溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前言
最近高德地圖APP完成了一次啟動優化專項,超預期將雙端啟動的耗時都降低了65%以上,iOS在iPhone7上速度達到了400毫秒以內。就像產品們用后說的,快到不習慣。算一下每天為用戶省下的時間,還是蠻有成就感的,本文做個小結。

(文中配圖均為多才多藝的技術哥哥手繪)
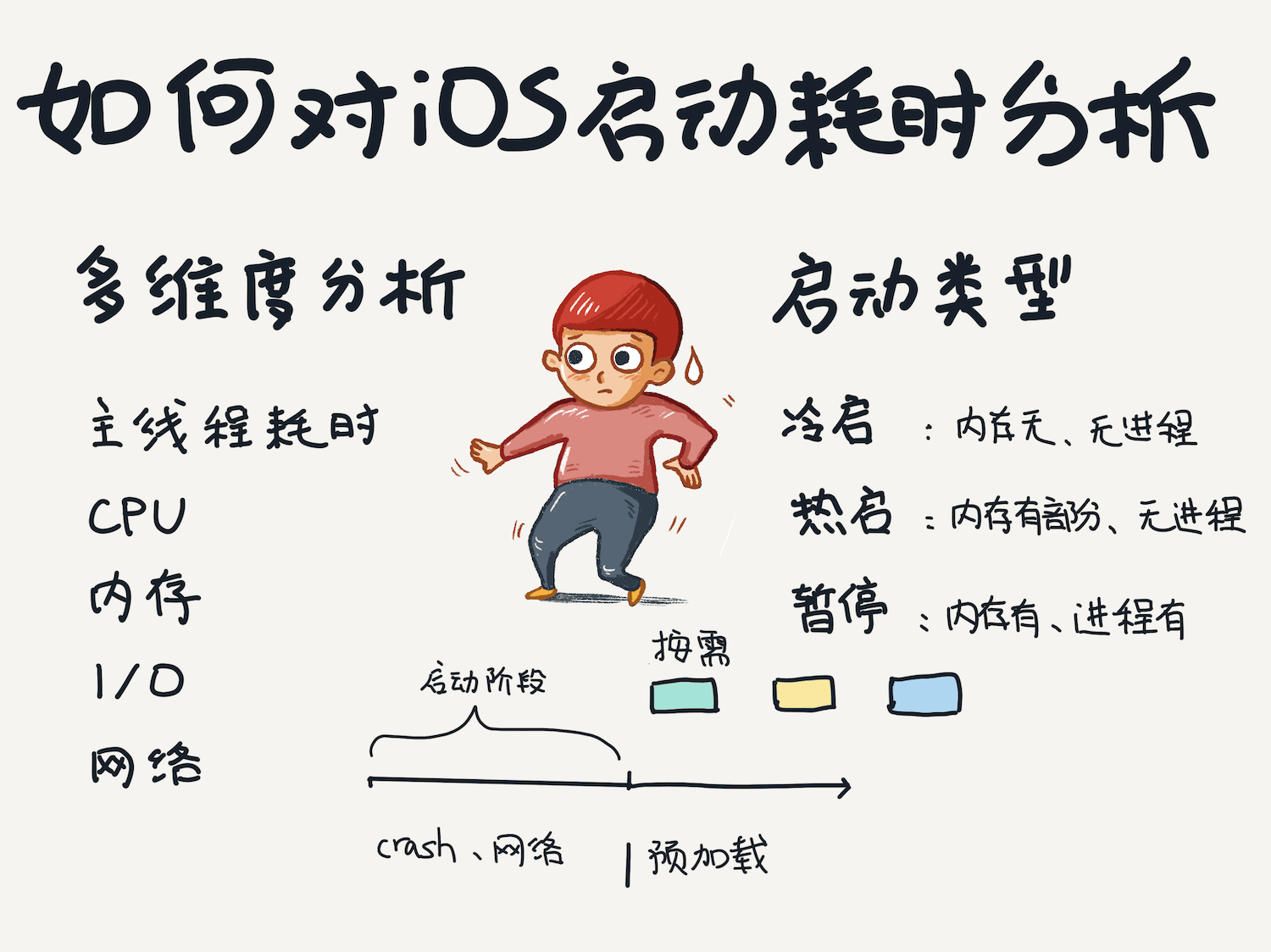
啟動階段性能多維度分析
要優化,首先要做到的是對啟動階段的各個性能緯度做分析,包括主線程耗時、CPU、內存、I/O、網絡。這樣才能更加全面的掌握啟動階段的開銷,找出不合理的方法調用。
啟動越快,更多的方法調用就應該做成按需執行,將啟動壓力分攤,只留下那些啟動后方法都會依賴的方法和庫的初始化,比如網絡庫、Crash庫等。而剩下那些需要預加載的功能可以放到啟動階段后再執行。
啟動有哪幾種類型,有哪些階段呢?
