溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行Apache Solr DataImportHandler遠程代碼執行漏洞CVE-2019-0193分析,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
2019年08月01日,Apache Solr官方發布 預警 ,Apache Solr DataImport功能 在開啟Debug模式時,可以接收來自請求的"dataConfig"參數,這個參數的功能與data-config.xml一樣,不過是在開啟Debug模式時方便通過此參數進行調試,并且Debug模式的開啟是通過參數傳入的。在dataConfig參數中可以包含script惡意腳本導致遠程代碼執行。
我對此漏洞進行了應急,由于在應急時構造的PoC很雞肋,需要存在數據庫驅動,需要連接數據庫并且無回顯,這種方式在實際利用中很難利用。后來逐漸有新的PoC被構造出來,經過了幾個版本的PoC升級,到最后能直接通過直接傳遞數據流的方式,無需數據庫驅動,無需連接數據庫且能回顯。下面記錄下PoC升級的歷程以及自己遇到的一些問題。感謝@Badcode與@fnmsd師傅提供的幫助。
分析中涉及到的與Solr相關的環境如下:
Solr-7.7.2
JDK 1.8.0_181
一開始沒有去仔細去查閱Solr相關資料,只是粗略翻了下文檔把漏洞復現了,那時候我也覺得數據應該能回顯,于是就開始調試嘗試構造回顯,但是沒有收獲。后來看到新的PoC,感覺自己還沒真正明白這個漏洞的原理就去盲目調試,于是又回過頭去查閱Solr資料與文檔,下面整理了與該漏洞有關的一些概念。
1.solr是在lucene工具包的基礎之上進行了封裝,并且以web服務的形式對外提供索引功能
2.業務系統需要使用到索引的功能(建索引,查索引)時,只要發出http請求,并將返回數據進行解析即可
(1) 索引數據的創建
根據配置文件提取一些可以用來搜索的數據(封裝成各種Field),把各field再封裝成document,然后對document進行分析(對各字段分詞),得到一些索引目錄寫入索引庫,document本身也會被寫入一個文檔信息庫
(2) 索引數據的查詢
根據關鍵詞解析(queryParser)出查詢條件query(Termquery),利用搜索工具(indexSearcher)去索引庫獲取文檔id,然后再根據文檔id去文檔信息庫獲取文檔信息
Solr DataImportHandler可以批量把數據導入到索引庫中,根據 Solr文檔 中的描述,DataImportHandler有如下功能:
讀取關系數據庫中數據或文本數據
根據配置從xml(http/file方式)讀取與建立索引數據
