溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
9月11日,螞蟻金服在 Google Developer Day Shanghai 2019 上宣布開源了基于 TensorFlow 2.0 eager execution 的分布式深度學習系統 ElasticDL。基于 TensorFlow 的支持彈性調度的深度學習系統,據我們所知,ElasticDL 是第一 個。項目負責人王益和我們分享了 ElasticDL 項目的設計意圖和現狀,尤其是 ElasticDL 與 TensorFlow 2.0 以及 Kubernetes 的技術關聯。
分布式深度學習的技術思路
基于 TensorFlow 的分布式訓練系統大致可以分為以下四類:

其中,ElasticDL 位于田字格的右上角。之所以選擇這條技術思路,是為了利用 Kubernetes 實現容錯和彈性調度。
高性能計算和云計算
在深度學習技術研發的早期,涉及的人員相對少,共用一個計算集群的人相對少, 計算作業之間的協調可以通過口頭交流實現。大家更關心縮短運行時間,也就是 從作業啟動到結束的這段時間。高性能計算技術(HPC)是解決這個問題的有效 途徑,比如 NVIDIA 的 cuBLAS 和 cuDNN 優化高性能數學計算、NCCL 優化 GPU 之間的通信效率。
隨著深度學習技術的大規模使用,很多工程師和研究員共用一個集群,通過商量 來協調調度顯然不可行了,大家開始使用集群管理系統調度分布式作業。這其中, Kubernetes 近年來一枝獨秀,已經在各大公有云中廣泛使用。
云計算和彈性調度
在 Kubernetes 上啟動分布式 TensorFlow 作業的常用方式是使用 Google Cloud 開源的 Kubeflow。Kubeflow 是 Kubernetes 的一個”插件“,它詢問 Kubernetes 計劃分配哪幾臺機器來運行一個分布式作業中的各個進程,隨后告 知每個進程,所有其他進程的 IP 地址和 port。從而保證一個作業里各個進程 之間互相知道對方。
為什么需要讓所有進程互相知道對方呢?這是 TensorFlow ps-based distribution 方式(上述表格中的左上)要求的。TensorFlow 1.x 原生的分布 式訓練功能讓一個作業中所有進程都執行 TensorFlow 1.x runtime 程序。這些 進程互相通信,互相協調成為一個“分布式 runtime“,來解釋執行表示深度學習 計算過程的計算圖(graph)。在開始分布式訓練之初,graph 被 TensorFlow runtime 拆解成若干子圖;每個進程負責執行一個子圖 —— 任何一個進程失敗 (可能是被更高優先級作業搶占),則整個大圖的執行就失敗了。所以 TensorFlow 原生的分布式訓練能力不是容錯的(fault-tolerant)。不過, 它是可以從錯誤恢復(fault-recoverable)—— TensorFlow API 提供 checkpoint 的能力;如果一個作業失敗了,可以重啟作業,從最近的 checkpoint 開始繼續執行。
Kubeflow 可以在 Kubernetes 上啟動基于 TensorFlow 原生的分布式計算能力的作業。但是 因為后者并不能容錯,所以 Kubeflow 并不能無中生有。不能容錯,也意味著不 能彈性調度。
對彈性調度的訴求
在很多人共用計算集群的情況下,支持彈性調度意味著極大提升團隊效率和集群 的總體利用率。前者支持快速迭代以保持技術領先;后者決定企業成本和云計算 業務的盈利能力。
