溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關在LevelDB數據庫中如何實現磁盤多路歸并排序,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
在 LevelDB 數據庫中高層數據下沉到低層時需要經歷一次 Major Compaction,將高層文件的有序鍵值對和低層文件的多個有序鍵值對進行歸并排序。磁盤多路歸并排序算法的輸入是來自多個磁盤文件的有序鍵值對,在內存中將這些文件的鍵值對進行排序,然后輸出到一到多個新的磁盤文件中。
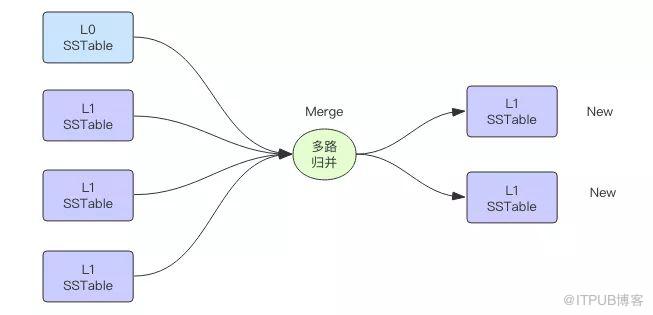
多路歸并排序在大數據領域也是常用的算法,常用于海量數據排序。當數據量特別大時,這些數據無法被單個機器內存容納,它需要被切分位多個集合分別由不同的機器進行內存排序(map 過程),然后再進行多路歸并算法將來自多個不同機器的數據進行排序(reduce 過程),這是流式多路歸并排序,為什么說是流式排序呢,因為數據源來源于網絡套接字。
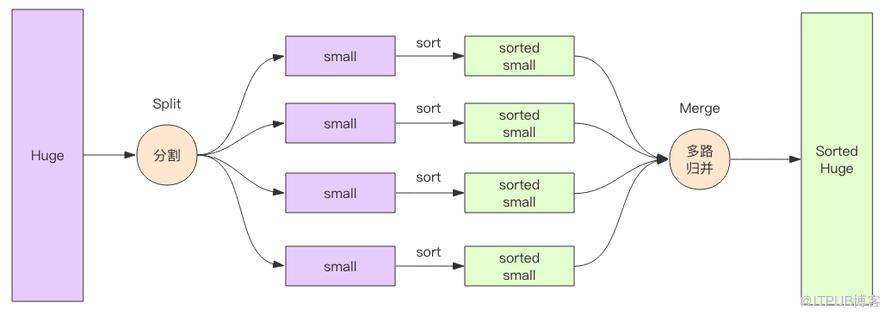
多路歸并排序的優勢在于內存消耗極低,它的內存占用和輸入文件的數量成正比,和數據總量無關,數據總量只會線性正比影響排序的時間。
下面我們來親自實現一下磁盤多路歸并算法,為什么是磁盤,因為它的輸入來自磁盤文件。
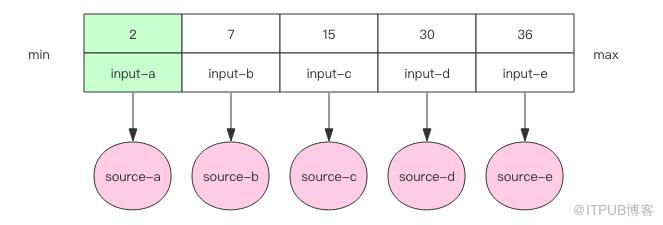
我們需要在內存里維護一個有序數組。每個輸入文件當前最小的元素作為一個元素放在數組里。數組按照元素的大小保持排序狀態。
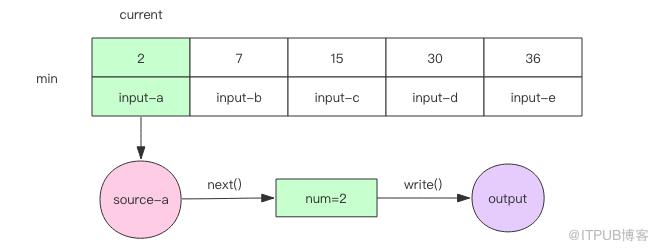
接下來我們開始進入循環,循環的邏輯總是從最小的元素下手,在其所在的文件取出下一個元素,和當前數組中的元素進行比較。根據比較結果進行不同的處理,這里我們使用二分查找算法進行快速比較。注意每個輸入文件里面的元素都是有序的。
1. 如果取出來的元素和當前數組中的最小元素相等,那么就可以直接將這個元素輸出。再繼續下一輪循環。不可能取出比當前數組最小元素還要小的元素,因為輸入文件本身也是有序的。
2. 否則就需要將元素插入到當前的數組中的指定位置,繼續保持數組有序。然后將數組中當前最小的元素輸出并移除。再進行下一輪循環。
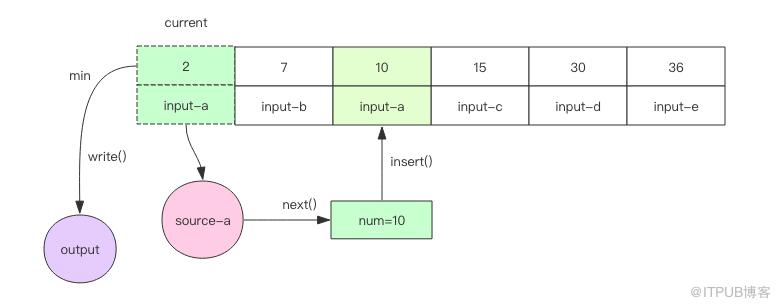
3. 如果遇到文件結尾,那就無法繼續調用 next() 方法了,這時可以直接將數組中的最小元素輸出并移除,數組也跟著變小了。再進行下一輪循環。當數組空了,說明所有的文件都處理完了,算法就可以結束了。
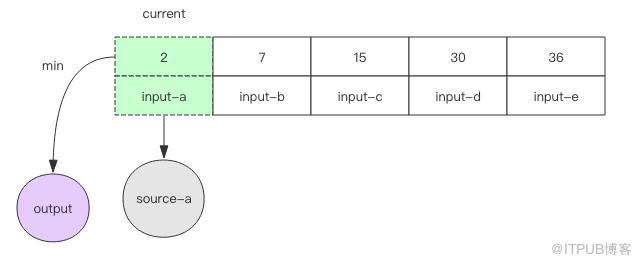
值得注意的是,數組中永遠不會存在同一個文件的兩個元素,如此才保證了數組的長度不會超過輸入文件的數量,同時它也不會把沒有結尾的文件擠出數組導致漏排序的問題。
需要特別注意的是Java 內置了二分查找算法在使用上比較精巧。
public class Collections {
...
public static <T> int binarySearch(List<T> list, T key) {
...
if (found) {
return index;
} else {
return -(insertIndex+1);
}
}
...
}
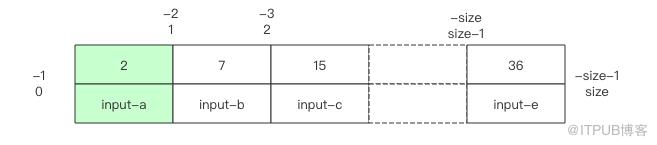
如果 key 可以在 list 中找到,那就直接返回相應的位置。如果找不到,它會返回負數,還不是簡單的 -1,這個負數指明了插入的位置,也就是說在這個位置插入 key,數組將可以繼續保持有序。
比如 binarySearch 返回了 index=-1,那么 insertIndex 就是 -(index+1),也就是 0,插入點在數組開頭。如果返回了 index=-size-1,那么 insertIndex 就是 size,是數組末尾。其它負數會插入數組中間。
對于每一個輸入文件都會創建一個 MergeSource 對象,它提供了 hasNext() 和 next() 方法用于判斷和獲取下一個元素。注意輸入文件是有序的,下一個元素就是當前輸入文件最小的元素。
hasNext() 方法負責讀取下一行并緩存在 cachedLine 變量中,調用 next() 方法將 cachedLine 變量轉換成整數并返回。
class MergeSource implements Closeable {
private BufferedReader reader;
private String cachedLine;
private String filename;
public MergeSource(String filename) {
this.filename = filename;
try {
FileReader fr = new FileReader(filename);
this.reader = new BufferedReader(fr);
} catch (FileNotFoundException e) {
}
}
public boolean hasNext() {