根據配置聚合來自多個列和表的數據來構建Solr文檔
使用文檔更新Solr(更新索引、文檔數據庫等)
根據配置進行完全導入的功能(full-import,完全導入每次運行時會創建整個索引)
檢測插入/更新字段并執行增量導入(delta-import,對增加或者被修改的字段進行導入)
調度full-import與delta-import
可以插入任何類型的數據源(ftp,scp等)和其他用戶可選格式(JSON,csv等)
通過搜索到的資料與官方文檔中對DataImportHandler的描述,根據我的理解整理出DataImport處理的大致的流程圖如下(只畫了與該漏洞相關的主要部分):
幾個名詞解釋:
Core:索引庫,其中包含schema.xml/managed-schema,schema.xml是模式文件的傳統名稱,可以由使用該模式的用戶手動編輯,managed-schema是Solr默認使用的模式文件的名稱,它支持在運行時動態更改,data-config文件可配置為xml形式或通過請求參數傳遞(在dataimport開啟debug模式時可通過dataConfig參數傳遞)
通過命令行創建core
-d 參數是指定配置模板,在solr 7.7.2下,有_default與sample_techproducts_configs兩種模板可以使用

通過web頁面創建core
一開始以為從web頁面無法創建core,雖然有一個Add Core,但是點擊創建的core目錄為空無法使用,提示無法找到配置文件,必須在solr目錄下創建好對應的core,在web界面才能添加。然后嘗試了使用絕對路徑配置,絕對路徑也能在web界面看到,但是solr默認不允許使用除了創建的core目錄之外的配置文件,如果這個開關設為了true,就能使用對應core外部的配置文件:
后來在回頭去查閱時在 Solr Guide 7.5文檔 中發現通過configSet參數也能創建core,configSet可以指定為_default與sample_techproducts_configs,如下表示創建成功,不過通過這種方式創建的core的沒有conf目錄,它的配置是相當于鏈接到configSet模板的,而不是使用copy模板的方式:

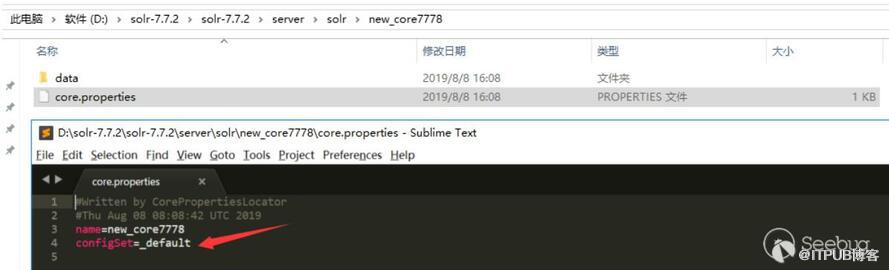
通過以上兩種方式都能創建core,但是要使用dataimport功能,還是需要編輯配置solrconfig.xml文件,如果能通過web請求方式更改配置文件以配置dataimport功能就能更好利用這個漏洞了。
