溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“怎么將csv包含的數據導入SAP Cloud Platform HANA MDC里”,在日常操作中,相信很多人在怎么將csv包含的數據導入SAP Cloud Platform HANA MDC里問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”怎么將csv包含的數據導入SAP Cloud Platform HANA MDC里”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
本文使用的csv文件

SAP HANA XS) enables you to create database schema, tables, views, and sequences as design-time files in the repository.
這個練習里,我們將會使用SAP HANA Extended Application Services (XS)提供的database schema,tables和views來實現數據導入的效果。
The HDBtable syntax is a collective term which includes the different configuration schema for each of the various design-time data artifacts, for example: schema (.hdbschema), sequence (.hdbsequence), table (.hdbtable), and view (.hdbview).
This is why we will be using the SAP HANA HDBtable syntax including Core Data Service (CDS) artifacts instead, which only requires the SAP HANA Web-based Development Workbench available with any SAP HANA MDC on the SAP Cloud Platform. All the objects will be created as design-time and will allow us to adapt the structure easily without reloading the data.
首先在SAP Cloud Platform Neo環境的HANA MDC實例里,打開HANA Web-based development workbench,切換到Catalog視圖:
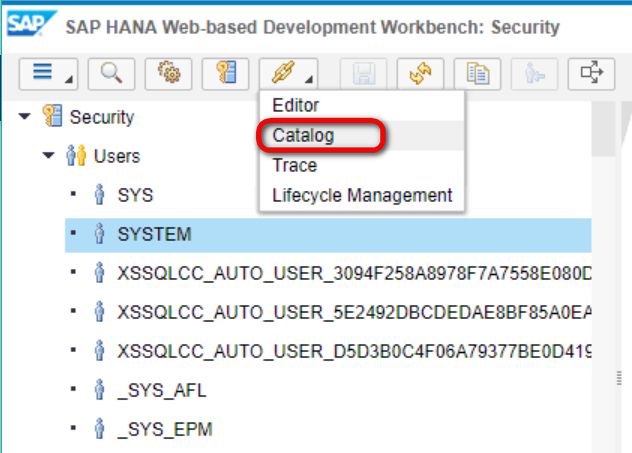
點擊SQL,使用SQL語句創建一個新的user: MOVIELENS_USER
DROP USER MOVIELENS_USER CASCADE;
