溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“服務器的高并發架構實例分析”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“服務器的高并發架構實例分析”吧!
業務從發展的初期到逐漸成熟,服務器架構也是從相對單一到集群,再到分布式服務。
一個可以支持高并發的服務少不了好的服務器架構,需要有均衡負載,數據庫需要主從集群,nosql緩存需要主從集群,靜態文件需要上傳cdn,這些都是能讓業務程序流暢運行的強大后盾。
服務器這塊多是需要運維人員來配合搭建,具體我就不多說了,點到為止。
大致需要用到的服務器架構如下:
服務器
均衡負載(如:nginx,阿里云SLB)
資源監控
分布式
數據庫
主從分離,集群
DBA 表優化,索引優化,等
分布式
nosql
cdn
html
css
js
image
高并發相關的業務,需要進行并發的測試,通過大量的數據分析評估出整個架構可以支撐的并發量。
測試高并發可以使用第三方服務器或者自己測試服務器,利用測試工具進行并發請求測試,分析測試數據得到可以支撐并發數量的評估,這個可以作為一個預警參考,俗話說知己自彼百戰不殆。
第三方服務:
阿里云性能測試
并發測試工具:
Apache JMeter
Visual Studio性能負載測試
Microsoft Web Application Stress Tool
日用戶流量大,但是比較分散,偶爾會有用戶高聚的情況;
場景: 用戶簽到,用戶中心,用戶訂單,等
服務器架構圖:

說明:
場景中的這些業務基本是用戶進入APP后會操作到的,除了活動日(618,雙11,等),這些業務的用戶量都不會高聚集,同時這些業務相關的表都是大數據表,業務多是查詢操作,所以我們需要減少用戶直接命中DB的查詢;優先查詢緩存,如果緩存不存在,再進行DB查詢,將查詢結果緩存起來。
更新用戶相關緩存需要分布式存儲,比如使用用戶ID進行hash分組,把用戶分布到不同的緩存中,這樣一個緩存集合的總量不會很大,不會影響查詢效率。
方案如:
用戶簽到獲取積分
計算出用戶分布的key,redis hash中查找用戶今日簽到信息
如果查詢到簽到信息,返回簽到信息
如果沒有查詢到,DB查詢今日是否簽到過,如果有簽到過,就把簽到信息同步redis緩存。
如果DB中也沒有查詢到今日的簽到記錄,就進行簽到邏輯,操作DB添加今日簽到記錄,添加簽到積分(這整個DB操作是一個事務)
緩存簽到信息到redis,返回簽到信息
注意這里會有并發情況下的邏輯問題,如:一天簽到多次,發放多次積分給用戶。
用戶訂單
這里我們只緩存用戶第一頁的訂單信息,一頁40條數據,用戶一般也只會看第一頁的訂單數據
用戶訪問訂單列表,如果是第一頁讀緩存,如果不是讀DB
計算出用戶分布的key,redis hash中查找用戶訂單信息
如果查詢到用戶訂單信息,返回訂單信息
如果不存在就進行DB查詢第一頁的訂單數據,然后緩存redis,返回訂單信息
用戶中心
計算出用戶分布的key,redis hash中查找用戶訂單信息
如果查詢到用戶信息,返回用戶信息
如果不存在進行用戶DB查詢,然后緩存redis,返回用戶信息
其他業務
上面例子多是針對用戶存儲緩存,如果是公用的緩存數據需要注意一些問題,如下
注意公用的緩存數據需要考慮并發下的可能會導致大量命中DB查詢,可以使用管理后臺更新緩存,或者DB查詢的鎖住操作。
