溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
下面講講關于sphinx結合scws對mysql實現全文檢索,文字的奧妙在于貼近主題相關。所以,閑話就不談了,我們直接看下文吧,相信看完sphinx結合scws對mysql實現全文檢索這篇文章你一定會有所受益。
系統環境
主機名 | IP地址 | 相關服務 | 版本 |
SQL | 172.169.18.128 | mysql5.6(主) | |
Sphinx | 172.169.18.210 | mysql5.6(從)php5.6 Apache2.4 | sphinx版本:2.2.10 sphinx插件:1.3.3 scws分詞版本:1.2.3 |
一、簡介
1.1、 Sphinx是什么
參考地址:http://www.sphinxsearch.org/sphinx-tutorial
Sphinx是由俄羅斯人Andrew Aksyonoff開發的一個全文檢索引擎。意圖為其他應用提供高速、低空間占用、高結果 相關度的全文搜索功能。Sphinx可以非常容易的與SQL數據庫和腳本語言集成。當前系統內置MySQL和PostgreSQL 數據庫數據源的支持,也支持從標準輸入讀取特定格式 的XML數據。
Sphinx創建索引的速度為:創建100萬條記錄的索引只需3~4分鐘,創建1000萬條記錄的索引可以在50分鐘內完成,而只包含最新10萬條記錄的增量索引,重建一次只需幾十秒。
1.2、 Sphinx的特性如下:
(1)高速的建立索引(在當代CPU上,峰值性能可達到10 MB/秒);
(2)高性能的搜索(在2 – 4GB 的文本數據上,平均每次檢索響應時間小于0.1秒);
(3)可處理海量數據(目前已知可以處理超過100 GB的文本數據, 在單一CPU的系統上可處理100 M 文檔);
(4)提供了優秀的相關度算法,基于短語相似度和統計(BM25)的復合Ranking方法;
(5) 支持分布式搜索;
(6)支持短語搜索
(7)提供文檔摘要生成
(8)可作為MySQL的存儲引擎提供搜索服務;
(9)支持布爾、短語、詞語相似度等多種檢索模式;
(10)文檔支持多個全文檢索字段(最大不超過32個);
(11)文檔支持多個額外的屬性信息(例如:分組信息,時間戳等);
(12)支持斷詞;
1.3、總結
優點:效率較高,具有較高的擴展性
缺點:不負責數據存儲
使用Sphinx搜索引擎對數據做索引,數據一次性加載進來,然后做了所以之后保存在內存。這樣用戶進行搜索的時候就只需要在Sphinx云服務器上檢索數據即可。而且,Sphinx沒有MySQL的伴隨機磁盤I/O的缺陷,性能更佳。
2.1、SCWS 是 Simple Chinese Word Segmentation 的首字母縮寫(即:簡易中文分詞系統)。
參考地址:http://www.xunsearch.com/scws/index.php
這是一套基于詞頻詞典的機械式中文分詞引擎,它能將一整段的中文文本基本正確地切分成詞。 詞是中文的最小語素單位,但在書寫時并不像英語會在詞之間用空格分開, 所以如何準確并快速分詞一直是中文分詞的攻關難點。
2.2、特性
SCWS 采用純 C 語言開發,不依賴任何外部庫函數,可直接使用動態鏈接庫嵌入應用程序, 支持的中文編碼包括 GBK、UTF-8 等。此外還提供了 PHP 擴展模塊, 可在 PHP 中快速而方便地使用分詞功能。
分詞算法上并無太多創新成分,采用的是自己采集的詞頻詞典,并輔以一定的專有名稱,人名,地名, 數字年代等規則識別來達到基本分詞,經小范圍測試準確率在 90% ~ 95% 之間, 基本上能滿足一些小型搜索引擎、關鍵字提取等場合運用。首次雛形版本發布于 2005 年底。

二、環境準備
1、暫時關閉防火墻
2、關閉seliunx
3、系統環境
centos7.4 mysql5.6 php5.6
三、搭建Sphinx服務
1、安裝依賴包
# yum -y install make gcc gcc-c++ libtool autoconf automake mysql-devel
2、安裝Sphinx
# yum install expat expat-devel
# wget -c http://sphinxsearch.com/files/sphinx-2.2.10-release.tar.gz
# tar -zxvf sphinx-2.2.10-release.tar.gz
# cd sphinx-2.2.10-release/
# ./configure --prefix=/usr/local/sphinx --with-mysql --with-libexpat --enable-id64
# make && make install
3、安裝libsphinxclient,php擴展用到
# cd api/libsphinxclient/
# ./configure --prefix=/usr/local/sphinx/libsphinxclient
# make && make install
安裝完畢后查看一下/usr/local/sphinx下是否有 三個目錄 bin etc var,如有,則安裝無誤!
4、安裝Sphinx的PHP擴展:我的是5.6需裝sphinx-1.3.3.tgz,如果是php5.4以下可sphinx-1.3.0.tgz,如果php7.0需要安裝sphinx-339e123.tar.gz(http://git.php.net/?p=pecl/search_engine/sphinx.git;a=snapshot;h=339e123acb0ce7beb2d9d4f9094d6f8bcf15fb54;sf=tgz)
# wget -c http://pecl.php.net/get/sphinx-1.3.3.tgz
# tar zxvf sphinx-1.3.3.tgz
# cd sphinx-1.3.3/
# phpize

