溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“搜索引擎工作原理是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
現代意義上的搜索引擎的祖先,是1990年由蒙特利爾大學學生Alan Emtage發明的Archie。即便沒有英特網,網絡中文件傳輸還是相當頻繁的,而且由于大量的文件散布在各個分散的FTP主機中,查詢起來非常不便,因此Alan Emtage想到了開發一個可以以文件名查找文件的系統,于是便有了Archie。Archie工作原理與現在的搜索引擎已經很接近,它依靠腳本程序自動搜索網上的文件,然后對有關信息進行索引,供使用者以一定的表達式查詢。
互聯網興起后,需要能夠監控的工具。世界上第一個用于監測互聯網發展規模的“機器人”程序是Matthew Gray開發的World wide Web Wanderer,剛開始它只用來統計互聯網上的服務器數量,后來則發展為能夠檢索網站域名。
隨著互聯網的迅速發展,每天都會新增大量的網站、網頁,檢索所有新出現的網頁變得越來越困難,因此,在Matthew Gray的Wanderer基礎上,一些編程者將傳統的“蜘蛛”程序工作原理作了些改進。現代搜索引擎都是以此為基礎發展的。
全文搜索引擎
當前主流的是全文搜索引擎,較為典型的代表是Google、百度。全文搜索引擎是指通過從互聯網上提取的各個網站的信息(以網頁文字為主),保存在自己建立的數據庫中。用戶發起檢索請求后,系統檢索與用戶查詢條件匹配的相關記錄,然后按一定的排列順序將結果返回給用戶。從搜索結果來源的角度,全文搜索引擎又可細分為兩種,一種是擁有自己的檢索程序(Indexer),俗稱“蜘蛛”(Spider)程序或“機器人”(Robot)程序,并自建網頁數據庫,搜索結果直接從自身的數據存儲層中調用;另一種則是租用其他引擎的數據庫,并按自定的格式排列搜索結果,如Lycos引擎。
目錄索引類搜索引擎
雖然有搜索功能,但嚴格意義上不能稱為真正的搜索引擎,只是按目錄分類的網站鏈接列表而已。用戶完全可以按照分類目錄找到所需要的信息,不依靠關鍵詞(Keywords)進行查詢。目錄索引中最具代表性的莫過于大名鼎鼎的Yahoo、新浪分類目錄搜索。
元搜索引擎
元搜索引擎在接受用戶查詢請求時,同時在其他多個引擎上進行搜索,并將結果返回給用戶。著名的元搜索引擎有InfoSpace、Dogpile、Vivisimo等,中文元搜索引擎中具代表性的有搜星搜索引擎。在搜索結果排列方面,有的直接按來源引擎排列搜索結果,如Dogpile,有的則按自定的規則將結果重新排列組合,如Vivisimo。
搜索引擎產品雖然一般都只有一個輸入框,但是對于所提供的服務,背后有很多不同業務引擎支撐,每個業務引擎又有很多不同的策略,每個策略又有很多模塊協同處理,及其復雜。
搜索引擎本身包含網頁抓取、網頁評價、反作弊、建庫、倒排索引、索引壓縮、在線檢索、ranking排序策略等等知識。
網絡爬蟲技術
網絡爬蟲技術指的是針對網絡數據的抓取。因為在網絡中抓取數據是具有關聯性的抓取,它就像是一只蜘蛛一樣在互聯網中爬來爬去,所以我們很形象地將其稱為是網絡爬蟲技術。網絡爬蟲也被稱為是網絡機器人或者是網絡追逐者。
網絡爬蟲獲取網頁信息的方式和我們平時使用瀏覽器訪問網頁的工作原理是完全一樣的,都是根據HTTP協議來獲取,其流程主要包括如下步驟:
1)連接DNS域名服務器,將待抓取的URL進行域名解析(URL———>IP);
2)根據HTTP協議,發送HTTP請求來獲取網頁內容。
一個完整的網絡爬蟲基礎框架如下圖所示:

整個架構共有如下幾個過程:
1)需求方提供需要抓取的種子URL列表,根據提供的URL列表和相應的優先級,建立待抓取URL隊列(先來先抓);
2)根據待抓取URL隊列的排序進行網頁抓取;
3)將獲取的網頁內容和信息下載到本地的網頁庫,并建立已抓取URL列表(用于去重和判斷抓取的進程);
4)將已抓取的網頁放入到待抓取的URL隊列中,進行循環抓取操作;
索引
從用戶的角度來看,搜索的過程是通過關鍵字在某種資源中尋找特定的內容的過程。而從計算機的角度來看,實現這個過程可以有兩種辦法。一是對所有資源逐個與關鍵字匹配,返回所有滿足匹配的內容;二是如同字典一樣事先建立一個對應表,把關鍵字與資源的內容對應起來,搜索時直接查找這個表即可。顯而易見,第二個辦法效率要高得多。建立這個對應表事實上就是建立逆向索引(inverted index)的過程。
Lucene
Lucene是一個高性能的java全文檢索工具包,它使用的是倒排文件索引結構。
全文檢索大體分兩個過程,索引創建 (Indexing) 和搜索索引 (Search) 。
索引創建:將現實世界中所有的結構化和非結構化數據提取信息,創建索引的過程。
搜索索引:就是得到用戶的查詢請求,搜索創建的索引,然后返回結果的過程。