一個展示彈性調度效果的例子如下。假設一個集群里有 N 個 GPU,一個作業包 括一個進程,占用了 N/2 個 GPU。第二個作業需要 N/2+1 個 GPU;但是此時機 群里空閑 GPU 只有 N/2 個。如果沒有彈性調度能力,那么第二個作業被迫等待, 直到第一個作業結束釋放資源。這個等待時間很可能和第二個作業的運行時間同 量級。此時,集群的利用率很低,是 50%。如果有彈性調度,那么第二個作業可 以馬上啟動,用 N/2 個 GPU 做計算。日后如果有更多空閑資源了,調度系統可 以增加其進程數量,充分利用資源。
另一個例子是,假設有一個作業已經在執行了,此時一個新的更高優先級的作業 需要資源,所以調度系統殺掉了(preempt)了第一個作業的幾個進程來騰出資 源啟動第二個作業。如果沒有彈性調度和容錯,那么第一個作業會失敗,所有進 程都結束。直到有足夠資源重啟它,并且沿著最近的 checkpoint 繼續。如果有 彈性調度,則第一個作業的剩下的進程可以繼續執行,只是因為可用的進程 (GPU)少了,所以速度慢一些而已。
以上兩個例子都展示了彈性調度對集群利用率的提升,以及對團隊工作效率的保 障。需要注意的是:容錯和彈性調度互為因果。容錯的意思是,作業不受其 中進程數量變化影響。彈性調度時,作業里的進程數量會隨集群 workload 情況 增減,所以作業必須是容錯的,才能和調度系統配合,實現彈性調度。也因為如 此,彈性調度依賴 分布式編程框架和調度系統配合。
今天,很多分布式編程框架都可以和 Kubernetes 配合實現容錯和彈性調度。比 如 用于離線數據處理的 Spark、用于在線數據處理的 Storm、在線 流數據引擎 Flink、分布式存儲系統 Redis 和 HBase。其中適合深度學習的框 架有 Paddle EDL。基于 TensorFlow 的支持彈性調度的深度學習系統,據我們 所知,ElasticDL 是第一個。
Kubernetes-native 的彈性調度
ElasticDL 通過實現一個 Kubernetes-native 的框架,調用 TensorFlow 2.0, 來實現彈性深度學習。
所謂 Kubernetes-native 指的是一個程序調用 Kubernetes API 來起止進程。 Google MapReduce 是一個 Borg-native 的分布式計算框架。用戶通過運行一個 Borg 的客戶端程度啟動一個 MapReduce 作業。Borg 客戶端調用 Borg API 提 交作業,并且啟動一個 master 進程。這個 master 調用 Borg API 啟動其他 workers 進程。ElasticDL 也類似,用戶調用 ElasticDL 的命令行客戶端程序 啟動作業。這個客戶端程序調用 Kubernetes API,啟動 master 進程。master 進程繼續調用 Kubernetes API 啟動其他進程。master 進程也可以調用 Kubernetes API 監控其他進程。
如果 worker 掛了,按照分布式深度學習訓練算法的數學特性,可以不用處理, 即可確保訓練過程繼續。如果一個 parameter server 進程掛了,master 會選 擇一個 worker 進程,讓它轉換角色替補上掛掉的 parameter server 進程。在 以上兩種情況下,master 都會調用 Kubernetes API,請它再啟動一個額外的 worker 進程。如果啟動成功,master 要帶它入門,加入到與其他進程的協作中。 master 進程的狀態(主要是三個 task queues:todo、doing、done)可以保留 在 Kubernetes 集群的 etcd 存儲系統中。這樣,萬一 master 掛了,重啟的 master 進程可以從 etcd 繼承前世的狀態。