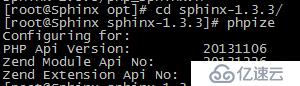
# ./configure --with-sphinx=/usr/local/sphinx/libsphinxclient/ --with-php-config=/usr/bin/php-config
# make && make install
# 成功后會提示:
Installing shared extensions: /usr/lib64/php/modules/


#修改php配置
# echo "[Sphinx]" >> /etc/php.ini
# echo "extension = sphinx.so" >> /etc/php.ini
#重啟httpd服務
# systemctl restart httpd.service
5、創建測試數據進行測試(db:jiangjj)
CREATE TABLE IF NOT EXISTS `items` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL,
`content` text NOT NULL,
`created` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='全文檢索測試的數據表' AUTO_INCREMENT=11 ;
INSERT INTO `items` (`id`, `title`, `content`, `created`) VALUES
(1, 'linux mysql集群安裝', 'MySQL Cluster 是MySQL 適合于分布式計算環境的高實用、可拓展、高性能、高冗余版本', '2016-09-07 00:00:00'),
(2, 'mysql主從復制', 'mysql主從備份(復制)的基本原理 mysql支持單向、異步復制,復制過程中一個云服務器充當主云服務器,而一個或多個其它云服務器充當從云服務器', '2016-09-06 00:00:00'),
(3, 'hello', 'can you search me?', '2016-09-05 00:00:00'),
(4, 'mysql', 'mysql is the best database?', '2016-09-03 00:00:00'),
(5, 'mysql索引', '關于MySQL索引的好處,如果正確合理設計并且使用索引的MySQL是一輛蘭博基尼的話,那么沒有設計和使用索引的MySQL就是一個人力三輪車', '2016-09-01 00:00:00'),
(6, '集群', '關于MySQL索引的好處,如果正確合理設計并且使用索引的MySQL是一輛蘭博基尼的話,那么沒有設計和使用索引的MySQL就是一個人力三輪車', '0000-00-00 00:00:00'),
(9, '復制原理', 'redis也有復制', '0000-00-00 00:00:00'),
(10, 'redis集群', '集群技術是構建高性能網站架構的重要手段,試想在網站承受高并發訪問壓力的同時,還需要從海量數據中查詢出滿足條件的數據,并快速響應,我們必然想到的是將數據進行切片,把數據根據某種規則放入多個不同的云服務器節點,來降低單節點云服務器的壓力', '0000-00-00 00:00:00');
CREATE TABLE IF NOT EXISTS `sph_counter` (
`counter_id` int(11) NOT NULL,
`max_doc_id` int(11) NOT NULL,
PRIMARY KEY (`counter_id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='增量索引標示的計數表';
6、Sphinx配置:注意修改數據源配置信息。
配置地址:http://www.cnblogs.com/yjf512/p/3598332.html
以下采用"Main + Delta" ("主索引"+"增量索引")的索引策略,使用Sphinx自帶的一元分詞。
# vim /usr/local/sphinx/etc/sphinx.conf
source items {
type = mysql
sql_host = 172.169.18.128
sql_user = jiangjj
sql_pass = 123456
sql_db = jiangjj
sql_query_pre = SET NAMES utf8
sql_query_pre = SET SESSION query_cache_type = OFF
sql_query_pre = REPLACE INTO sph_counter SELECT 1, MAX(id) FROM items
sql_query_range = SELECT MIN(id), MAX(id) FROM items \
WHERE id<=(SELECT max_doc_id FROM sph_counter WHERE counter_id=1)
sql_range_step = 1000
sql_ranged_throttle = 1000
sql_query = SELECT id, title, content, created, 0 as deleted FROM items \
WHERE id<=(SELECT max_doc_id FROM sph_counter WHERE counter_id=1) \
AND id >= $start AND id <= $end
sql_attr_timestamp = created
sql_attr_bool = deleted
}
source items_delta : items {
sql_query_pre = SET NAMES utf8
sql_query_range = SELECT MIN(id), MAX(id) FROM items \
WHERE id > (SELECT max_doc_id FROM sph_counter WHERE counter_id=1)
sql_query = SELECT id, title, content, created, 0 as deleted FROM items \
WHERE id>( SELECT max_doc_id FROM sph_counter WHERE counter_id=1 ) \
AND id >= $start AND id <= $end
sql_query_post_index = set @max_doc_id :=(SELECT max_doc_id FROM sph_counter WHERE counter_id=1)
sql_query_post_index = REPLACE INTO sph_counter SELECT 2, IF($maxid, $maxid, @max_doc_id)
}
#主索引
index items {
source = items
path = /usr/local/sphinx/var/data/items
docinfo = extern
morphology = none
min_word_len = 1
min_prefix_len = 0
html_strip = 1
html_remove_elements = style, script
ngram_len = 1
ngram_chars = U+3000..U+2FA1F
charset_type = utf-8
charset_table = 0..9, A..Z->a..z, _, a..z, U+410..U+42F->U+430..U+44F, U+430..U+44F
preopen = 1
min_infix_len = 1
}
#增量索引
index items_delta : items {
source = items_delta
path = /usr/local/sphinx/var/data/items_delta
}
#分布式索引
index master {
type = distributed
local = items
local = items_delta
}
indexer {
mem_limit = 256M
}
searchd {
listen = 9312
listen = 9306:mysql41
log = /usr/local/sphinx/var/log/searchd.log
query_log = /usr/local/sphinx/var/log/query.log
# compat_sphinxql_magics = 0
attr_flush_period = 600
mva_updates_pool = 16M
read_timeout = 5
max_children = 0
dist_threads = 2
pid_file = /usr/local/sphinx/var/log/searchd.pid
# max_marches = 1000
seamless_rotate = 1
preopen_indexes = 1
unlink_old = 1
workers = threads
binlog_path = /usr/local/sphinx/var/data
}
7、Sphinx創建索引
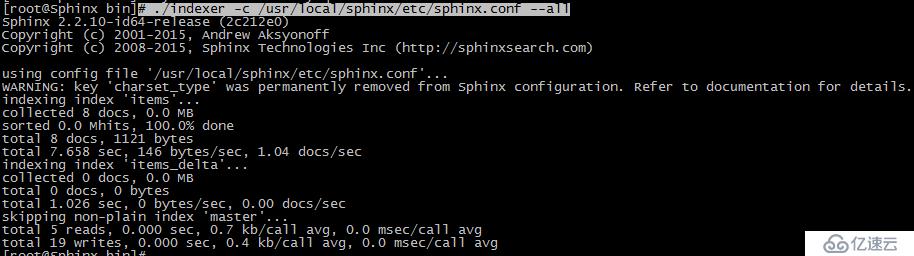
# cd /usr/local/sphinx/bin/
#第一次重建索引
# ./indexer -c /usr/local/sphinx/etc/sphinx.conf --all

