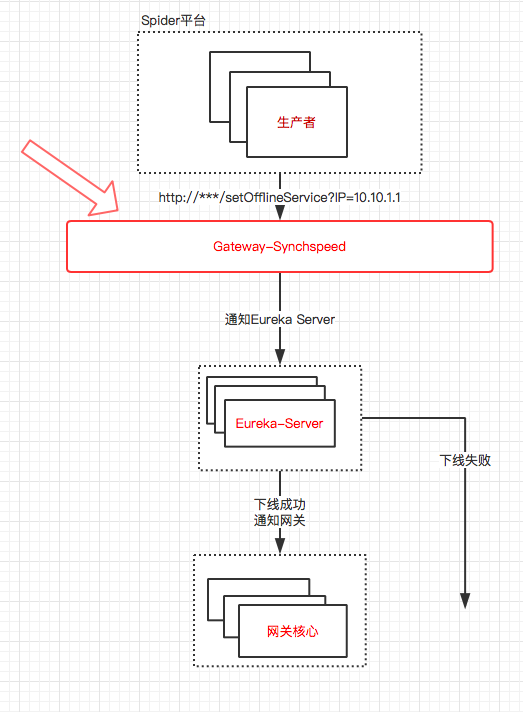
Gateway-SynchSpeed 相當于一個代理服務,它對外提供REST API來負責響應調用方的下線請求,同時會將生產者的狀態同步到 Eureka Server 和 網關核心,起著 狀態同步 和 軟事物 的作用。
思路 :在生產者做 縮容、下線、升級 前,spider 平臺(spider為容器管理平臺)會主動通知 Gateway-SynchSpeed 某個生產者的某個實例要下線了,然后 Gateway-SynchSpeed 會通知 Eureka Server 生產者的某個實例下線了;如果Eureka Server 下線成功,Gateway-SynchSpeed 會直接通知 網關核心。
設計特點
無侵入性、方便使用。不用關心調用方的基于何種語言實現,調用者只要對 Gateway-SynchSpeed 發起一個http rest請求即可,真正的實現邏輯不用侵入到調用方而是交給這個代理來實現。
原子性。調用方先在Eureka Server下線,然后在所有相關網關核心中下線為最小工作執行單元,Gateway-SynchSpeed 相當于一個"軟事物",保證服務下線的某種程度上原子特性。
步驟說明
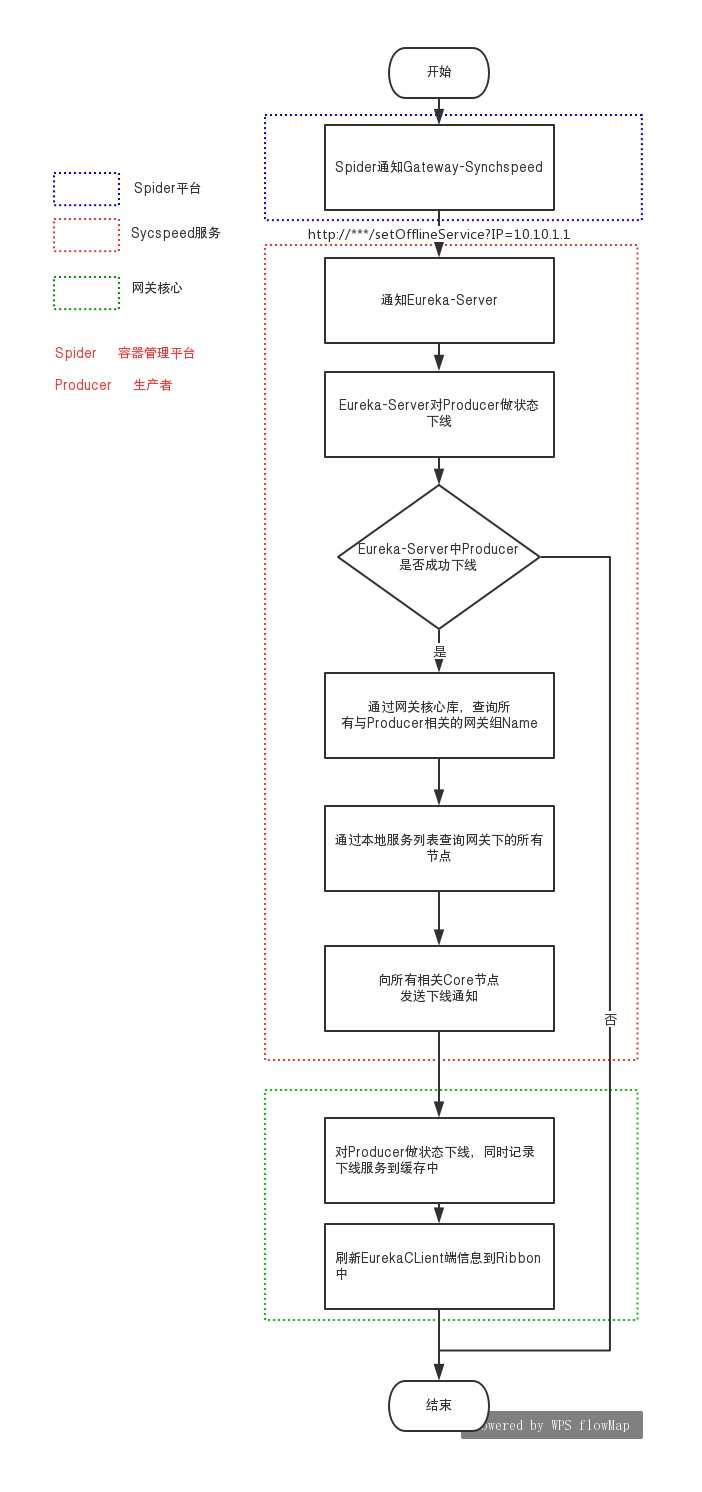
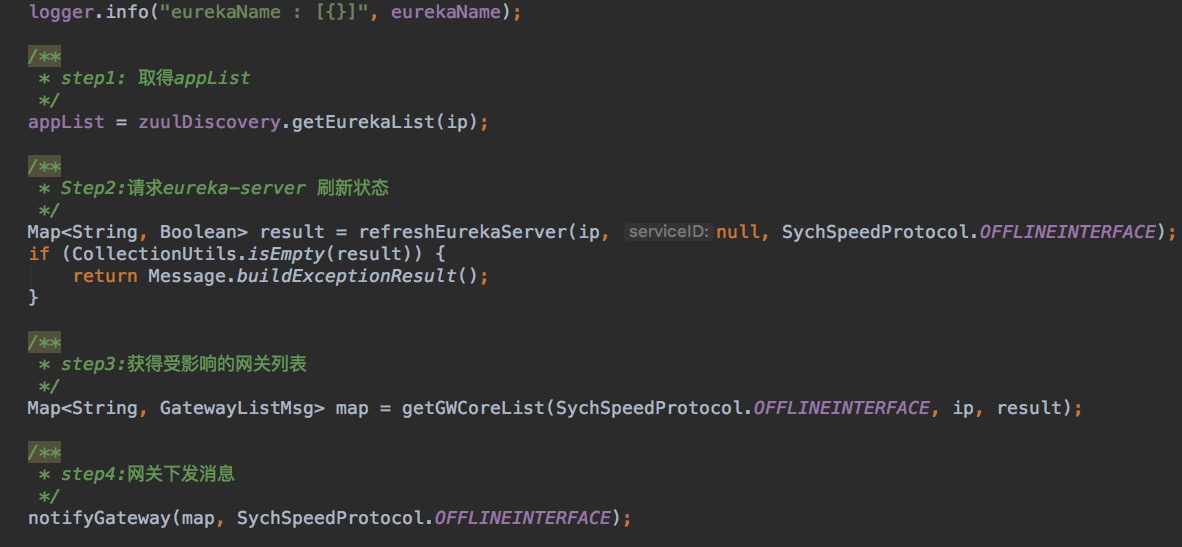
第一步:在生產者做 縮容、下線、升級 前,spider平臺會以http請求的形式通知到 Gateway-SynchSpeed 服務,通知的粒度為服務實例所在的容器IP。