schema.xml/managed-schema:這里面定義了與數據源相關聯的字段(Field)以及Solr建立索引時該如何處理Field,它的內容可以自己打開新建的core下的schema.xml/managed-schema看下,內容太長就不貼了,解釋下與該漏洞相關的幾個元素:
Field: 域的定義,相當于數據源的字段 Name:域的名稱 Type:域的類型 Indexed:是否索引 Stored:是否存儲 multiValued:是否多值,如果是多值在一個域中可以保持多個值 example: <field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="name" type="string" indexed="true" stored="true" required="true" multiValued="false" /> dynamicField:動態域,PoC最后一個階段便是根據這個字段回顯的 動態字段定義允許使用約定優于配置,對于字段,通過模式規范來匹配字段名稱 示例:name ="*_i"將匹配dataConfig中以_i結尾的任何字段(如myid_i,z_i) 限制:name屬性中類似glob的模式必須僅在開頭或結尾處具有"*"。 這里的含義就是當dataConfig插入數據發現某一個域沒有定義時,這時可以使用動態域當作字段名稱 進行數據存儲,這個會在后面PoC的進化中看到 example: <dynamicField name="*_i" type="pint" indexed="true" stored="true"/> <dynamicField name="*_is" type="pints" indexed="true" stored="true"/> <dynamicField name="*_s" type="string" indexed="true" stored="true" /> <dynamicField name="*_ss" type="strings" indexed="true" stored="true"/> <dynamicField name="*_l" type="plong" indexed="true" stored="true"/> <dynamicField name="*_ls" type="plongs" indexed="true" stored="true"/>
dataConfig:這個配置項可以通過文件配置或通過請求方式傳遞(在dataimport開啟Debug模式時可以通過dataConfig參數),他配置的時怎樣獲取數據(查詢語句、url等等)要讀什么樣的數據(關系數據庫中的列、或者xml的域)、做什么樣的處理(修改/添加/刪除)等,Solr為這些數據數據創建索引并將數據保存為Document