以上是一個簡化的描述。 ElasticDL 實現了多種分布式計算模式,每種模式實 現 fault-tolerance 的方式略有不同。我們會在后續文章中詳細介紹。
Kubernetes-native 架構使得 master 進程有機會與 Kubernetes 協作實現容錯 和彈性調度。不過,因為 ElasticDL 調用 Kubernetes API,也就意味著 ElasticDL 只能運行在 Kubernetes 上。
TensorFlow 原生的分布式計算能力不是 Kubernetes-native 的。所以 TensorFlow 不是綁定在 Kubernetes 這個平臺上的。這是大家如果要用現有技 術在 Kubernetes 運行 TensorFlow 作業的話,需要依賴 Kubernetes 的擴展 Kubeflow 的原因。
理論上,不調用 Kubernetes API 也是可以實現一定程度的容錯的。即使沒有 Kubernetes 的通知,master 可以通過檢查其他繼承的心跳(heartbeat)或者 檢查 TCP 鏈接狀態,判斷其他進程的生死存亡。但是,不調用 Kubernetes API (或者其他調度系統的 API),master 無法通知調度系統重啟進程,也無法得 知新啟動的進程的信息,并且幫助它加入作業。這種“非 Kubernetes-native”的 容錯方式頗為被動,只能接受資源緊張時一些進程被搶占而掛掉的事實,而不能 在其他作業釋放資源后增加進程充分利用空閑資源。
TensorFlow 2.0
如上文解釋,為了保證 TensorFlow 最核心的 runtime 是平臺無關的,我們沒 法通過修改 runtime 實現完備的主動的容錯和彈性調度。所以如文首的田字格 所示,ElasticDL 和 Uber Horovod 都是在 TensorFlow 的 API 上包一 層。
Horovod 基于 TensorFlow 1.x。 一個 Horovod 作業的每個進程調用單機版 TensorFlow 做本地計算,然后收集 gradients,并且通過 AllReduce 調用匯聚 gradients 并且更新模型。Horovod 也是平臺無關的,所以它提供的 AllReduce 操作不支持容錯和彈性調度。這一點和 ElasticDL 不一樣。
和 ElasticDL 一樣的是,Horovod 需要從 TensorFlow 偷偷“截獲” gradients, 在 TensorFlow 1.x 中,深度學習計算是表示成一個計算圖(graph),并且由 TensorFlow runtime 解釋執行,所以 Horovod 為了獲得每個進程算的 gradients 并且 AllReduce 它們,就得 hack 進入圖執行的過程。為此, Horovod 要求使用者使用特定的 optimizer 代替 TensorFlow 提供的 optimizer,從而可以在優化模型階段透露出 gradients。
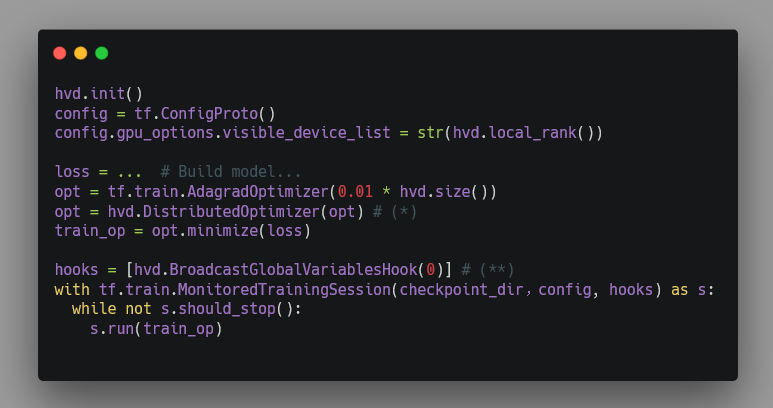