第二步:Gateway-SynchSpeed 接受到請求后,先校驗IP的可用性,然后通知Eureka Server。
第三步:Eureka Server 將 Producer 置為失效狀態,并返回處理結果(Eureka 下線形式分為兩種,一種是直接從服務注冊列表直接剔除,第二種是狀態下線,即是將 Producer 的狀態置為
OUT_OF_SERVICE
。 如果是以第一種形式下線,Spider平臺發出下線請求后,不能保證Producer進程立刻被kill,如果這期間 Producer 還有心跳同步到 Eureka Server,服務會重新注冊到 Eureka Server)。
第四步:Gateway-SynchSpeed 得到上一步結果,如果結果為成功,則執行下一步;反之,則停止。
第五步:Gateway-SynchSpeed 為Eureka Client。Gateway-SynchSpeed 通過 IP 到本地服務注冊列表中得到 Producer 的 Application-Name。
第六步:Gateway-SynchSpeed 通過 Application-Name 到網關核心庫中查詢所有與下線服務相關的
網關組名字
。
第七步:Gateway-SynchSpeed 通過
網關組名字
到本地服務列表中查找網關組下所有的服務地址 ipAddress(ip : port)。
第八步:Gateway-SynchSpeed 異步通知所有相關網關節點。
第九步:Gateway-Core 收到通知后,對 Producer 做狀態下線,同時記錄所有狀態下線成功的實例信息到緩存 DownServiceCache 中。
第十步:Gateway-Core 更新本地 Ribbon 服務列表。
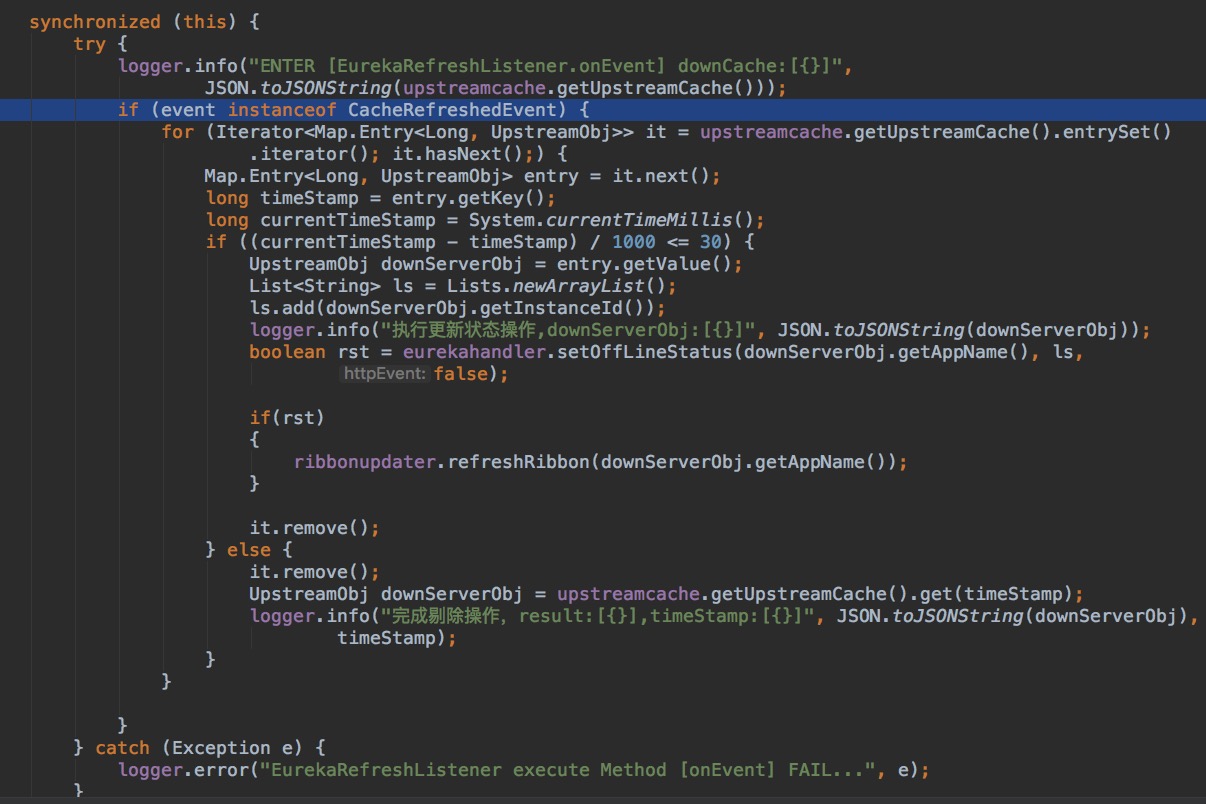
Eureka 提供了一種安全保護機制。Eureka Client 從 Eureka Server 更新服務列表前,會校驗相關Hash值是否改變( Client 服務列表被修改,hash值會改變),如果改變,更新方式會從增量更新變成全量更新,(由 《Eureka 緩存機制》 可知這30s內 readOnlyCacheMap 和 readWriteCacheMap 的數據可能存在差異),如果Client端緩存列表被readOnlyCacheMap 覆蓋,最終會導致 Ribbon 端服務列表與 readWriteCacheMap 數據不一致。
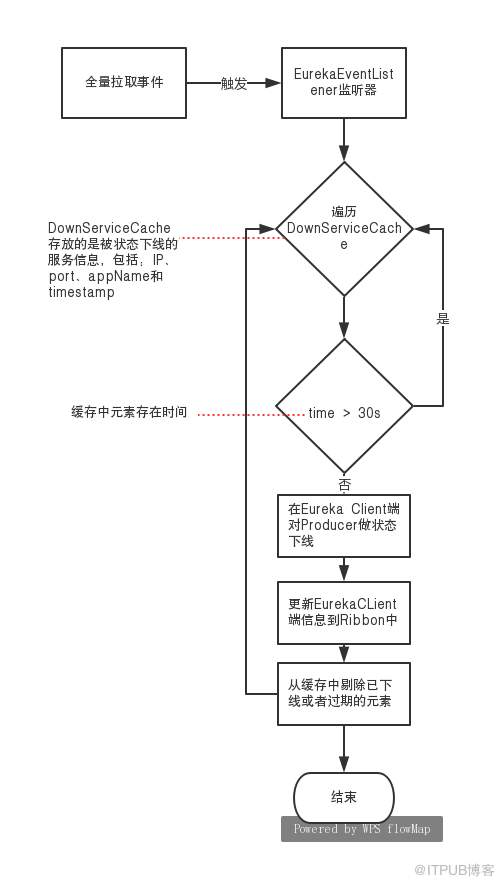
針對 Eureka 這種機制,引入監聽器 EurekaEventListener 作為補償機制,它會監聽 Eureka Client 全量拉取事件,對于緩存中未超過30s的服務,將其狀態重新設置成
OUT_OF_SERVICE
。
考慮到系統的安全性問題,如果被人惡意訪問,可能會使生產者在Eureka Server中無故下線,導致消費者無法通過 Eureka Server 來發現生產者。
使用黑白名單做安全過濾,基本流程如下:
對 Gateway-Synchspeed 中設置白名單網段(IP網段)