以上例子是一個相對簡單的高并發架構,并發量不是很高的情況可以很好的支撐,但是隨著業務的壯大,用戶并發量增加,我們的架構也會進行不斷的優化和演變,比如對業務進行服務化,每個服務有自己的并發架構,自己的均衡服務器,分布式數據庫,nosql主從集群,如:用戶服務、訂單服務;
秒殺、秒搶等活動業務,用戶在瞬間涌入產生高并發請求
場景:定時領取紅包,等
服務器架構圖:
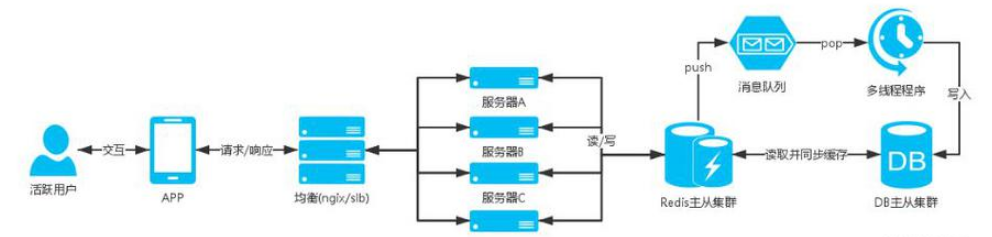
說明:
場景中的定時領取是一個高并發的業務,像秒殺活動用戶會在到點的時間涌入,DB瞬間就接受到一記暴擊,hold不住就會宕機,然后影響整個業務;
像這種不是只有查詢的操作并且會有高并發的插入或者更新數據的業務,前面提到的通用方案就無法支撐,并發的時候都是直接命中DB;
設計這塊業務的時候就會使用消息隊列的,可以將參與用戶的信息添加到消息隊列中,然后再寫個多線程程序去消耗隊列,給隊列中的用戶發放紅包;
方案如:
定時領取紅包
一般習慣使用 redis的 list
當用戶參與活動,將用戶參與信息push到隊列中
然后寫個多線程程序去pop數據,進行發放紅包的業務
這樣可以支持高并發下的用戶可以正常的參與活動,并且避免數據庫服務器宕機的危險
附加:
通過消息隊列可以做很多的服務。
如:定時短信發送服務,使用sset(sorted set),發送時間戳作為排序依據,短信數據隊列根據時間升序,然后寫個程序定時循環去讀取sset隊列中的第一條,當前時間是否超過發送時間,如果超過就進行短信發送。
高并發請求連接緩存服務器超出服務器能夠接收的請求連接量,部分用戶出現建立連接超時無法讀取到數據的問題;
因此需要有個方案當高并發時候時候可以減少命中緩存服務器;
這時候就出現了一級緩存的方案,一級緩存就是使用站點服務器緩存去存儲數據,注意只存儲部分請求量大的數據,并且緩存的數據量要控制,不能過分的使用站點服務器的內存而影響了站點應用程序的正常運行,一級緩存需要設置秒單位的過期時間,具體時間根據業務場景設定,目的是當有高并發請求的時候可以讓數據的獲取命中到一級緩存,而不用連接緩存nosql數據服務器,減少nosql數據服務器的壓力
比如APP首屏商品數據接口,這些數據是公共的不會針對用戶自定義,而且這些數據不會頻繁的更新,像這種接口的請求量比較大就可以加入一級緩存;
服務器架構圖:
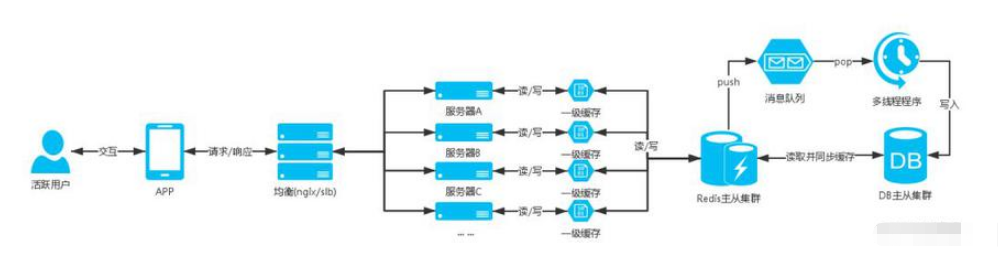
合理的規范和使用nosql緩存數據庫,根據業務拆分緩存數據庫的集群,這樣基本可以很好支持業務,一級緩存畢竟是使用站點服務器緩存所以還是要善用。
高并發請求數據不變化的情況下如果可以不請求自己的服務器獲取數據那就可以減少服務器的資源壓力。
對于更新頻繁度不高,并且數據允許短時間內的延遲,可以通過數據靜態化成JSON,XML,HTML等數據文件上傳CDN,在拉取數據的時候優先到CDN拉取,如果沒有獲取到數據再從緩存,數據庫中獲取,當管理人員操作后臺編輯數據再重新生成靜態文件上傳同步到CDN,這樣在高并發的時候可以使數據的獲取命中在CDN服務器上。
CDN節點同步有一定的延遲性,所以找一個靠譜的CDN服務器商也很重要
對于更新頻繁度不高的數據,APP,PC瀏覽器,可以緩存數據到本地,然后每次請求接口的時候上傳當前緩存數據的版本號,服務端接收到版本號判斷版本號與最新數據版本號是否一致,如果不一樣就進行最新數據的查詢并返回最新數據和最新版本號,如果一樣就返回狀態碼告知數據已經是最新。減少服務器壓力:資源、帶寬等.