#啟動sphinx
# ./searchd -c /usr/local/sphinx/etc/sphinx.conf


#查看進程
# ps -ef | grep searchd


#查看狀態
# ./searchd -c /usr/local/sphinx/etc/sphinx.conf --status
#關閉sphinx
# ./searchd -c /usr/local/sphinx/etc/sphinx.conf --stop
8、索引更新及使用說明
"增量索引"每N分鐘更新一次.通常在每天晚上低負載的時進行一次索引合并,同時重新建立"增量索引"。當然"主索引"數據不多的話,也可以直接重新建立"主索引"。
API搜索的時,同時使用"主索引"和"增量索引",這樣可以獲得準實時的搜索數據.本文的Sphinx配置將"主索引"和"增量索引"放到分布式索引master中,因此只需查詢分布式索引"master"即可獲得全部匹配數據(包括最新數據)。
索引的更新與合并的操作可以放到cron job完成:
8.1、編輯
# crontab -e
*/1 * * * * /usr/local/sphinx/shell/index_update.sh
0 3 * * * /usr/local/sphinx/shell/merge_index.sh
//查看
# crontab -l
8.2、腳本如下
#更新腳本
# vim /usr/local/sphinx/shell/index_update.sh
#!/bin/sh
/usr/local/sphinx/bin/indexer -c /usr/local/sphinx/etc/sphinx.conf --rotate items_delta > /dev/null 2>&1
#合并腳本
[root@Sphinx shell]# vim merge_index.sh
#!/bin/bash
indexer=/usr/local/sphinx/bin/indexer
mysql=`which mysql`
#host=172.169.18.128
#mysql_user=jiangjj
#mysql_password=123456
QUERY="use jiangjj;select max_doc_id from sph_counter where counter_id = 2 limit 1;"
index_counter=$($mysql -h272.169.18.128 -ujiangjj -p123456 -sN -e "$QUERY")
#merge "main + delta" indexes
$indexer -c /usr/local/sphinx/etc/sphinx.conf --rotate --merge items items_delta --merge-dst-range deleted 0 0 >> /usr/local/sphinx/var/index_merge.log 2>&1
if [ "$?" -eq 0 ]; then
##update sphinx counter
if [ ! -z $index_counter ]; then
$mysql -h272.169.18.128 -ujiangjj -p123456 -Djiangjj -e "REPLACE INTO sph_counter VALUES (1, '$index_counter')"
fi
##rebuild delta index to avoid confusion with main index
$indexer -c /usr/local/sphinx/etc/sphinx.conf --rotate items_delta >> /usr/local/sphinx/var/rebuild_deltaindex.log 2>&1
fi
#授權
# chmod u+x *.sh
測試沒問題后繼續下一步操作
四、搭建scws(中文分詞)服務
下載地址:http://www.xunsearch.com/scws/download.php