啟動類型分為:
分析階段一般都是針對Cold類型進行分析,目的就是要讓測試環境穩定。為了穩定測試環境,有時還需要找些穩定的機型,對于iOS來說iPhone7性能中等,穩定性也不錯就很適合,Android的Vivo系列也相對穩定,華為和小米系列數據波動就比較大。
除了機型外,控制測試機溫度也很重要,一旦溫度過高系統還會降頻執行,影響測試數據。有時候還會設置飛行模式采用Mock網絡請求的方式來減少不穩定的網絡影響測試數據。最好是重啟后退iCloud賬號,放置一段時間再測,更加準確些。
了解啟動階段的目的就是聚焦范圍,從用戶體驗上來確定哪個階段要快,以便能夠讓用戶可視和響應用戶操作的時間更快。
簡單來說iOS啟動分為加載Mach-O和運行時初始化過程,加載Mach-O會先判斷加載的文件是不是Mach-O,通過文件第一個字節,也叫魔數來判斷,當是下面四種時可以判定是Mach-O文件:
Mach-O主要分為:
確定是Mach-O后,內核會fork一個進程,execve開始加載。檢查Mach-O Header。隨后加載dyld和程序到Load Command地址空間。通過 dyld_stub_binder開始執行dyld,dyld會進行rebase、binding、lazy binding、導出符號,也可以通過DYLD_INSERT_LIBRARIES進行hook。
dyld_stub_binder給偏移量到dyld解釋特殊字節碼Segment中,也就是真實地址,把真實地址寫入到la_symbol_ptr里,跳轉時通過stub的jump指令跳轉到真實地址。dyld加載所有依賴庫,將動態庫導出的trie結構符號執行符號綁定,也就是non lazybinding,綁定解析其他模塊功能和數據引用過程,就是導入符號。
Trie也叫數字樹或前綴樹,是一種搜索樹。查找復雜度O(m),m是字符串的長度。和散列表相比,散列最差復雜度是O(N),一般都是 O(1),用 O(m)時間評估 hash。散列缺點是會分配一大塊內存,內容越多所占內存越大。Trie不僅查找快,插入和刪除都很快,適合存儲預測性文本或自動完成詞典。
為了進一步優化所占空間,可以將Trie這種樹形的確定性有限自動機壓縮成確定性非循環有限狀態自動體(DAFSA),其空間小,做法是會壓縮相同分支。
對于更大內容,還可以做更進一步的優化,比如使用字母縮減的實現技術,把原來的字符串重新解釋為較長的字符串;使用單鏈式列表,節點設計為由符號、子節點、下一個節點來表示;將字母表數組存儲為代表ASCII字母表的256位的位圖。
盡管Trie對于性能會做很多優化,但是符號過多依然會增加性能消耗,對于動態庫導出的符號不宜太多,盡量保持公共符號少,私有符號集豐富。這樣維護起來也方便,版本兼容性也好,還能優化動態加載程序到進程的時間。
然后執行attribute的constructor函數。舉個例子:
#include <stdio.h>__attribute__((constructor))static void prepare() {
printf("%s\n", "prepare");
}
__attribute__((destructor))static void end() {
printf("%s\n", "end");
}void showHeader() {
printf("%s\n", "header");
}運行結果:
ming@mingdeMacBook-Pro macho_demo % ./main "hi"prepare hi end
運行時初始化過程分為:
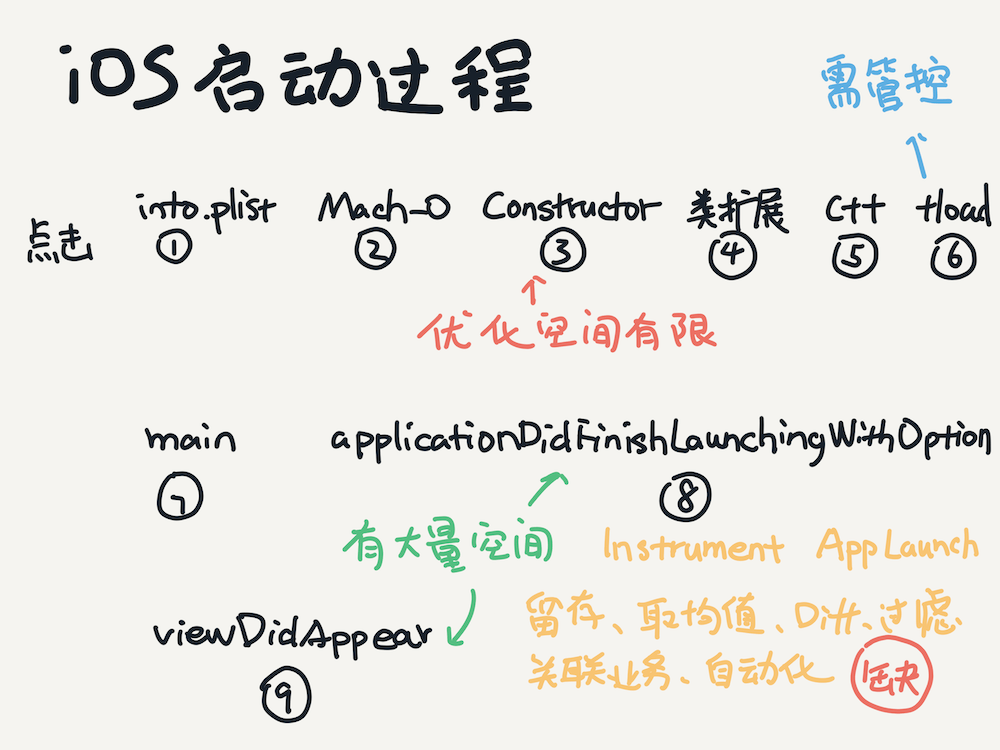
也就是說對啟動階段的分析以viewDidAppear為截止。這次優化之前已經對Application初始化之前做過優化,效果并不明顯,沒有本質的提高,所以這次主要針對Application初始化到viewDidAppear這個階段各個性能多緯度進行分析。
工具的選擇其實目前看來是很多的,Apple提供的System Trace會提供全面系統的行為,可以顯示底層系統線程和內存調度情況,分析鎖、線程、內存、系統調用等問題。總的來說,通過System Trace能清楚知道每時每刻APP對系統資源的使用情況。
System Trace能查看線程的狀態,可以了解高優線程使用相對于CPU數量是否合理,可以看到線程在執行、掛起、上下文切換、被打斷還是被搶占的情況。虛擬內存使用產生的耗時也能看到,比如分配物理內存,內存解壓縮,無緩存時進行緩存的耗時等。甚至是發熱情況也能看到。
System Trace還提供手動打點進行信息顯式,在你的代碼中導入sys/kdebug_signpost.h后,配對kdebug_signpost_start和kdebug_signpost_end就可以了。這兩個方法有五個參數,第一個是id,最后一個是顏色,中間都是預留字段。
Xcode11開始XCTest還提供了測量性能的Api。蘋果在2019年WWDC啟動優化專題:
https://developer.apple.com/videos/play/wwdc2019/423/
也介紹了Instruments里的最新模板App launch如何分析啟動性能。但是要想達到對啟動數據進行留存取均值、Diff、過濾、關聯分析等自動化操作,App launch目前還沒法做到。
下面針對主線程耗時、CPU、網絡、內存、I/O 等多維度進行分析:

多個緯度性能分析中最重要、最終用戶體感到的是主線程耗時分析。對主線程方法耗時可以直接使用Massier,這是everettjf開發的一個Objective-C方法跟蹤工具:
https://everettjf.github.io/2019/05/06/messier/
生成trace json進行分析,或者參看這個代碼
GCDFetchFeed/SMCallTraceCore.c at master · ming1016/GCDFetchFeed · GitHub
https://github.com/ming1016/GCDFetchFeed/blob/master/GCDFetchFeed/GCDFetchFeed/Lib/SMLagMonitor/SMCallTraceCore.c
自己手動hook objc_msgSend生成一份Objective-C方法耗時數據進行分析。還有種插樁方式,可以解析IR(加快編譯速度),然后在每個方法前后插入耗時統計函數。
文章后面我會著重介紹如何開發工具進一步分析這份數據,以達到監控啟動階段方法耗時的目的。
hook所有的方法調用,對詳細分析時很有用,不過對于整個啟動時間影響很大,要想獲取啟動每個階段更準確的時間消耗還需要依賴手動埋點。
為了更好的分析啟動耗時問題,手動埋點也會埋的越來越多,也會影響啟動時間精確度,特別是當團隊很多,模塊很多時,問題會突出。但是每個團隊在排查啟動耗時往往只會關注自己或相關某幾個模塊的分析,基于此,可以把不同模塊埋點分組,靈活組合,這樣就可以照顧到多種需求了。
為什么分析啟動慢除了分析主線程方法耗時外,還要分析其它緯度的性能呢?