非結構化數據中所存儲的信息是每個文件包含哪些字符串,也即已知文件,欲求字符串相對容易,也即是從文件到字符串的映射。而我們想搜索的信息是哪些文件包含此字符串,也即已知字符串,欲求文件,也即從字符串到文件的映射。兩者恰恰相反。于是如果索引總能夠保存從字符串到文件的映射,則會大大提高搜索速度。
由于從字符串到文件的映射是文件到字符串映射的反向過程,于是保存這種信息的索引稱為反向索引 。
反向索引的所保存的信息一般如下:
假設我的文檔集合里面有100篇文檔,為了方便表示,我們為文檔編號從1到100,得到下面的結構

每個字符串都指向包含此字符串的文檔(Document)鏈表,此文檔鏈表稱為倒排表 (Posting List)。
ElasticSearch
Elasticsearch是一個實時的分布式搜索和分析引擎,可以用于全文搜索,結構化搜索以及分析,當然你也可以將這三者進行組合。Elasticsearch是一個建立在全文搜索引擎 Apache Lucene? 基礎上的搜索引擎,但是Lucene只是一個框架,要充分利用它的功能,需要使用JAVA,并且在程序中集成Lucene。Elasticsearch使用Lucene作為內部引擎,但是在使用它做全文搜索時,只需要使用統一開發好的API即可,而不需要了解其背后復雜的Lucene的運行原理。
Solr
Solr是一個基于Lucene的搜索引擎服務器。Solr 提供了層面搜索、命中醒目顯示并且支持多種輸出格式(包括 XML/XSLT 和 JSON 格式)。它易于安裝和配置,而且附帶了一個基于 HTTP 的管理界面。Solr已經在眾多大型的網站中使用,較為成熟和穩定。Solr 包裝并擴展了 Lucene,所以Solr的基本上沿用了Lucene的相關術語。更重要的是,Solr 創建的索引與 Lucene 搜索引擎庫完全兼容。通過對Solr 進行適當的配置,某些情況下可能需要進行編碼,Solr 可以閱讀和使用構建到其他 Lucene 應用程序中的索引。此外,很多 Lucene 工具(如Nutch、 Luke)也可以使用Solr 創建的索引。
Hadoop
谷歌公司發布的一系列技術白皮書導致了Hadoop的誕生。Hadoop是一系列大數據處理工具,可以被用在大規模集群里。Hadoop目前已經發展為一個生態體系,包括了很多組件,如圖所示。

Cloudera是一家將Hadoop技術用于搜索引擎的公司,用戶可以采用全文搜索方式檢索存儲在HDFS(Hadoop分布式文件系統)和Apache HBase里面的數據,再加上開源的搜索引擎Apache Solr,Cloudera提供了搜索功能,并結合Apache ZooKeeper進行分布式處理的管理、索引切分以及高性能檢索。
PageRank
谷歌Pagerank算法基于隨機沖浪模型,基本思想是基于網站之間的相互投票,即我們常說的網站之間互相指向。如果判斷一個網站是高質量站點時,那么該網站應該是被很多高質量的網站引用又或者是該網站引用了大量的高質量權威的站點。
國際化
坦白說,Google雖然做得非常好,無論是技術還是產品設計,都很好。但是國際化確實是非常難做的,很多時候在細分領域還是會有其他搜索引擎的生存余地。例如在韓國,Naver是用戶的首選,它本身基于Yahoo的Overture系統,廣告系統則是自己開發的。在捷克,我們則更多會使用Seznam。在瑞典,用戶更多選擇Eniro,它最初是瑞典的黃頁開發公司。
國際化、個性化搜索、匿名搜索,這些都是Google這樣的產品所不能完全覆蓋到的,事實上,也沒有任何一款產品可以適用于所有需求。
如果我們想要實現搜索引擎,最重要的是索引模塊和搜索模塊。索引模塊在不同的機器上各自進行對資源的索引,并把索引文件統一傳輸到同一個地方(可以是在遠程服務器上,也可以是在本地)。搜索模塊則利用這些從多個索引模塊收集到的數據完成用戶的搜索請求。因此,我們可以理解兩個模塊之間相對是獨立的,它們之間的關聯不是通過代碼,而是通過索引和元數據,如下圖所示。