對于此漏洞需要了解dataConfig的以下幾個元素: Transformer:實體提取的每組字段可以在索引過程直接使用,也可以使用來修改字段或創建一組全新的字段, 甚至可以返回多行數據。必須在entity級別上配置Transformer RegexTransformer:使用正則表達式從字段(來自源)提取或操作值 ScriptTransformer:可以用Javascript或Java支持的任何其他腳本語言編寫 Transformer,該漏洞使用的是這個 DateFormatTransformer:用于將日期/時間字符串解析為java.util.Date實例 NumberFormatTransformer:可用于解析String中的數字 TemplateTransformer:可用于覆蓋或修改任何現有的Solr字段或創建新的Solr字段 HTMLStripTransformer:可用于從字符串字段中刪除HTML ClobTransformer:可用于在數據庫中創建Clob類型的String LogTransformer:可用于將數據記錄到控制臺/日志 EntityProcessor:實體處理器 SqlEntityProcessor:不指定時,默認的處理器 XPathEntityProcessor:索引XML類型數據時使用 FileListEntityProcessor:一個簡單的實體處理器,可用于根據某些條件枚舉文件系統中的文件 列表 CachedSqlEntityProcessor:SqlEntityProcessor的擴展 PlainTextEntityProcessor:將數據源中的所有內容讀入名 為"plainText"的單個隱式字段。內容不會以任何方式解析,但是 您可以根據需要添加transform來操作“plainText”中的數據 LineEntityProcessor:為每行讀取返回一個名為"rawLine"的字段。內容不會以任何方式解析, 但您可以添加transform來操作“rawLine”中的數據或創建其他附加字段 SolrEntityProcessor:從不同的Solr實例和核心導入數據 dataSource:數據源,他有以下幾種類型,每種類型有自己不同的屬性 JdbcDataSource:數據庫源 URLDataSource:通常與XPathEntityProcessor配合使用,可以使用file://、http://、 ftp://等協議獲取文本數據源 HttpDataSource:與URLDataSource一樣,只是名字不同 FileDataSource:從磁盤文件獲取數據源 FieldReaderDataSource:如果字段包含xml信息時,可以使用這個配合XPathEntityProcessor 使用 