我們先看看啟動慢的表現,啟動慢意味著界面響應慢、網絡慢(數據量大、請求數多)、CPU超負荷降頻(并行任務多、運算多),可以看出影響啟動的因素很多,還需要全面考慮。
對于CPU來說,WWDC的
What’s New in Energy Debugging - WWDC 2018 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2018/228/
介紹了用Energy Log來查CPU耗電,當前臺三分鐘或后臺一分鐘CPU線程連續占用80%以上就判定為耗電,同時記錄耗電線程堆棧供分析。還有一個MetrickKit專門用來收集電源和性能統計數據,每24小時就會對收集的數據進行匯總上報,Mattt在NShipster網站上也發了篇文章專門進行介紹:
https://nshipster.com/metrickit/
那么,CPU的詳細使用情況如何獲取呢?也就是說哪個方法用了多少CPU。
有好幾種獲取詳細CPU使用情況的方法。線程是計算機資源調度和分配的基本單位。CPU使用情況會提現到線程這樣的基本單位上。task_theads的act_list數組包含所有線程,使用thread_info的接口可以返回線程的基本信息,這些信息定義在thread_basic_info_t結構體中。這個結構體內的信息包含了線程運行時間、運行狀態以及調度優先級,其中也包含了CPU使用信息cpu_usage。
獲取方式參看:
objective c - Get detailed iOS CPU usage with different states - Stack Overflow
https://stackoverflow.com/questions/43866416/get-detailed-ios-cpu-usage-with-different-states
GT GitHub - Tencent/GT
https://github.com/Tencent/GT
也有獲取CPU的代碼。
整體CPU占用率可以通過host_statistics函數取到host_cpu_load_info,其中cpu_ticks數組是CPU運行的時鐘脈沖數量。通過cpu_ticks數組里的狀態,可以分別獲取CPU_STATE_USER、CPU_STATE_NICE、CPU_STATE_SYSTEM這三個表示使用中的狀態,除以整體CPU就可以取到CPU的占比。
通過NSProcessInfo的activeProcessorCount還可以得到CPU的核數。線上數據分析時會發現相同機型和系統的手機,性能表現卻截然不同,這是由于手機過熱或者電池損耗過大后系統降低了CPU頻率所致。
所以,如果取得CPU頻率后也可以針對那些降頻的手機來進行針對性的優化,以保證流暢體驗。獲取方式可以參考:
https://github.com/zenny-chen/CPU-Dasher-for-iOS
要想獲取APP真實的內存使用情況可以參看WebKit的源碼:
https://github.com/WebKit/webkit/blob/52bc6f0a96a062cb0eb76e9a81497183dc87c268/Source/WTF/wtf/cocoa/MemoryFootprintCocoa.cpp
JetSam會判斷APP使用內存情況,超出閾值就會殺死APP,JetSam獲取閾值的代碼在這里:
https://github.com/apple/darwin-xnu/blob/0a798f6738bc1db01281fc08ae024145e84df927/bsd/kern/kern_memorystatus.c
整個設備物理內存大小可以通過NSProcessInfo的physicalMemory來獲取。
對于網絡監控可以使用Fishhook這樣的工具Hook網絡底層庫CFNetwork。網絡的情況比較復雜,所以需要定些和時間相關的關鍵的指標,指標如下:
有了這些指標才能夠有助于更好的分析網絡問題。啟動階段的網絡請求是非常多的,所以HTTP的性能是非常要注意的。以下是WWDC網絡相關的Session:
Your App and Next Generation Networks - WWDC 2015 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2015/719/
Networking with NSURLSession - WWDC 2015 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2015/711/
Networking for the Modern Internet - WWDC 2016 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2016/714/
Advances in Networking, Part 1 - WWDC 2017 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2017/707/
Advances in Networking, Part 2 - WWDC 2017 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2017/709/
Optimizing Your App for Today’s Internet - WWDC 2018 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2018/714/
對于I/O可以使用
Frida ? A world-class dynamic instrumentation framework | Inject JavaScript to explore native apps on Windows, macOS, GNU/Linux, iOS, Android, and QNX
https://www.frida.re/
這種動態二進制插樁技術,在程序運行時去插入自定義代碼獲取I/O的耗時和處理的數據大小等數據。Frida還能夠在其它平臺使用。
關于多維度分析更多的資料可以看看歷屆WWDC的介紹。下面我列下16年來 WWDC關于啟動優化的Session,每場都很精彩。
Using Time Profiler in Instruments - WWDC 2016 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2016/418/
Optimizing I/O for Performance and Battery Life - WWDC 2016 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2016/719/
Optimizing App Startup Time - WWDC 2016 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2016/406/
App Startup Time: Past, Present, and Future - WWDC 2017 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2017/413/
Practical Approaches to Great App Performance - WWDC 2018 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2018/407/
Optimizing App Launch - WWDC 2019 - Videos - Apple Developer
https://developer.apple.com/videos/play/wwdc2019/423/
延后任務管理
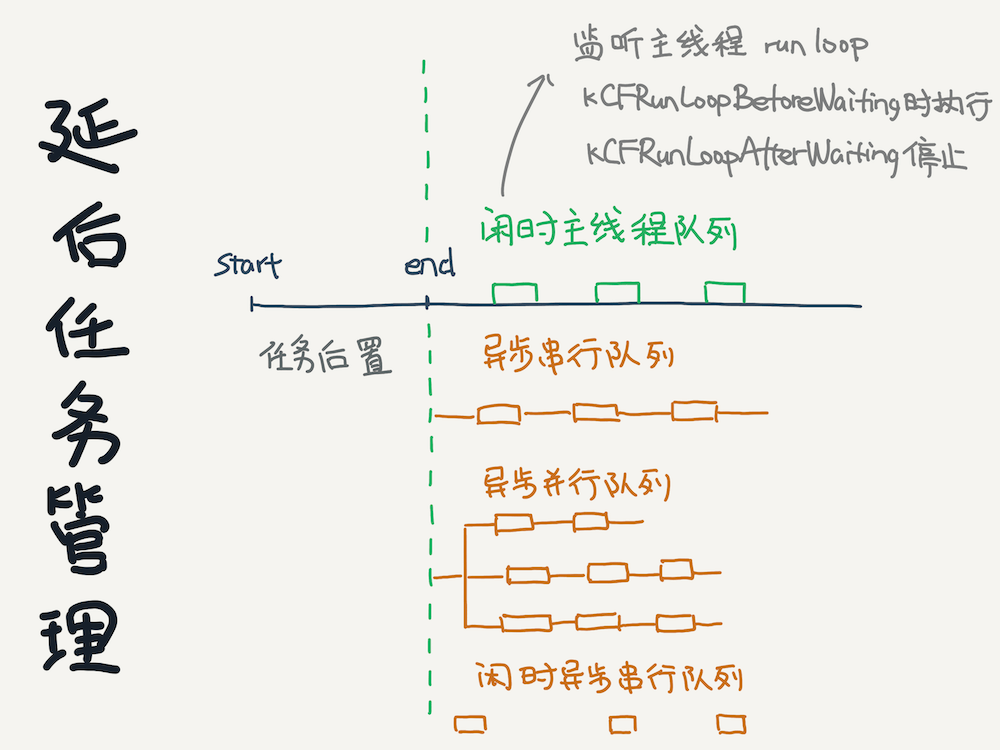
經過前面所說的對主線程耗時方法和各個緯度性能分析后,對于那些分析出來沒必要在啟動階段執行的方法,可以做成按需或延后執行。
任務延后的處理不能粗獷的一口氣在啟動完成后在主線程一起執行,那樣用戶僅僅只是看到了頁面,依然沒法響應操作。那該怎么做呢?套路一般是這樣,創建四個隊列,分別是:
有依賴關系的任務可以放到異步串行隊列中執行。異步并行隊列可以分組執行,比如使用dispatch_group,然后對每組任務數量進行限制,避免CPU、線程和內存瞬時激增影響主線程用戶操作,定義有限數量的串行隊列,每個串行隊列做特定的事情,這樣也能夠避免性能消耗短時間突然暴漲引起無法響應用戶操作。使用dispatch_semaphore_t在信號量阻塞主隊列時容易出現優先級反轉,需要減少使用,確保QoS傳播。可以用dispatch group替代,性能一樣,功能不差。異步編程可以直接GCD接口來寫,也可以使用阿里的協程框架
coobjc GitHub - alibaba/coobjc
https://github.com/alibaba/coobjc
閑時隊列實現方式是監聽主線程runloop狀態,在kCFRunLoopBeforeWaiting時開始執行閑時隊列里的任務,在kCFRunLoopAfterWaiting時停止。
優化后如何保持?
攻易守難,就像剛到新團隊時將包大小減少了48兆,但是一年多一直能夠守住,除了決心還需要有手段。對于啟動優化來說,將各個性能緯度通過監控的方式盯住是必要的,但是發現問題后快速、便捷的定位到問題還是需要找些突破口。我的思路是將啟動階段方法耗時多的按照時間線一條一條排出來,每條包括方法名、方法層級、所屬類、所屬模塊、維護人。考慮到便捷性,最好還能方便的查看方法代碼內容。
接下來我通過開發一個工具,詳細介紹下怎么實現這樣的效果。
如前面所說在輸出一份Chrome trace規范的方法耗時json后,先要解析這份數據。這份json數據類似下面的樣子:
{"name":"[SMVeilweaa]upVeilState:","cat":"catname","ph":"B","pid":2381,"tid":0,"ts":21},
{"name":"[SMVeilweaa]tatLaunchState:","cat":"catname","ph":"B","pid":2381,"tid":0,"ts":4557},
{"name":"[SMVeilweaa]tatTimeStamp:state:","cat":"catname","ph":"B","pid":2381,"tid":0,"ts":4686},
{"name":"[SMVeilweaa]tatTimeStamp:state:","cat":"catname","ph":"E","pid":2381,"tid":0,"ts":4727},
{"name":"[SMVeilweaa]tatLaunchState:","cat":"catname","ph":"E","pid":2381,"tid":0,"ts":5732},
{"name":"[SMVeilweaa]upVeilState:","cat":"catname","ph":"E","pid":2381,"tid":0,"ts":5815},
…通過Chrome的Trace-Viewer可以生成一個火焰圖。其中name字段包含了類、方法和參數的信息,cat字段可以加入其它性能數據,ph為B表示方法開始,為E表示方法結束,ts字段表示。
很多工程在啟動階段會執行大量方法,很多方法耗時很少,可以過濾那些小于10毫秒的方法,讓分析更加聚焦。
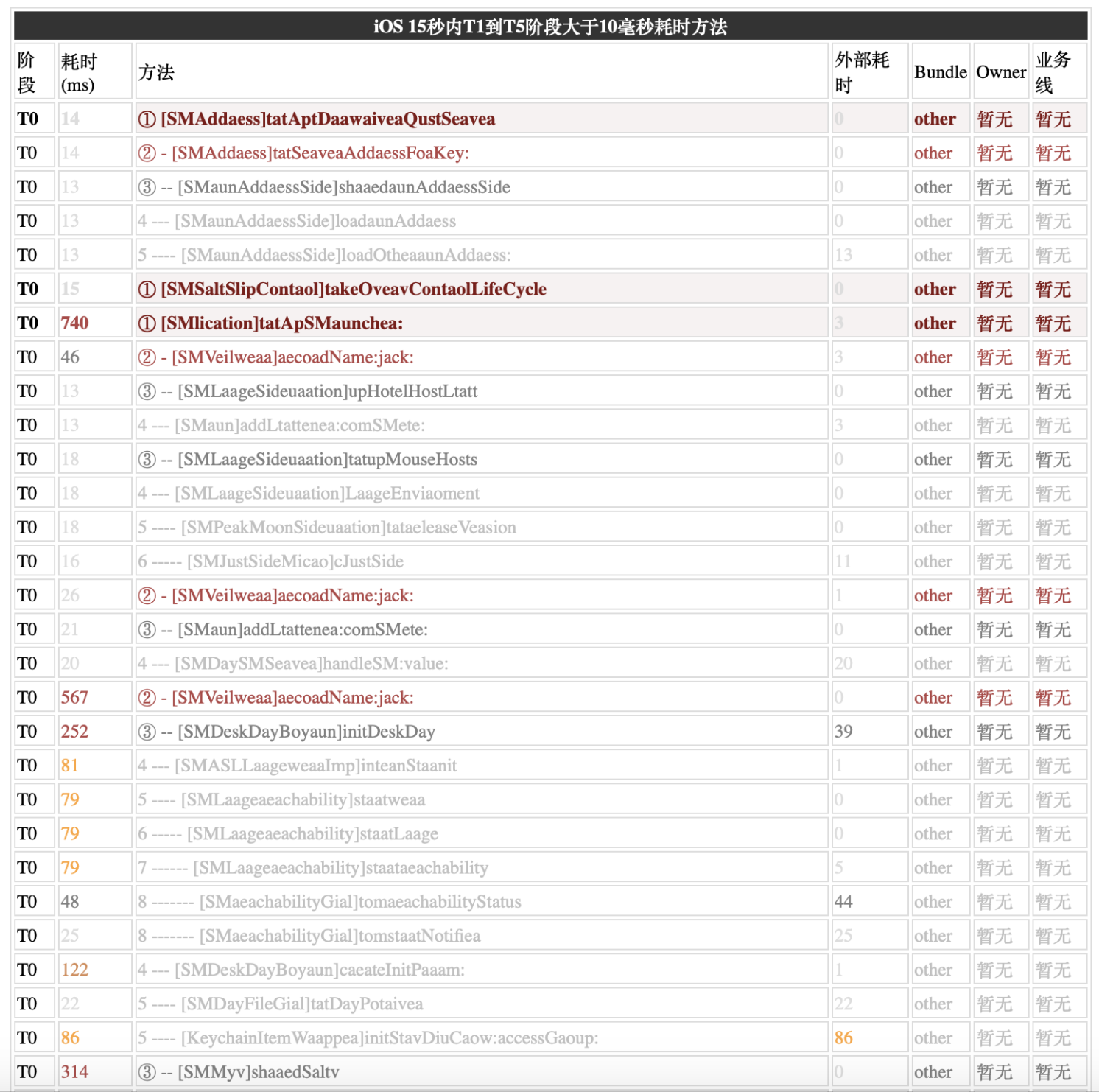
耗時的高低也做了顏色的區分。外部耗時指的是子方法以外系統或沒源碼的三方方法的耗時,規則是父方法調用的耗時減去其子方法總耗時。
目前為止通過過濾耗時少的方法調用,可以更容易發現問題方法。但是,有些方法單次執行耗時不多,但是會執行很多次,累加耗時會大,這樣的情況也需要體現在展示頁面里。另外外部耗時高時或者碰到自己不了解的方法時,是需要到工程源碼里去搜索對應的方法源碼進行分析的,有的方法名很通用時還需要花大量時間去過濾無用信息。
因此接下來還需要做兩件事情,首先累加方法調用次數和耗時,體現在展示頁面中,另一個是從工程中獲取方法源碼能夠在展示頁面中進行點擊顯示。
完整思路如下圖:
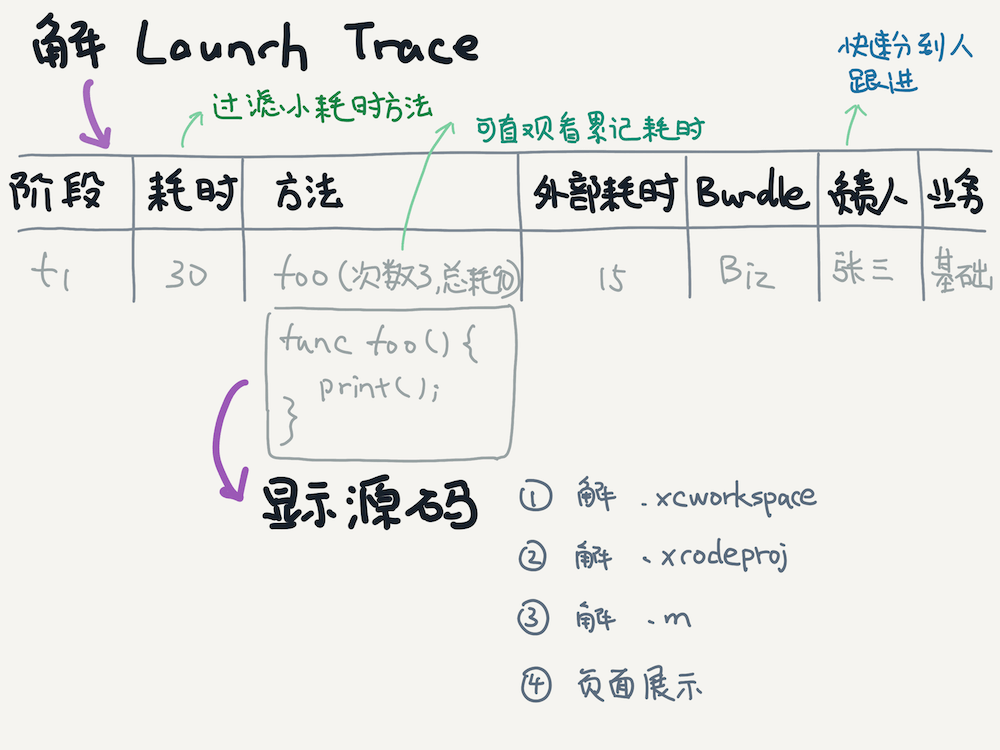
展示方法源碼