一個調用 Horovod 的用戶程序的結構如下。其中標記為 (*) 和 (**) 的部 分是 Horovod 要求用戶寫的,幫助 Horovod 截獲 TensorFlow 計算得到的 gradients 的代碼。如果用戶不慎忘記寫了,那么程序執行結果就不對了。
ElasticDL 沒有這些問題,因為它依賴的是 TensorFlow 2.0。TensorFlow 2.0 主推的 eager execution mode 采用和解釋執行圖完全不同的深度學習計算方式。 類似 PyTorch 的做法,前向計算過程把對基本計算單元(operator)的調用記 錄在一個內存數據結構 tape 里,隨后,反向計算過程(計算 gradients 的) 可以回溯這個 tape,以此調用 operator 對應的 gradient operator。這個 tape 提供一個操作讓用戶可以獲取每個參數的 gradient。
ElasticDL 通過調用 TensorFlow 2.0 API 可以很直接地獲取 gradients:
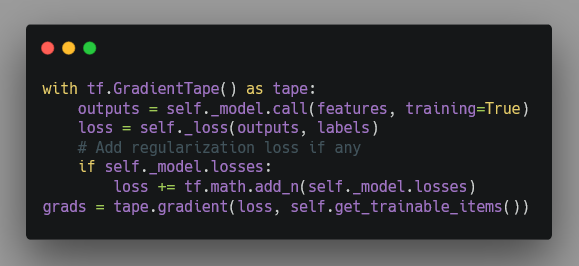
而且上面這段代碼不是需要用戶寫的,而是 ElasticDL 的一部分。ElasticDL 用戶需要寫的代碼對應上述 Horovod 代碼范例中的一行 —— 定義模型。
極簡的 API 和使用方式
訓練一個模型不只需要上述模型定義,還需要指定數據、優化目標(cost)、和 優化算法(optimizer)。用戶總是希望能以盡量精簡的方式指定這些信息,以 盡量少的代碼描述訓練作業。
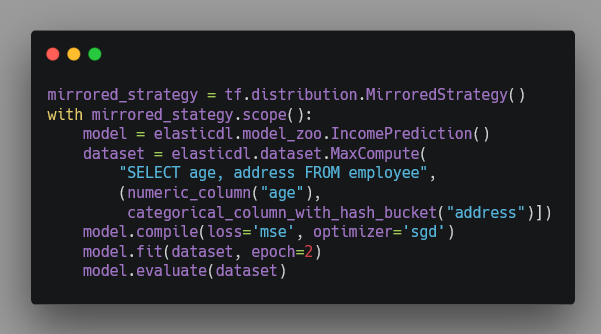
ElasticDL 和 TensorFlow 其他的 high-level API,例如 Keras 和 TensorFlow Estimator 一樣, 幾乎調用一個 API 函數就可以執行一個分布式訓練作業。下 面這個程序使用 Keras。Keras 使用 TensorFlow 原生分布式訓練能力,不支持容 錯和彈性調度。
ElasticDL 的 API 相對更加精簡一些。上述范例程序對應的 ElasticDL 版本如下:
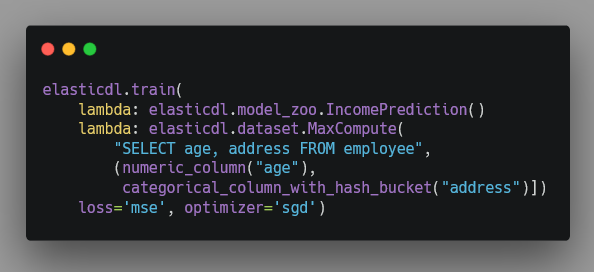
主要的區別在于:在 Keras 程序里用戶要選擇分布式執行策略;而在 ElasticDL 程序里則不需要。這是因為 ElasticDL 自動選擇分布式訓練算法和 策略。
簡單的說,對于有很大參數(需要 model parallelism)的模型,ElasticDL 使 用 asynchrnous SGD。這個方法配合 delayed model update 能把網絡通信量減 少一個數量級。很多 NLP、搜索、推薦、廣告的模型都符合這一類。 Asynchronous SGD 對于這類模型的表現比較穩定。對于圖像識別和語音識別這 一類參數不太大的模型,ElasticDL 團隊在開發一個 Kubernetes-native 的 AllReduce。和 Horovod 使用的 AllReduce 一樣,ElasticDL AllReduce 把進 程間通信的拓撲組織成一個環,從而實現高性能的模型更新。與之不同的是, ElasticDL AllReduce 是容錯的 —— 在有進程失敗導致 AllReduce 調用失敗的 情況下,master 組織剩下的活著的進程構造一個新的環。
ElasticDL 項目希望通過這樣的分而治之的策略,提供高性能并且易用的深度學習系統。
ElasticDL 和 SQLFlow 的關系