String line;
try {
line = this.reader.readLine();
if (line == null || line.isEmpty()) {
return false;
}
this.cachedLine = line.trim();
return true;
} catch (IOException e) {
}
return false;
}
public int next() {
if (this.cachedLine == null) {
if (!hasNext()) {
throw new IllegalStateException("no content");
}
}
int num = Integer.parseInt(this.cachedLine);
this.cachedLine = null;
return num;
}
@Override
public void close() throws IOException {
this.reader.close();
}
}
在排序前先把這個數組準備好,將每個輸入文件的最小元素放入數組,并排序。
class Bin implements Comparable<Bin> {
int num;
MergeSource source;
Bin(MergeSource source, int num) {
this.source = source;
this.num = num;
}
@Override
public int compareTo(Bin o) {
return this.num - o.num;
}
}
List<Bin> prepare() {
List<Bin> bins = new ArrayList<>();
for (MergeSource source : sources) {
Bin newBin = new Bin(source, source.next());
bins.add(newBin);
}
Collections.sort(bins);
return bins;
}
關閉輸出文件時注意要先 flush(),避免丟失 PrintWriter 中緩沖的內容。
class MergeOut implements Closeable {
private PrintWriter writer;
public MergeOut(String filename) {
try {
FileOutputStream out = new FileOutputStream(filename);
this.writer = new PrintWriter(out);
} catch (FileNotFoundException e) {
}
}
public void write(Bin bin) {
writer.println(bin.num);
}
@Override
public void close() throws IOException {
writer.flush();
writer.close();
}
}
下面我們來生成一系列輸入文件,每個輸入文件中包含一堆隨機整數。一共生成 n 個文件,每個文件的整數數量在 minEntries 到 minEntries 之間。返回所有輸入文件的文件名列表。
List<String> generateFiles(int n, int minEntries, int maxEntries) {
List<String> files = new ArrayList<>();
for (int i = 0; i < n; i++) {
String filename = "input-" + i + ".txt";
PrintWriter writer;
try {
writer = new PrintWriter(new FileOutputStream(filename));
ThreadLocalRandom rand = ThreadLocalRandom.current();
int entries = rand.nextInt(minEntries, maxEntries);
List<Integer> nums = new ArrayList<>();
for (int k = 0; k < entries; k++) {
int num = rand.nextInt(10000000);
nums.add(num);
}
Collections.sort(nums);
for (int num : nums) {
writer.println(num);
}
writer.flush();
writer.close();
} catch (FileNotFoundException e) {
}
files.add(filename);
}
return files;
}
萬事俱備,只欠東風。將上面的類都準備好之后,排序算法很簡單,代碼量非常少。對照上面算法思路來理解下面的算法就很容易了。
public void sort() {
List<Bin> bins = prepare();
while (true) {
// 取數組中最小的元素