對于索引的建立,我們需要注意性能問題。當需要進行索引的資源數目不多時,隔一定的時間進行一次完全索引,不會占用很長時間。但在大型應用中,資源的容量是巨大的,如果每次都進行完整的索引,耗費的時間會很驚人。我們可以通過跳過已經索引的資源內容,刪除已不存在的資源內容的索引,并進行增量索引來解決這個問題。這可能會涉及文件校驗和索引刪除等。另一方面,框架可以提供查詢緩存功能,提高查詢效率。框架可以在內存中建立一級緩存,并使用如 OSCache或 EHCache緩存框架,實現磁盤上的二級緩存。當索引的內容變化不頻繁時,使用查詢緩存更會明顯地提高查詢速度、降低資源消耗。
Sphinx
俄羅斯一家公司開源的全文搜索引擎軟件Sphinx,單一索引最大可包含1億條記錄,在1千萬條記錄情況下的查詢速度為0.x秒(毫秒級)。Sphinx創建索引的速度很快,根據網上的資料,Sphinx創建100萬條記錄的索引只需3~4分鐘,創建1000萬條記錄的索引可以在50分鐘內完成,而只包含最新10萬條記錄的增量索引,重建一次只需幾十秒。
OmniFind
OmniFind 是 IBM 公司推出的企業級搜索解決方案。基于 UIMA (Unstructured Information Management Architecture) 技術,它提供了強大的索引和獲取信息功能,支持巨大數量、多種類型的文檔資源(無論是結構化還是非結構化),并為 Lotus?Domino?和 WebSphere?Portal 專門進行了優化。
下一代搜索引擎
從技術和產品層面來看,接下來的幾年,甚至于更長時間,應該沒有哪一家搜索引擎可以撼動谷歌的技術領先優勢和產品地位。但是我們也可以發現一些現象,例如搜索假期租房的時候,人們更喜歡使用Airbub,而不是Google,這就是針對匿名/個性化搜索需求,這些需求是谷歌所不能完全覆蓋到的,畢竟原始數據并不在谷歌。我們可以看一個例子:DuckDuckGo。這是一款有別于大眾理解的搜索引擎,DuckDuckGo強調的是最佳答案,而不是更多的結果,所以每個人搜索相同關鍵詞時,返回的結果是不一樣的。
另一個方面技術趨勢是引入人工智能技術。在搜索體驗上,通過大量算法的引入,對用戶搜索的內容和訪問偏好進行分析,將標題摘要進行一定程度的優化,以更容易理解的方式呈現給用戶。谷歌在搜索引擎AI化的步驟領先于其他廠商,2016年,隨著Amit Singhal被退休,John Giannandrea上位的交接班過程后,正式開啟了自身的革命。Giannandrea是深度神經網絡、近似人腦中的神經元網絡研究方面的頂級專家,通過分析海量級的數字數據,這些神經網絡可以學習排列方式,例如對圖片進行分類、識別智能手機的語音控制等等,對應也可以應用在搜索引擎。因此,Singhal向Giannandrea的過渡,也意味著傳統人為干預的規則設置的搜索引擎向AI技術的過渡。引入深度學習技術之后的搜索引擎,通過不斷的模型訓練,它會深層次地理解內容,并為客戶提供更貼近實際需求的服務,這才是它的有用,或者可怕之處。
Google搜索引擎的工作流程
貼個圖,自己感受下。
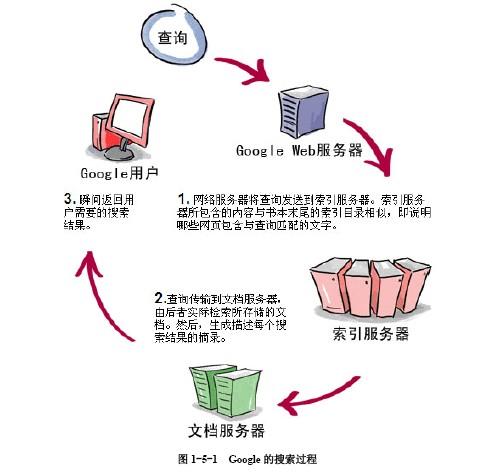
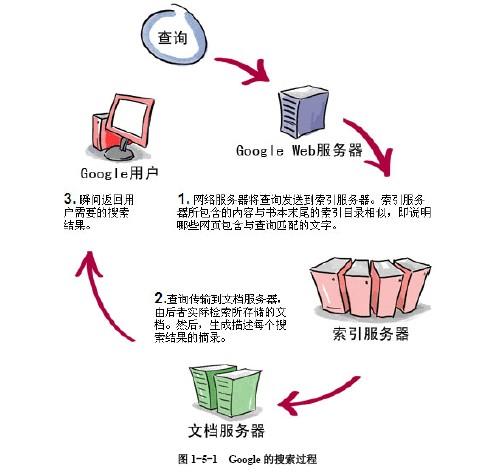
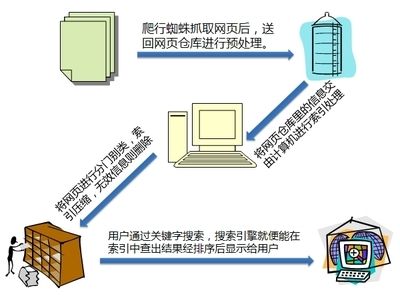
詳細點的 :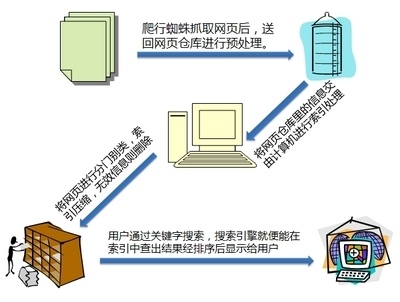
“搜索引擎工作原理是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