今年早些時候,王益團隊 開源了 SQLFlow。用戶可以 用擴展后的 SQL 語法,非常精煉地描述整個數據流和 AI 流程。
比如,如果我們要為一個電子商務網站構造一個推薦系統,需要開發日志收集、 在線數據清洗、特征工程、模型訓練,驗證和預測等模塊。每個模塊可能需要投 入一個團隊數軸甚至數月的時間。
最近幾年里,很多互聯網服務開始把數據直接上傳到通用數據庫中,比如螞蟻金 服的很多數據是在 ODPS(也就是阿里云上的 MaxCompute 服務)以及新一代的 智能數據系統 。這促使我們考慮把數據清洗和預處理放在數據庫中做,而特征工程、自動機器 學習、和訓練過程在 ElasticDL 這樣的 AI 引擎里做。SQLFlow 把擴展語法的 SQL 程序翻譯成一個 Python 程序,把兩部分鏈接起來。
在這樣的場景中,如果 AI 需要很多參數,則用戶也就需要在 SQL 程序中提供 這些參數。比如下面 SQL 語句從數據庫中提取用戶的年齡、工作部門、和工作 地點,來預測其收入。
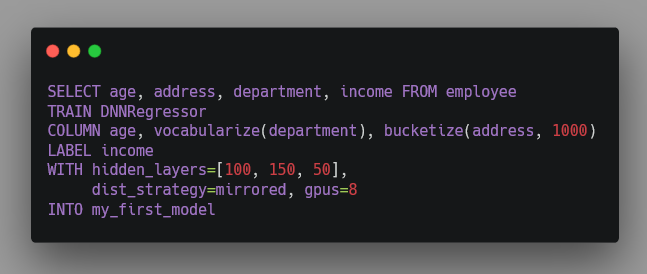
其中,TRAIN 從句指定要訓練的模型;COLUMN 從句指定如何把數據映射成 特征;LABEL 指定要預測的值;WITH 指定訓練過程中的各種參數,其中 dist_strategy 是調用 Keras/TensorFlow 做訓練是需要指定的分布式策略, gpus 指定需要的資源。而這些,在 SQLFlow 調用 ElasticDL 的時候都是不 需要的,因為 ElasticDL 自動選擇分布式策略和算法。
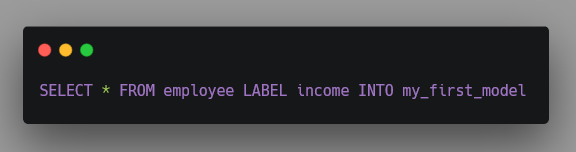
從這個例子可以看出,如果要讓用戶能提供盡量少的參數,人工智能引擎還需要 更加智能,提供包括 AutoML 和 自動特征工程 的功能。 ElasticDL 項目任重道遠。我們期待把上述 SQL 程序簡化為如下形式:
ElasticDL 項目的現狀
ElasticDL 項目處于早期探索階段。API 還在演化過程中。這次開源的版本,尚 不包括自動選擇分布策略和算法的代碼。相比在 TensorFlow runtime 中實現分 布式計算,基于 TensorFlow 2.0 eager mode 的 Python API 實現的分布式訓 練性能差距還很大。ElasticDL 團隊在和 Google Brain 團隊合作,開發上述 asynchronous SGD + delayed model update 能力、以及 Kubernetes-native AllReduce。希望在下一個版本中可以提供給大家使用。
目前 ElasticDL 實現的基于 parameter server 的分布式SGD 訓練方法驗證了 容錯和彈性調度。并且在 Google Cloud 上的 Kubernetes 1.12 集群和阿里 Sigma 3.1(一個 Kubernetes 的高性能實現)上都可以運行。并且,ElasticDL 團隊開發了 SQLFlow 生成 ElasticDL 程序的 code generator。
我們希望盡早開源 ElasticDL 和盡早分享其設計意圖,能匯聚來自不同公司和 社區的力量,一起探索 Google TensorFlow 2.0 和 Kubernetes 的分布式訓練 生態,早日實現便捷的端到端的人工智能開發套件。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