MergeSource current = bins.get(0).source;
if (current.hasNext()) {
// 從輸入文件中取出下一個元素
Bin newBin = new Bin(current, current.next());
// 二分查找,也就是和數組中已有元素進行比較
int index = Collections.binarySearch(bins, newBin);
if (index == 0) {
// 算法思路情況1
this.out.write(newBin);
} else {
// 算法思路情況2
if (index < 0) {
index = -(index+1);
}
bins.add(index, newBin);
Bin minBin = bins.remove(0);
this.out.write(minBin);
}
} else {
// 算法思路情況3:遇到文件尾
Bin minBin = bins.remove(0);
this.out.write(minBin);
if (bins.isEmpty()) {
break;
}
}
}
}
讀者可以直接將下面的代碼拷貝粘貼到 IDE 中運行。
package leetcode;
import java.io.BufferedReader;
import java.io.Closeable;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.ThreadLocalRandom;
public class DiskMergeSort implements Closeable {
public static List<String> generateFiles(int n, int minEntries, int maxEntries) {
List<String> files = new ArrayList<>();
for (int i = 0; i < n; i++) {
String filename = "input-" + i + ".txt";
PrintWriter writer;
try {
writer = new PrintWriter(new FileOutputStream(filename));
int entries = ThreadLocalRandom.current().nextInt(minEntries, maxEntries);
List<Integer> nums = new ArrayList<>();
for (int k = 0; k < entries; k++) {
int num = ThreadLocalRandom.current().nextInt(10000000);
nums.add(num);
}
Collections.sort(nums);
for (int num : nums) {
writer.println(num);
}
writer.close();
} catch (FileNotFoundException e) {
}
files.add(filename);
}
return files;
}
private List<MergeSource> sources;
private MergeOut out;
public DiskMergeSort(List<String> files, String outFilename) {
this.sources = new ArrayList<>();
for (String filename : files) {
this.sources.add(new MergeSource(filename));
}
this.out = new MergeOut(outFilename);
}
static class MergeOut implements Closeable {
private PrintWriter writer;
public MergeOut(String filename) {
try {
this.writer = new PrintWriter(new FileOutputStream(filename));
} catch (FileNotFoundException e) {
}
}
public void write(Bin bin) {
writer.println(bin.num);
}
@Override
public void close() throws IOException {
writer.flush();
writer.close();
}
}
static class MergeSource implements Closeable {
private BufferedReader reader;
private String cachedLine;
public MergeSource(String filename) {
try {
FileReader fr = new FileReader(filename);
this.reader = new BufferedReader(fr);