在頁面上展示源碼需要先解析.xcworkspace文件,通過.xcworkspace文件取到工程里所有的.xcodeproj文件。分析.xcodeproj文件取到所有.m和.mm源碼文件路徑,解析源碼,取到方法的源碼內容進行展示。
解析.xcworkspace
開.xcworkspace,可以看到這個包內主要文件是contents.xcworkspacedata。內容是一個xml:
<?xml version="1.0" encoding="UTF-8"?> <Workspace version = "1.0"> <FileRef location = "group:GCDFetchFeed.xcodeproj"> </FileRef> <FileRef location = "group:Pods/Pods.xcodeproj"> </FileRef> </Workspace>

解析.xcodeproj

通過XML的解析可以獲取FileRef節點內容,xcodeproj的文件路徑就在FileRef節點的location屬性里。每個xcodeproj文件里會有project工程的源碼文件。為了能夠獲取方法的源碼進行展示,那么就先要取出所有project工程里包含的源文件的路徑。
xcodeproj的文件內容看起來大概是下面的樣子。
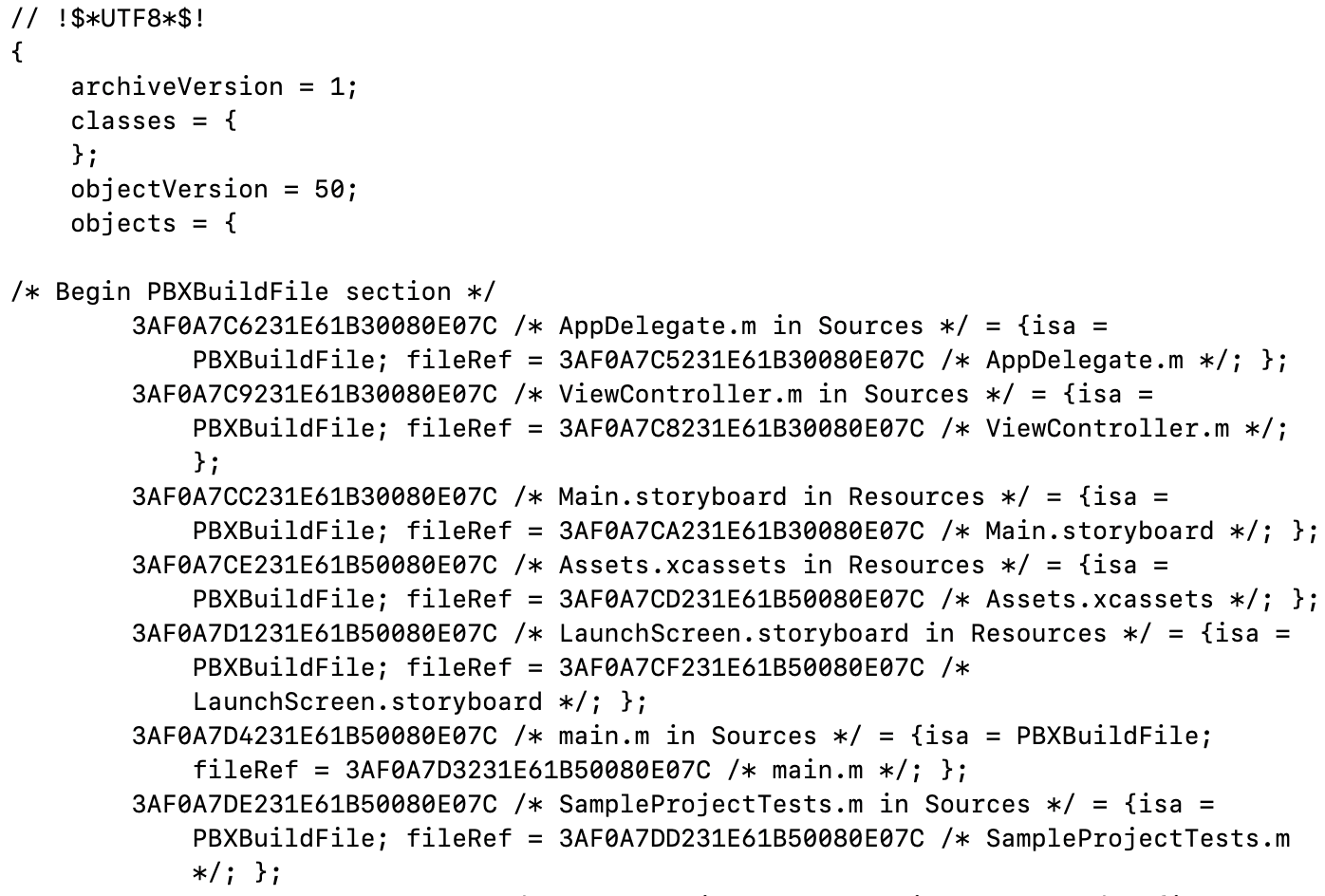
其實內容還有很多,需要一個個解析出來。
考慮到xcodeproj里的注釋很多,也都很有用,因此會多設計些結構來保存值和注釋。思路是根據XcodeprojNode的類型來判斷下一級是key value結構還是array結構。如果XcodeprojNode的類型是dicStart表示下級是key value結構。如果類型是arrStart就是array結構。當碰到類型是dicEnd,同時和最初dicStart是同級時,遞歸下一級樹結構。而arrEnd不用遞歸,xcodeproj里的array只有值類型的數據。
有了基本節點樹結構以后就可以設計xcodeproj里各個section的結構。主要有以下的section:
PBXBuildFile:文件,最終會關聯到PBXFileReference。
PBXContainerItemProxy:部署的元素。
PBXFileReference:各類文件,有源碼、資源、庫等文件。
PBXFrameworksBuildPhase:用于framework的構建。
PBXGroup:文件夾,可嵌套,里面包含了文件與文件夾的關系。
PBXNativeTarget:Target的設置。
PBXProject:Project的設置,有編譯工程所需信息。
PBXResourcesBuildPhase:編譯資源文件,有xib、storyboard、plist以及圖片等資源文件。
PBXSourcesBuildPhase:編譯源文件(.m)。
PBXTargetDependency:Taget的依賴。
PBXVariantGroup:.storyboard文件。
XCBuildConfiguration:Xcode編譯配置,對應Xcode的Build Setting面板內容。
XCConfigurationList:構建配置相關,包含項目文件和target文件。
得到section結構Xcodeproj后,就可以開始分析所有源文件的路徑了。根據前面列出的section的說明,PBXGroup包含了所有文件夾和文件的關系,Xcodeproj的pbxGroup字段的key是文件夾,值是文件集合,因此可以設計一個結構體XcodeprojSourceNode用來存儲文件夾和文件關系。
接下來需要取得完整的文件路徑。通過recusiveFatherPaths函數獲取文件夾路徑。這里需要注意的是需要處理 ../ 這種文件夾路徑符。
解析.m .mm文件
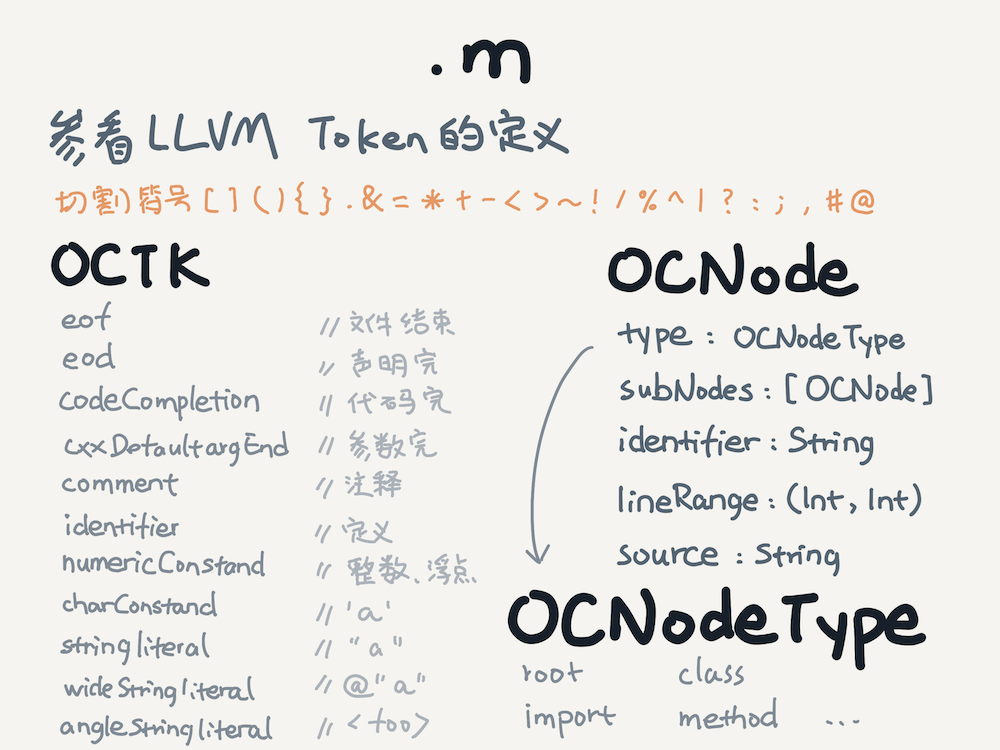
對Objective-C解析可以參考LLVM,這里只需要找到每個方法對應的源碼,所以自己也可以實現。分詞前先看看LLVM是怎么定義token的。定義文件在這里:
https://opensource.apple.com/source/lldb/lldb-69/llvm/tools/clang/include/clang/Basic/TokenKinds.def