CREATE USER MOVIELENS_USER PASSWORD Welcome18Welcome18 NO FORCE_FIRST_PASSWORD_CHANGE;
ALTER USER MOVIELENS_USER DISABLE PASSWORD LIFETIME;
call _SYS_REPO.GRANT_ACTIVATED_ROLE ('sap.hana.ide.roles::CatalogDeveloper' ,'MOVIELENS_USER');
call _SYS_REPO.GRANT_ACTIVATED_ROLE ('sap.hana.ide.roles::Developer' ,'MOVIELENS_USER');
call _SYS_REPO.GRANT_ACTIVATED_ROLE ('sap.hana.ide.roles::EditorDeveloper' ,'MOVIELENS_USER');
call _SYS_REPO.GRANT_ACTIVATED_ROLE ('sap.hana.xs.ide.roles::CatalogDeveloper' ,'MOVIELENS_USER');
call _SYS_REPO.GRANT_ACTIVATED_ROLE ('sap.hana.xs.ide.roles::Developer' ,'MOVIELENS_USER');
call _SYS_REPO.GRANT_ACTIVATED_ROLE ('sap.hana.xs.ide.roles::EditorDeveloper' ,'MOVIELENS_USER');
GRANT EXECUTE on _SYS_REPO.GRANT_ACTIVATED_ROLE TO MOVIELENS_USER WITH GRANT OPTION;
GRANT EXECUTE on _SYS_REPO.GRANT_SCHEMA_PRIVILEGE_ON_ACTIVATED_CONTENT TO MOVIELENS_USER WITH GRANT OPTION;
GRANT EXECUTE on _SYS_REPO.GRANT_PRIVILEGE_ON_ACTIVATED_CONTENT TO MOVIELENS_USER WITH GRANT OPTION;
GRANT EXECUTE on _SYS_REPO.REVOKE_ACTIVATED_ROLE TO MOVIELENS_USER WITH GRANT OPTION;
GRANT EXECUTE on _SYS_REPO.REVOKE_SCHEMA_PRIVILEGE_ON_ACTIVATED_CONTENT TO MOVIELENS_USER WITH GRANT OPTION;
GRANT EXECUTE on _SYS_REPO.REVOKE_PRIVILEGE_ON_ACTIVATED_CONTENT TO MOVIELENS_USER WITH GRANT OPTION;
GRANT "CREATE SCHEMA" TO MOVIELENS_USER;
GRANT REPO.READ on "public" TO MOVIELENS_USER;