1、scws下載安裝:注意擴展的版本和php的版本
# wget -c http://www.xunsearch.com/scws/down/scws-1.2.3.tar.bz2
# tar jxvf scws-1.2.3.tar.bz2
# cd scws-1.2.3/
# ./configure --prefix=/usr/local/scws
# make && make install
2、scws的PHP擴展安裝
# cd ./phpext/
# phpize
# ./configure


# make && make install
編譯完成狀態如下:


#修改php配置文件
[root@Sphinx ~]# echo "[scws]" >> /etc/php.ini
[root@Sphinx ~]# echo "extension = scws.so" >> /etc/php.ini
[root@Sphinx ~]# echo "scws.default.charset = utf-8" >> /etc/php.ini
[root@Sphinx ~]# echo "scws.default.fpath = /usr/local/scws/etc/" >> /etc/php.ini
3、詞庫安裝


下載地址:http://www.xunsearch.com/scws/down/scws-dict-chs-utf8.tar.bz2
# wget http://www.xunsearch.com/scws/down/scws-dict-chs-utf8.tar.bz2
# tar jxvf scws-dict-chs-utf8.tar.bz2 -C /usr/local/sphinx/etc/
# chown -R apache:apache /usr/local/sphinx/etc/dict.utf8.xdb
五、php使用Sphinx+scws測試
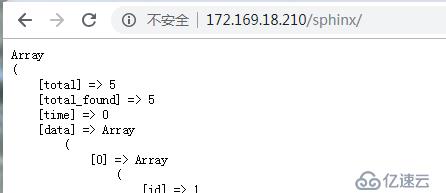
1、在Sphinx源碼API中,有好幾種語言的API調用.其中有一個是sphinxapi.php。
新建一個Search.php文件,一個前端頁面index.php
代碼省略
訪問:

2、SphinxQL測試
要使用SphinxQL需要在Searchd的配置里面增加相應的監聽端口(參考上文配置)。
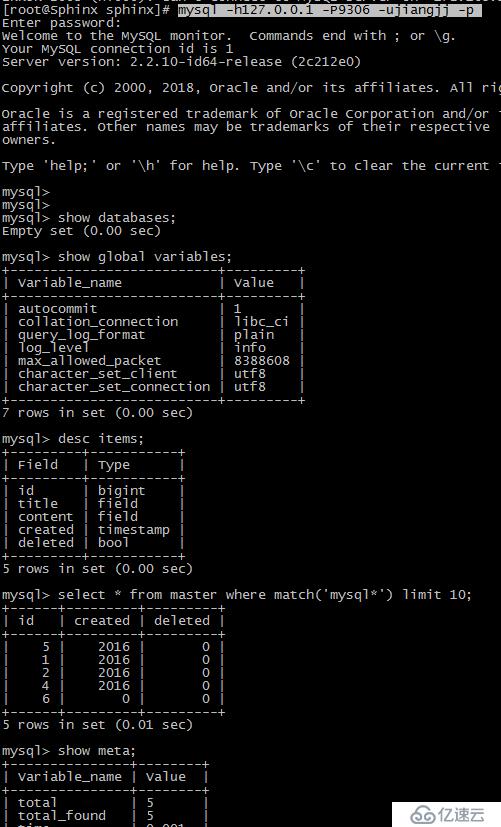
# mysql -h227.0.0.1 -P9306 -ujiangjj -p
mysql> show global variables;
mysql> desc items;
mysql> select * from master where match('mysql*') limit 10;
mysql> show meta;

對于以上sphinx結合scws對mysql實現全文檢索相關內容,大家還有什么不明白的地方嗎?或者想要了解更多相關,可以繼續關注我們的行業資訊板塊。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





