溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何用Scrapy爬取豆瓣TOP250,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
最好的學習方式就是輸入之后再輸出,分享一個自己學習scrapy框架的小案例,方便快速的掌握使用scrapy的基本方法。
本想從零開始寫一個用Scrapy爬取教程,但是官方已經有了樣例,所以還是不寫了,盡量分享在網上不太容易找到的東西。自己近期在封閉培訓,更文像蝸牛一樣,抱歉。
Scrapy是一個為了爬取網站數據,提取結構性數據而編寫的應用框架。 可以應用在包括數據挖掘,信息處理或存儲歷史數據等一系列的程序中。
其最初是為了 頁面抓取 (更確切來說, 網絡抓取 )所設計的, 也可以應用在獲取API所返回的數據(例如 Amazon Associates Web Services ) 或者通用的網絡爬蟲。
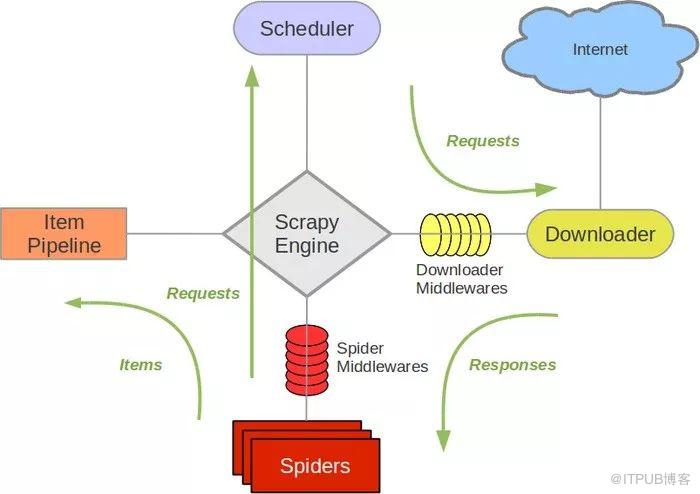
如果此前對scrapy沒有了解,請先查看下面的官方教程鏈接。
架構概覽:https://docs.pythontab.com/scrapy/scrapy0.24/topics/architecture.html
Scrapy入門教程:https://docs.pythontab.com/scrapy/scrapy0.24/intro/tutorial.html
首先,我們看一下豆瓣TOP250頁面,發現可以從中提取電影名稱、排名、評分、評論人數、導演、年份、地區、類型、電影描述。

????Item對象是種簡單的容器,保存了爬取到得數據。其提供了類似于詞典的API以及用于聲明可用字段的簡單語法。所以可以聲明Item為如下形式。
class DoubanItem(scrapy.Item):
# 排名
ranking = scrapy.Field()
# 電影名稱
title = scrapy.Field()
# 評分
score = scrapy.Field()
# 評論人數
pople_num = scrapy.Field()
# 導演
director = scrapy.Field()
# 年份
year = scrapy.Field()
# 地區
area = scrapy.Field()
# 類型
clazz = scrapy.Field()
# 電影描述
decsription = scrapy.Field()
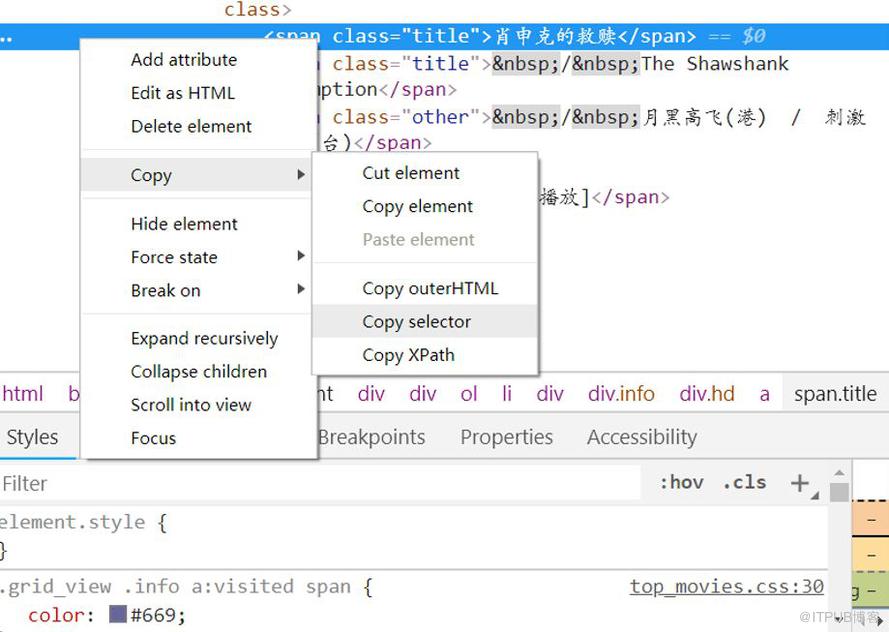
我們抓取到相應的網頁后,需要從網頁中提取自己需要的信息,可以使用xpath語法,我使用的是BeautifulSoup網頁解析器,經過BeautifulSoup解析的網頁,可以直接使用選擇器篩選需要的信息。有一些說明寫到代碼注釋里面去了,就不再贅述。
Chrome 也可以直接復制選擇器或者XPath,如下圖所示。
class douban_spider(Spider):
count = 1
# 爬蟲啟動命令
name = 'douban'
# 頭部信息,偽裝自己不是爬蟲程序
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
# 爬蟲啟動鏈接
def start_requests(self):
url = 'https://movie.douban.com/top250'
yield Request(url, headers=self.headers)
# 處理爬取的數據
def parse(self, response):
print('第', self.count, '頁')
self.count += 1
item = DoubanItem()
soup = BeautifulSoup(response.text, 'html.parser')
# 選出電影列表
movies = soup.select('#content div div.article ol li')
for movie in movies:
item['title'] = movie.select('.title')[0].text
item['ranking'] = movie.select('em')[0].text
item['score'] = movie.select('.rating_num')[0].text
item['pople_num'] = movie.select('.star span')[3].text
# 包含導演、年份、地區、類別
info = movie.select('.bd p')[0].text
director = info.strip().split('\n')[0].split(' ')
yac = info.strip().split('\n')[1].strip().split(' / ')
item['director'] = director[0].split(': ')[1]
item['year'] = yac[0]
item['area'] = yac[1]
item['clazz'] = yac[2]
# 電影描述有為空的,所以需要判斷
if len(movie.select('.inq')) is not 0:
item['decsription'] = movie.select('.inq')[0].text
else:
item['decsription'] = 'None'
yield item
# 下一頁:
# 1,可以在頁面中找到下一頁的地址
# 2,自己根據url規律構造地址,這里使用的是第二種方法
next_url = soup.select('.paginator .next a')[0]['href']
if next_url:
next_url = 'https://movie.douban.com/top250' + next_url
yield Request(next_url, headers=self.headers)
然后在項目文件夾內打開cmd命令,運行scrapy crawl douban -o movies.csv就會發現提取的信息就寫入指定文件了,下面是爬取的結果,效果很理想。

看完上述內容,你們掌握如何用Scrapy爬取豆瓣TOP250的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