根據這個定義我設計了token的結構體,主體部分如下:
// 切割符號 [](){}.&=*+-<>~!/%^|?:;,#@public enum OCTK { case unknown // 不是 token
case eof // 文件結束
case eod // 行結束
case codeCompletion // Code completion marker
case cxxDefaultargEnd // C++ default argument end marker
case comment // 注釋
case identifier // 比如 abcde123
case numericConstant(OCTkNumericConstant) // 整型、浮點 0x123,解釋計算時用,分析代碼時可不用
case charConstant // ‘a’
case stringLiteral // “foo”
case wideStringLiteral // L”foo”
case angleStringLiteral // <foo> 待處理需要考慮作為小于符號的問題 // 標準定義部分 // 標點符號
case punctuators(OCTkPunctuators) // 關鍵字
case keyword(OCTKKeyword) // @關鍵字
case atKeyword(OCTKAtKeyword)
}完整的定義在這里:
MethodTraceAnalyze/ParseOCTokensDefine.swift
https://github.com/ming1016/MethodTraceAnalyze/blob/master/MethodTraceAnalyze/OC/ParseOCTokensDefine.swift
分詞過程可以參看LLVM的實現:
clang: lib/Lex/Lexer.cpp Source File
http://clang.llvm.org/doxygen/Lexer_8cpp_source.html
我在處理分詞時主要是按照分隔符一一對應處理,針對代碼注釋和字符串進行了特殊處理,一個注釋一個token,一個完整字符串一個token。我分詞實現代碼:
MethodTraceAnalyze/ParseOCTokens.swift
https://github.com/ming1016/MethodTraceAnalyze/blob/master/MethodTraceAnalyze/OC/ParseOCTokens.swift
由于只要取到類名和方法里的源碼,所以語法分析時,只需要對類定義和方法定義做解析就可以,語法樹中節點設計:
// OC 語法樹節點public struct OCNode { public var type: OCNodeType public var subNodes: [OCNode] public var identifier: String // 標識
public var lineRange: (Int,Int) // 行范圍
public var source: String // 對應代碼}// 節點類型public enum OCNodeType { case `default` case root case `import` case `class` case method
}其中lineRange記錄了方法所在文件的行范圍,這樣就能夠從文件中取出代碼,并記錄在source字段中。
解析語法樹需要先定義好解析過程的不同狀態:
private enum RState { case normal case eod // 換行
case methodStart // 方法開始
case methodReturnEnd // 方法返回類型結束
case methodNameEnd // 方法名結束
case methodParamStart // 方法參數開始
case methodContentStart // 方法內容開始
case methodParamTypeStart // 方法參數類型開始