ContentStreamDataSource:使用post數據作為數據源,可與任何EntityProcessor配合使用 Entity:實體,相當于將數據源的操作的數據封裝成一個Java對象,字段就對應對象屬性 對于xml/http數據源的實體可以在默認屬性之上具有以下屬性: processor(必須):值必須是 "XPathEntityProcessor" url(必須):用于調用REST API的URL。(可以模板化)。如果數據源是文件,則它必須是文件位置 stream (可選):如果xml非常大,則將此值設置為true forEach(必須):劃分記錄的xpath表達式。如果有多種類型的記錄用“|”(管道)分隔它們。如果 useSolrAddSchema設置為'true',則可以省略。 xsl(可選):這將用作應用XSL轉換的預處理器。提供文件系統或URL中的完整路徑。 useSolrAddSchema(可選):如果輸入到此處理器的xml具有與solr add xml相同的模式,則將其 值設置為“true”。如果設置為true,則無需提及任何字段。 flatten(可選):如果設置為true,則無論標簽名稱如何,所有標簽下的文本都將提取到一個字段中 實體的field可以具有以下屬性: xpath(可選):要映射為記錄中的列的字段的xpath表達式。如果列不是來自xml屬性(是由變換器 創建的合成字段),則可以省略它。如果字段在模式中標記為多值,并且在xpath的 給定行中找到多個值,則由XPathEntityProcessor自動處理。無需額外配置 commonField:可以是(true | false)。如果為true,則在創建Solr文檔之前,記錄中遇到的此 字段將被復制到其他記錄
根據官方 漏洞預警描述 ,是DataImportHandler在開啟Debug模式時,能接收dataConfig這個參數,這個參數的功能與data-config.xml一樣,不過是在開啟Debug模式時方便通過此參數進行調試,并且Debug模式的開啟是通過參數傳入的。在dataConfig參數中可以包含script腳本,在 文檔 搜到一個ScriptTransformer的例子:
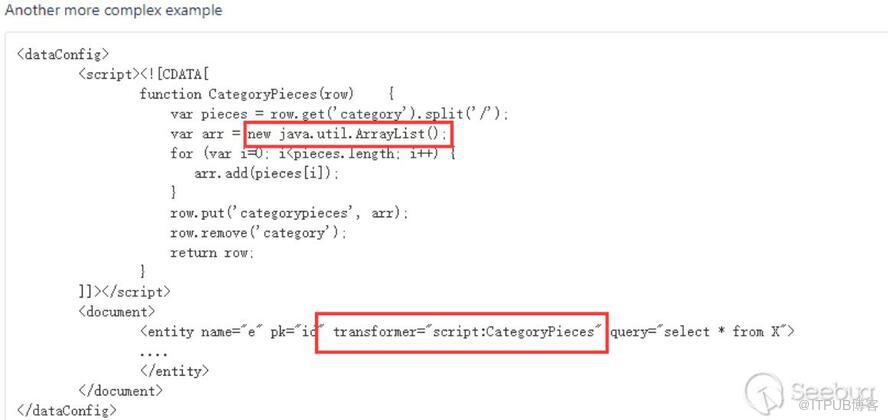
可以看到在script中能執行java代碼,于是構造下PoC(通過logs查看相關報錯信息查看PoC構造出現的問題),這個數據庫是可以外連的,所以數據庫的相關信息可以自己控制,測試過是可以的(只是演示使用的127.0.0.1):
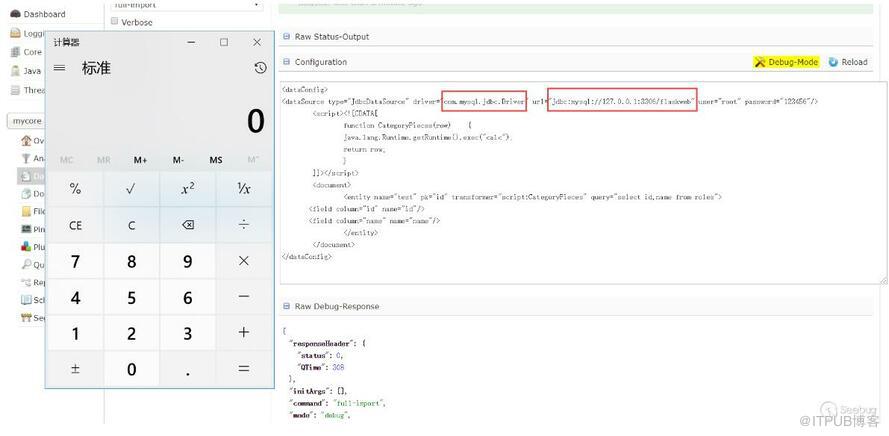
在ScriptTransformer那個例子中,能看到row.put的字樣,猜測應該是能回顯的,測試下:
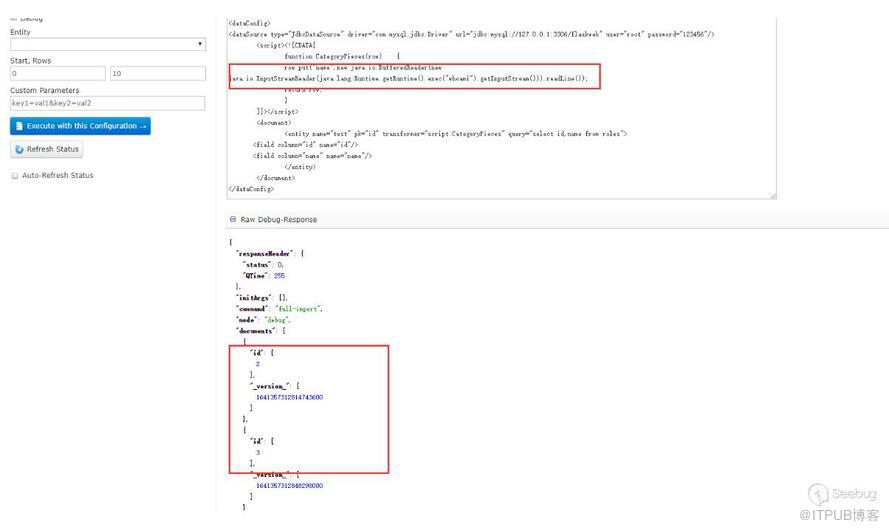
這里只能查看id字段,name字段看不到,也沒有報錯,然后嘗試了下把數據put到id里面:
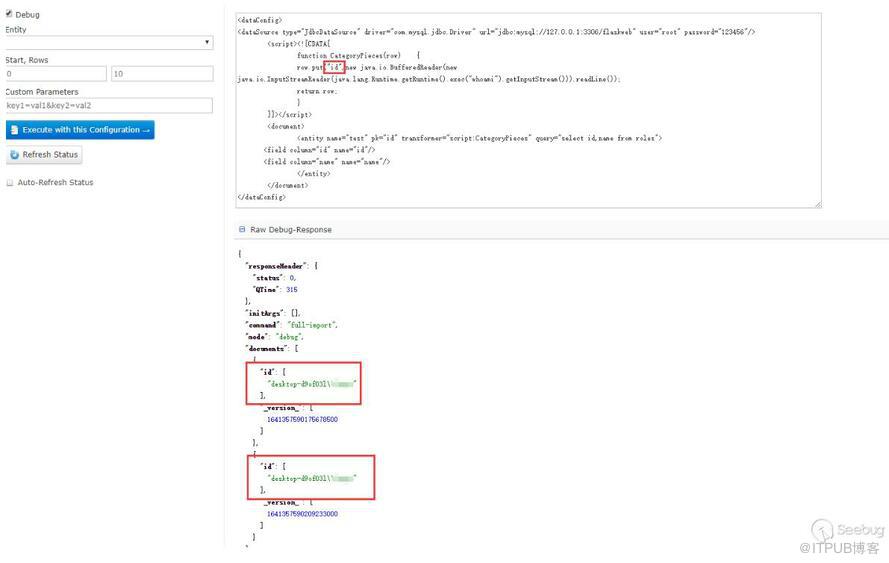
能看到回顯的信息。一開始不知道為什么put到name不行,后來看到在第三階段的PoC,又回過頭去查資料才意識到dataConfig與schema是配合使用的。因為在schema中沒有配置name這個field,但是默認配置了id這個fileld,所以solr不會把name這個字段數據放到Document中去而id字段在其中。在第三階段的PoC中,每個Field中的name屬性都有"_s",然后去搜索發現可以在schema配置文件中可以配置dynamicField,如下是默認配置好的dynamicField:
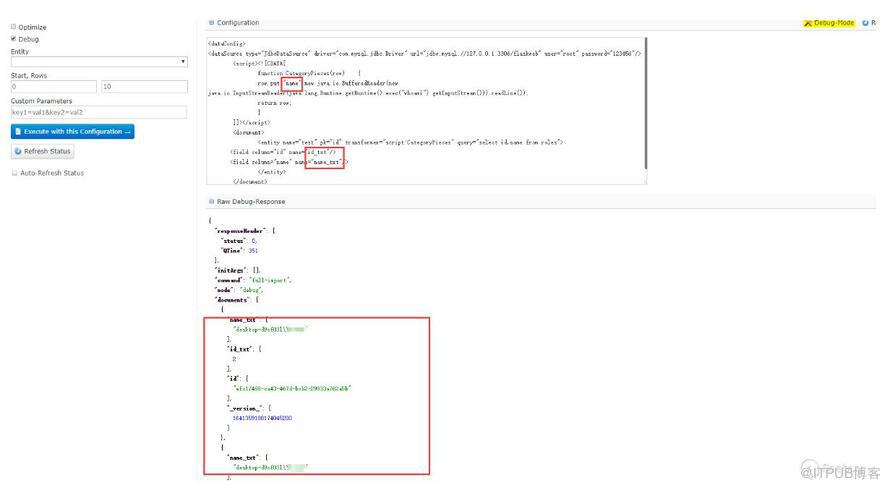
在上面的相關概念中對這個字段有介紹,可以翻上去查看下,測試下,果然是可以的:
只要dynamicField能匹配dataConfig中field的name屬性,solr就會自動加到document中去,如果schema配置了相應的field,那么配置的field優先,沒有配置則根據dynamicField匹配。
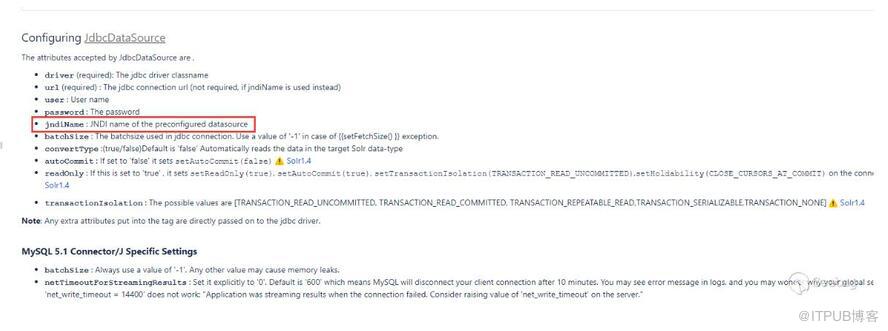
在文檔中說到JdbcDataSource可以使用JNDI,
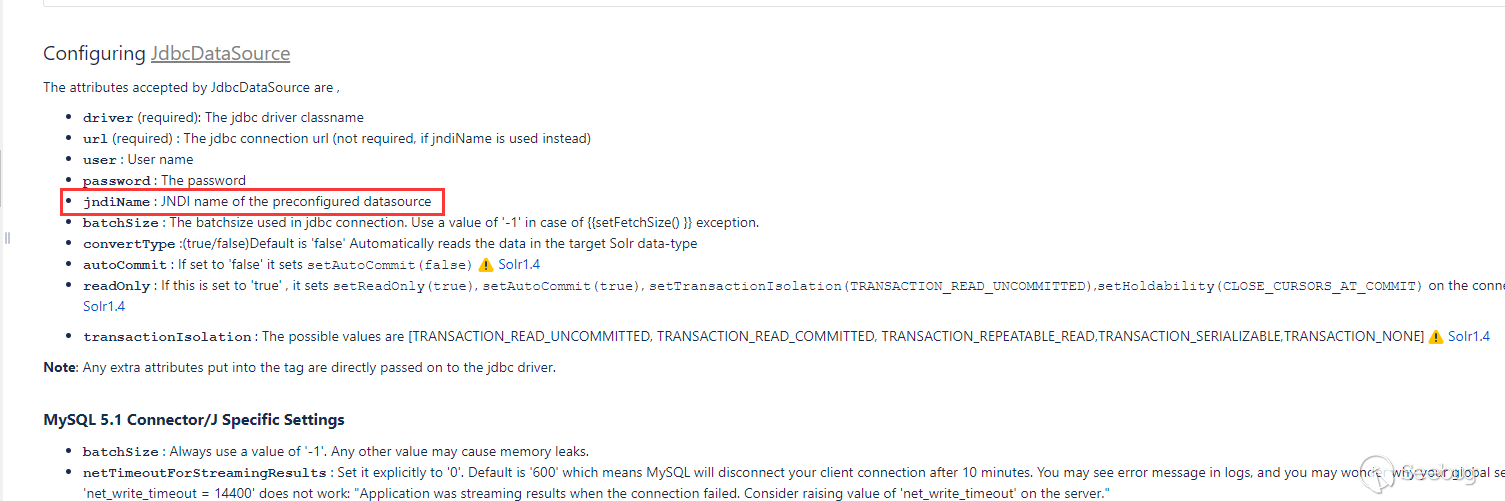
測試下能不能進行JNDI注入:
這里有一個JNDI+LDAP的惡意 demo 。使用這種方式無需目標的CLASSPATH存在數據庫驅動。
這個階段的PoC來自@fnmsd師傅,使用的是 ContentStreamDataSource ,但是文檔中沒有對它進行描述如何使用。在 stackoverflower 找到一個使用例子:
在相關概念中說到了ContentStreamDataSource能接收Post數據作為數據源,結合第一階段說到的dynamicField就能實現回顯了。
只演示下效果圖,不給出具體的PoC:
后來回過頭去看其他類型的DataSource時,使用URLDataSource/HttpDataSource也可以,文檔中提供了一個例子:
構造測試也是可行的,可以使用http、ftp等協議
看完上述內容,你們掌握如何進行Apache Solr DataImportHandler遠程代碼執行漏洞CVE-2019-0193分析的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