} catch (FileNotFoundException e) {
}
}
public boolean hasNext() {
String line;
try {
line = this.reader.readLine();
if (line == null || line.isEmpty()) {
return false;
}
this.cachedLine = line.trim();
return true;
} catch (IOException e) {
}
return false;
}
public int next() {
if (this.cachedLine == null) {
if (!hasNext()) {
throw new IllegalStateException("no content");
}
}
int num = Integer.parseInt(this.cachedLine);
this.cachedLine = null;
return num;
}
@Override
public void close() throws IOException {
this.reader.close();
}
}
static class Bin implements Comparable<Bin> {
int num;
MergeSource source;
Bin(MergeSource source, int num) {
this.source = source;
this.num = num;
}
@Override
public int compareTo(Bin o) {
return this.num - o.num;
}
}
public List<Bin> prepare() {
List<Bin> bins = new ArrayList<>();
for (MergeSource source : sources) {
Bin newBin = new Bin(source, source.next());
bins.add(newBin);
}
Collections.sort(bins);
return bins;
}
public void sort() {
List<Bin> bins = prepare();
while (true) {
MergeSource current = bins.get(0).source;
if (current.hasNext()) {
Bin newBin = new Bin(current, current.next());
int index = Collections.binarySearch(bins, newBin);
if (index == 0 || index == -1) {
this.out.write(newBin);
if (index == -1) {
throw new IllegalStateException("impossible");
}
} else {
if (index < 0) {
index = -index - 1;
}
bins.add(index, newBin);
Bin minBin = bins.remove(0);
this.out.write(minBin);
}
} else {
Bin minBin = bins.remove(0);
this.out.write(minBin);
if (bins.isEmpty()) {
break;
}
}
}
}
@Override
public void close() throws IOException {
for (MergeSource source : sources) {
source.close();
}
this.out.close();
}
public static void main(String[] args) throws IOException {
List<String> inputs = DiskMergeSort.generateFiles(100, 10000, 20000);
// 運行多次看算法耗時
for (int i = 0; i < 20; i++) {
DiskMergeSort sorter = new DiskMergeSort(inputs, "output.txt");
long start = System.currentTimeMillis();
sorter.sort();
long duration = System.currentTimeMillis() - start;
System.out.printf("%dms\n", duration);
sorter.close();
}
}
}
本算法還有一個小缺陷,那就是如果輸入文件數量非常多,那么內存中的數組就會特別大,對數組的插入刪除操作肯定會很耗時,這時可以考慮使用 TreeSet 來代替數組,讀者們可以自行嘗試一下。
關于“在LevelDB數據庫中如何實現磁盤多路歸并排序”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