分層,分割,分布式
大型網站要很好支撐高并發,這是需要長期的規劃設計
在初期就需要把系統進行分層,在發展過程中把核心業務進行拆分成模塊單元,根據需求進行分布式部署,可以進行獨立團隊維護開發。
分層
將系統在橫向維度上切分成幾個部分,每個部門負責一部分相對簡單并比較單一的職責,然后通過上層對下層的依賴和調度組成一個完整的系統
比如把電商系統分成:應用層,服務層,數據層。(具體分多少個層次根據自己的業務場景)
應用層:網站首頁,用戶中心,商品中心,購物車,紅包業務,活動中心等,負責具體業務和視圖展示
服務層:訂單服務,用戶管理服務,紅包服務,商品服務等,為應用層提供服務支持
數據層:關系數據庫,nosql數據庫 等,提供數據存儲查詢服務
分層架構是邏輯上的,在物理部署上可以部署在同一臺物理機器上,但是隨著網站業務的發展,必然需要對已經分層的模塊分離部署,分別部署在不同的服務器上,使網站可以支撐更多用戶訪問
分割
在縱向方面對業務進行切分,將一塊相對復雜的業務分割成不同的模塊單元
包裝成高內聚低耦合的模塊不僅有助于軟件的開發維護,也便于不同模塊的分布式部署,提高網站的并發處理能力和功能擴展
比如用戶中心可以分割成:賬戶信息模塊,訂單模塊,充值模塊,提現模塊,優惠券模塊等
分布式
分布式應用和服務,將分層或者分割后的業務分布式部署,獨立的應用服務器,數據庫,緩存服務器
當業務達到一定用戶量的時候,再進行服務器均衡負載,數據庫,緩存主從集群
分布式靜態資源,比如:靜態資源上傳cdn
分布式計算,比如:使用hadoop進行大數據的分布式計算
分布式數據和存儲,比如:各分布節點根據哈希算法或其他算法分散存儲數據
對于用戶訪問集中的業務獨立部署服務器,應用服務器,數據庫,nosql數據庫。 核心業務基本上需要搭建集群,即多臺服務器部署相同的應用構成一個集群,通過負載均衡設備共同對外提供服務, 服務器集群能夠為相同的服務提供更多的并發支持,因此當有更多的用戶訪問時,只需要向集群中加入新的機器即可, 另外可以實現當其中的某臺服務器發生故障時,可以通過負載均衡的失效轉移機制將請求轉移至集群中其他的服務器上,因此可以提高系統的可用性
應用服務器集群
nginx 反向代理
slb
… …
(關系/nosql)數據庫集群
主從分離,從庫集群
在高并發業務中如果涉及到數據庫操作,主要壓力都是在數據庫服務器上面,雖然使用主從分離,但是數據庫操作都是在主庫上操作,單臺數據庫服務器連接池允許的最大連接數量是有限的
當連接數量達到最大值的時候,其他需要連接數據操作的請求就需要等待有空閑的連接,這樣高并發的時候很多請求就會出現connection time out 的情況
那么像這種高并發業務我們要如何設計開發方案可以降低數據庫服務器的壓力呢?
如:
自動彈窗簽到,雙11跨0點的時候并發請求簽到接口
雙11搶紅包活動
雙11訂單入庫
等
設計考慮:
逆向思維,壓力在數據庫,那業務接口就不進行數據庫操作不就沒壓力了
數據持久化是否允許延遲?
如何讓業務接口不直接操作DB,又可以讓數據持久化?
方案設計:
像這種涉及數據庫操作的高并發的業務,就要考慮使用異步了
客戶端發起接口請求,服務端快速響應,客戶端展示結果給用戶,數據庫操作通過異步同步
如何實現異步同步?
使用消息隊列,將入庫的內容enqueue到消息隊列中,業務接口快速響應給用戶結果(可以溫馨提示高峰期延遲到賬)
然后再寫個獨立程序從消息隊列dequeue數據出來進行入庫操作,入庫成功后刷新用戶相關緩存,如果入庫失敗記錄日志,方便反饋查詢和重新持久化
這樣一來數據庫操作就只有一個程序(多線程)來完成,不會給數據帶來壓力
補充:
消息隊列除了可以用在高并發業務,其他只要有相同需求的業務也是可以使用,如:短信發送中間件等
高并發下異步持久化數據可能會影響用戶的體驗,可以通過可配置的方式,或者自動化監控資源消耗來切換時時或者使用異步,這樣在正常流量的情況下可以使用時時操作數據庫來提高用戶體驗
異步同時也可以指編程上的異步函數,異步線程,在有的時候可以使用異步操作,把不需要等待結果的操作放到異步中,然后繼續后面的操作,節省了等待的這部分操作的時間
緩存
高并發業務接口多數都是進行業務數據的查詢,如:商品列表,商品信息,用戶信息,紅包信息等,這些數據都是不會經常變化,并且持久化在數據庫中
高并發的情況下直接連接從庫做查詢操作,多臺從庫服務器也抗不住這么大量的連接請求數(前面說過,單臺數據庫服務器允許的最大連接數量是有限的)
那么我們在這種高并發的業務接口要如何設計呢?