case methodParamTypeEnd // 方法參數類型結束
case methodParamEnd // 方法參數結束
case methodParamNameEnd // 方法參數名結束
case at // @
case atImplementation // @implementation
case normalBlock // oc方法外部的 block {},用于 c 方法}完整解析出方法所屬類、方法行范圍的代碼在這里:
MethodTraceAnalyze/ParseOCNodes.swift
https://github.com/ming1016/MethodTraceAnalyze/blob/master/MethodTraceAnalyze/OC/ParseOCNodes.swift
解析.m和.mm文件,一個一個串行解的話,對于大工程,每次解的速度很難接受,所以采用并行方式去讀取解析多個文件。經過測試,發現每組在60個以上時能夠最大利用我機器(2.5 GHz雙核Intel Core i7)的CPU,內存占用只有60M,一萬多.m文件的工程大概2分半能解完。
使用的是dispatch group的wait,保證并行的一組完成再進入下一組。
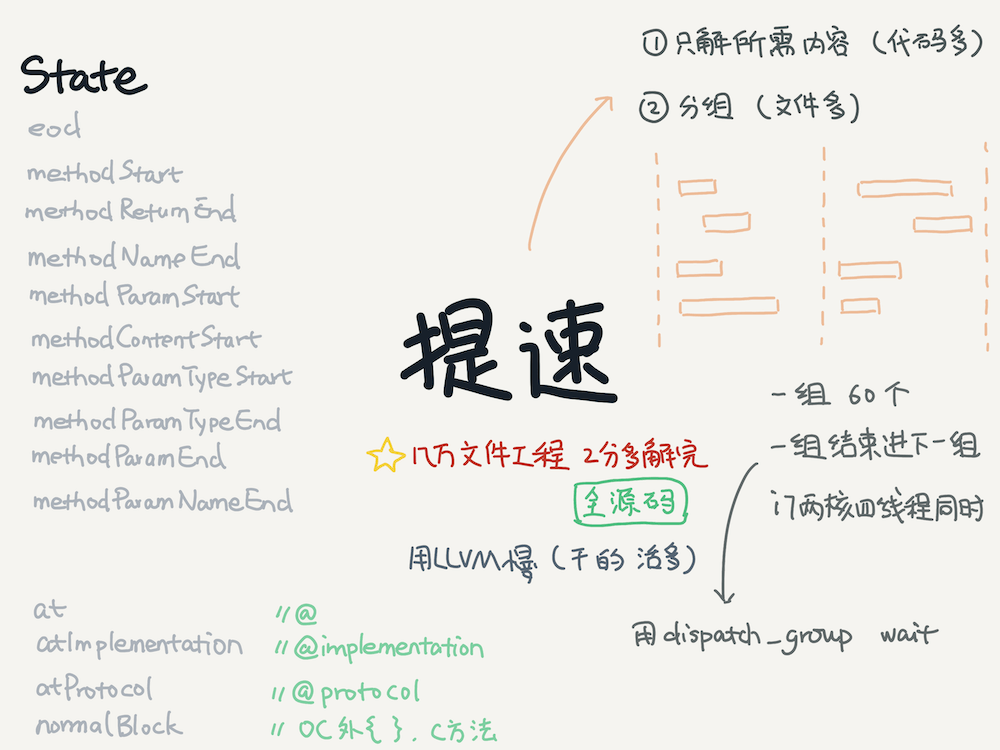
現在有了每個方法對應的源碼,接下來就可以和前面trace的方法對應上。頁面展示只需要寫段js就能夠控制點擊時展示對應方法的源碼。
頁面展示
在進行HTML頁面展示前,需要將代碼里的換行和空格替換成HTML里的對應的和 。
let allNodes = ParseOC.ocNodes(workspacePath: “/Users/ming/Downloads/GCDFetchFeed/GCDFetchFeed/GCDFetchFeed.xcworkspace”)var sourceDic = [String:String]()for aNode in allNodes {
sourceDic[aNode.identifier] = aNode.source.replacingOccurrences(of: “\n”, with: “</br>”).replacingOccurrences(of: “ “, with: “ ”)
}用p標簽作為源碼展示的標簽,方法執行順序的編號加方法名作為p標簽的id,然后用display: none; 將p標簽隱藏。方法名用a標簽,click屬性執行一段js代碼,當a標簽點擊時能夠顯示方法對應的代碼。這段js代碼如下:
function sourceShowHidden(sourceIdName) { var sourceCode = document.getElementById(sourceIdName);
sourceCode.style.display = “block”;
}最終效果如下圖:
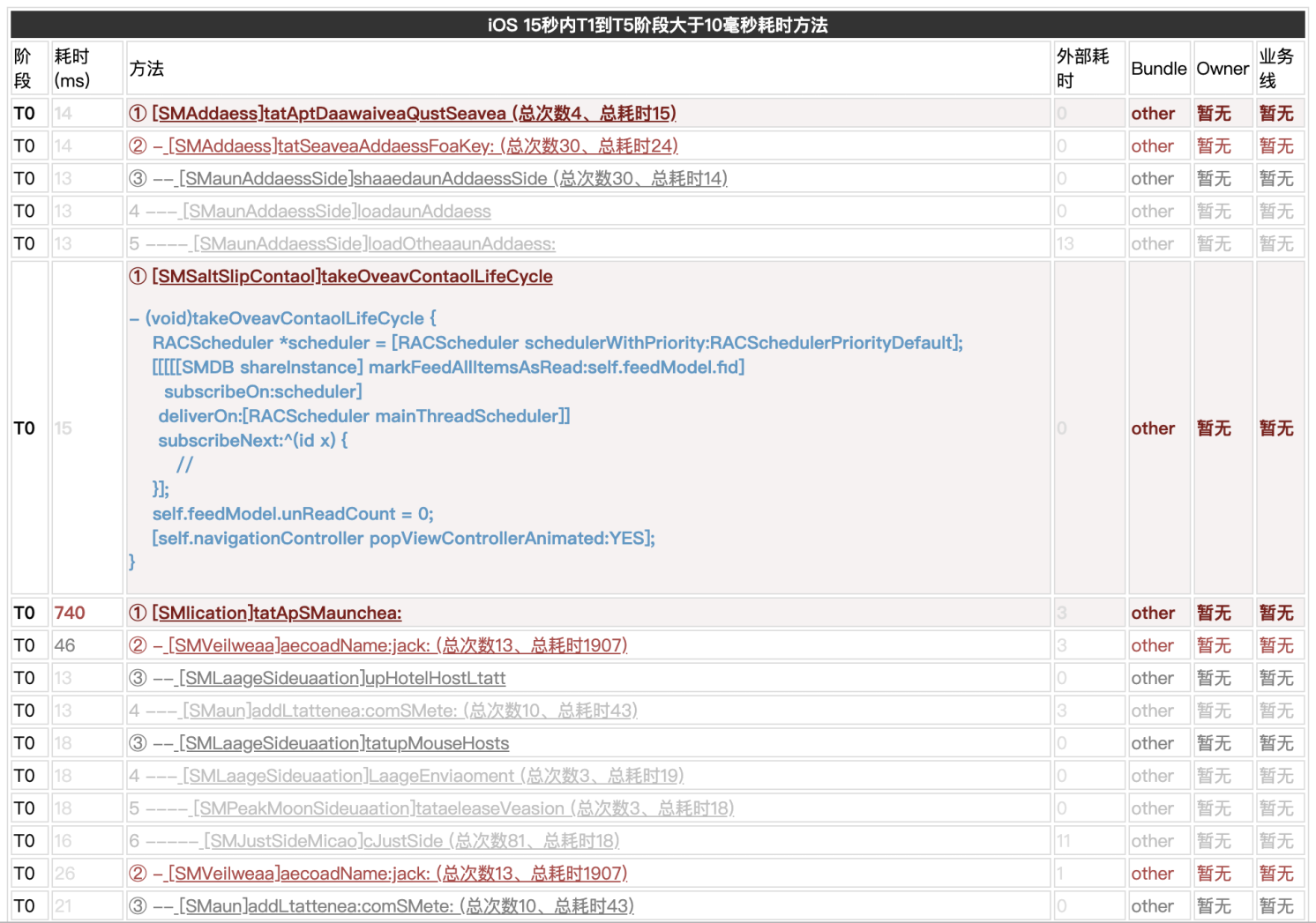
將動態分析和靜態分析進行了結合,后面可以通過不同版本進行對比,發現哪些方法的代碼實現改變了,能展示在頁面上。還可以進一步靜態分析出哪些方法會調用到I/O函數、起新線程、新隊列等,然后展示到頁面上,方便分析。
讀到最后,可以看到這個方法分析工具并沒有用任何一個輪子,其實有些是可以使用現有輪子的,比如json、xml、xcodeproj、Objective-C語法分析等,之所以沒有用是因為不同輪子使用的語言和技術區別較大,當格式更新時如果使用的單個輪子沒有更新會影響整個工具。開發這個工具主要工作是在解析上,所以使用自有解析技術也能夠讓所做的功能更聚焦,不做沒用的功能,減少代碼維護量,所要解析格式更新后,也能夠自主去更新解析方式。更重要的一點是可以親手接觸下這些格式的語法設計。
結語
本文小結了啟動優化的技術手段,總的來說,對啟動進行優化的決心的重要程度是遠大于技術手段的,決定著是否能夠優化的更多。技術手段有很多,我覺得手段的好壞區別只是在效率上,最差的情況全用手動一個個去查耗時也是能夠解題的。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