在 Gateway-Synchspeed 加入過濾器,對下線請求方進行IP校驗,如果請求端IP在網段中,則放行;反之,過濾。
由于 Gateway-SynchSpeed 和 Gateway-Core 是部署在 Docker 容器中,如果容器重啟,會導致日志文件全部丟失。所以需要將 Gateway-SynchSpeed 和 Gateway-Core 中相關日志寫入到 Elasticsearch ,最終由 Kibana 負責查詢 Elasticsearch 的數據并以可視化的方式展現。
Gateway-SynchSpeed 做狀態同步
EurekaEventListener 處理緩存數據
目前網關實現對服務下線的實時感知中,使用的 Zuul 和 Eureka 版本為 Spring Cloud Zuul 1.3.6.RELEASE 、Spring Cloud Eureka 1.4.4.RELEASE。
目前網關實現的是對網關下游服務的實時感知,而且需滿足以下條件:
生產者需部署在 kubernetes 容器管理平臺
生產者做正常的 下線、升級或者縮容 操作。如果是由于容器資源不足,導致服務異常宕機等非正常下線,不支持。
網關服務下線實時感知是網關對業務方提供的一種可選的解決方案,在 spider 平臺中默認是沒有開啟此功能,是否開啟此功能由業務方根據本身系統要求決定,具體如何配置可參考 API網關接入指南 中 《網關實時感知在spider上配置文檔說明》。
作者:謝國輝
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