設計考慮:
還是逆向思維,壓力在數據庫,那么我們就不進行數據庫查詢
數據不經常變化,我們為啥要一直查詢DB?
數據不變化客戶端為啥要向服務器請求返回一樣的數據?
方案設計:
數據不經常變化,我們可以把數據進行緩存,緩存的方式有很多種,一般的:應用服務器直接Cache內存,主流的:存儲在memcache、redis內存數據庫
Cache是直接存儲在應用服務器中,讀取速度快,內存數據庫服務器允許連接數可以支撐到很大,而且數據存儲在內存,讀取速度快,再加上主從集群,可以支撐很大的并發查詢
根據業務情景,使用配合客戶端本地存,如果我們數據內容不經常變化,為啥要一直請求服務器獲取相同數據,可以通過匹配數據版本號,如果版本號不一樣接口重新查詢緩存返回數據和版本號,如果一樣則不查詢數據直接響應
這樣不僅可以提高接口響應速度,也可以節約服務器帶寬,雖然有些服務器帶寬是按流量計費,但是也不是絕對無限的,在高并發的時候服務器帶寬也可能導致請求響應慢的問題
補充:
緩存同時也指靜態資源客戶端緩存
cdn緩存,靜態資源通過上傳cdn,cdn節點緩存我們的靜態資源,減少服務器壓力
面向服務
SOA面向服務架構設計
微服務更細粒度服務化,一系列的獨立的服務共同組成系統
使用服務化思維,將核心業務或者通用的業務功能抽離成服務獨立部署,對外提供接口的方式提供功能。
最理想化的設計是可以把一個復雜的系統抽離成多個服務,共同組成系統的業務,優點:松耦合,高可用性,高伸縮性,易維護。
通過面向服務化設計,獨立服務器部署,均衡負載,數據庫集群,可以讓服務支撐更高的并發
服務例子:
用戶行為跟蹤記錄統計
說明:
通過上報應用模塊,操作事件,事件對象,等數據,記錄用戶的操作行為
比如:記錄用戶在某個商品模塊,點擊了某一件商品,或者瀏覽了某一件商品
背景:
由于服務需要記錄用戶的各種操作行為,并且可以重復上報,準備接入服務的業務又是核心業務的用戶行為跟蹤,所以請求量很大,高峰期會產生大量并發請求。
架構:
nodejs WEB應用服務器均衡負載
redis主從集群
nodejs+express+ejs+redis+mysql
服務端采用nodejs,nodejs是單進程(PM2根據cpu核數開啟多個工作進程),采用事件驅動機制,適合I/O密集型業務,處理高并發能力強
業務設計:
并發量大,所以不能直接入庫,采用:異步同步數據,消息隊列
請求接口上報數據,接口將上報數據push到redis的list隊列中
nodejs寫入庫腳本,循環pop redis list數據,將數據存儲入庫,并進行相關統計Update,無數據時sleep幾秒
因為數據量會比較大,上報的數據表按天命名存儲
接口:
上報數據接口
統計查詢接口
上線跟進:
服務業務基本正常
每天的上報表有上千萬的數據
當高并發業務所在的服務器出現宕機的時候,需要有備用服務器進行快速的替代,在應用服務器壓力大的時候可以快速添加機器到集群中,所以我們就需要有備用機器可以隨時待命。 最理想的方式是可以通過自動化監控服務器資源消耗來進行報警,自動切換降級方案,自動的進行服務器替換和添加操作等,通過自動化可以減少人工的操作的成本,而且可以快速操作,避免人為操作上面的失誤。
冗余
數據庫備份
備用服務器
自動化
自動化監控
自動化報警
自動化降級
通過GitLab事件,我們應該反思,做了備份數據并不代表就萬無一失了,我們需要保證高可用性,首先備份是否正常進行,備份數據是否可用,需要我們進行定期的檢查,或者自動化監控, 還有包括如何避免人為上的操作失誤問題。(不過事件中gitlab的開放性姿態,積極的處理方式還是值得學習的)
到此,相信大家對“服務器的高并發架構實例分析”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