GRANT REPO.MAINTAIN_IMPORTED_PACKAGES on "public" TO MOVIELENS_USER;
GRANT REPO.MAINTAIN_NATIVE_PACKAGES on "public" TO MOVIELENS_USER;
GRANT REPO.EDIT_NATIVE_OBJECTS on "public" TO MOVIELENS_USER;
GRANT REPO.EDIT_IMPORTED_OBJECTS on "public" TO MOVIELENS_USER;
GRANT REPO.ACTIVATE_NATIVE_OBJECTS on "public" TO MOVIELENS_USER;
GRANT REPO.ACTIVATE_IMPORTED_OBJECTS on "public" TO MOVIELENS_USER;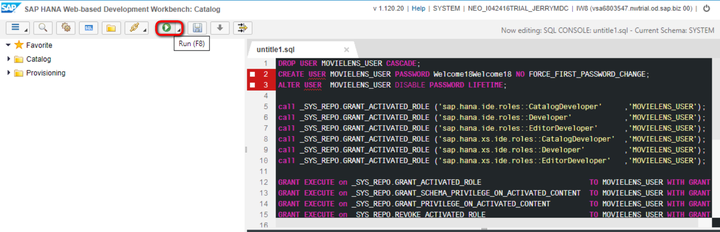
執行后,該用戶創建成功:
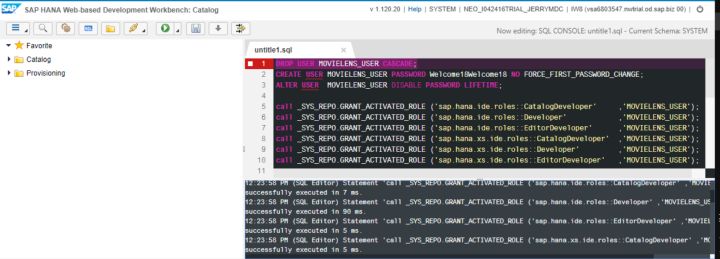
注銷SYSTEM用戶,使用新創建的用戶登錄:

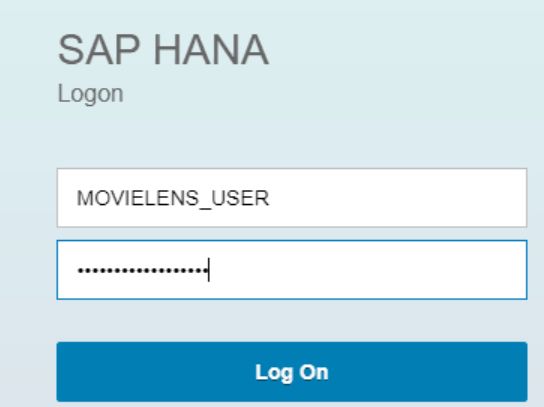
切換到Editor視圖:
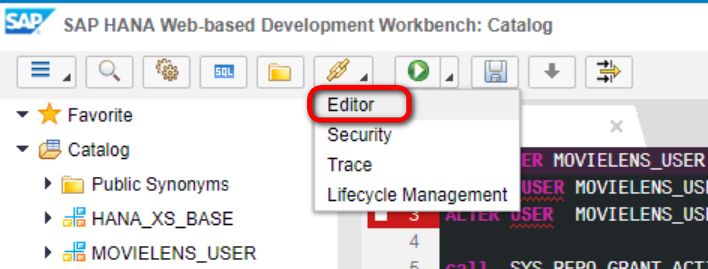
在content節點下,右鍵菜單,新建一個Application:

Package維護成public.aa.movielens:
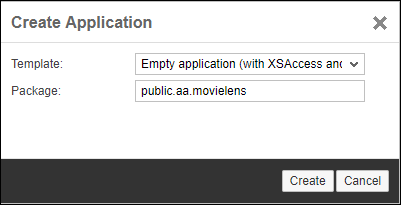

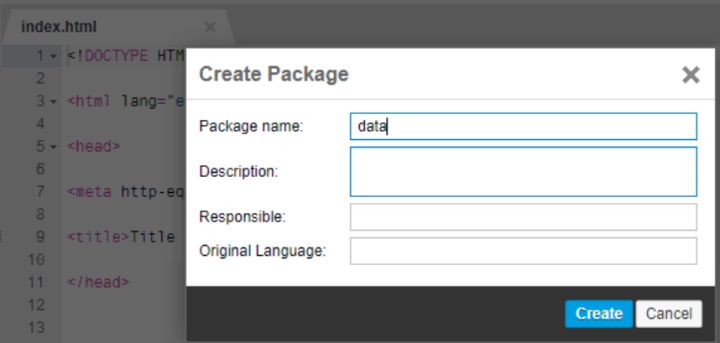
新建三個package,分別為data, hdb和service:
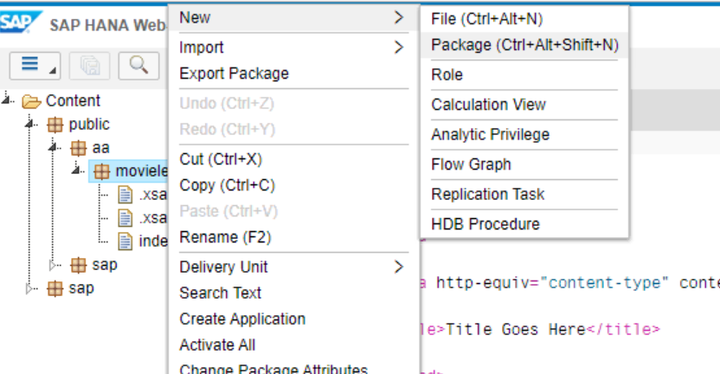
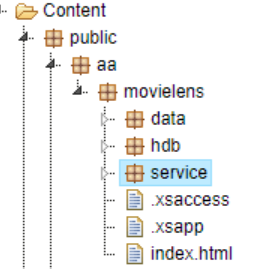
將之前鏈接里提供的csv文件導入data package內:
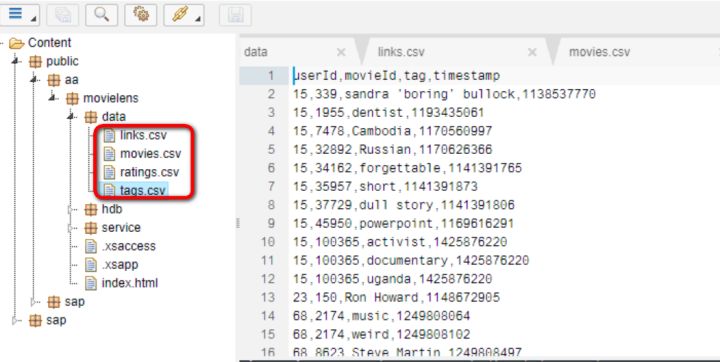
HANA schema是存放HANA數據庫對象諸如表,視圖,存儲過程等的容器。
新建一個.hdbschema文件,內容如下:
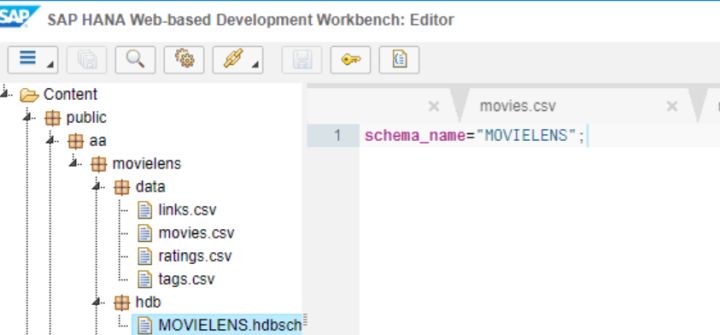
再創建一個user.hdbrole文件:
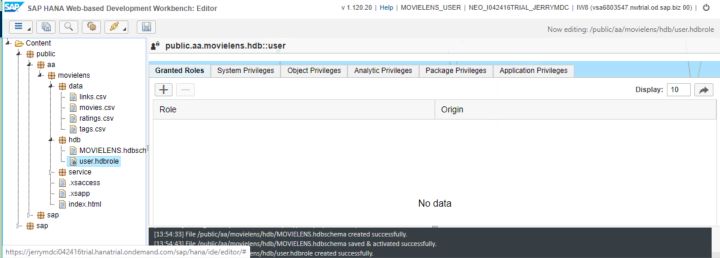
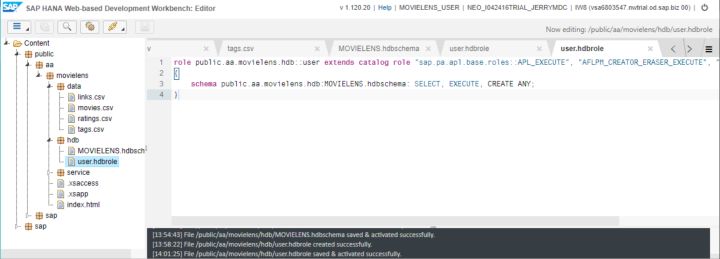
內容如下:
role public.aa.movielens.hdb::user extends catalog role "sap.pa.apl.base.roles::APL_EXECUTE", "AFLPM_CREATOR_ERASER_EXECUTE", "AFL__SYS_AFL_AFLPAL_EXECUTE"
{
schema public.aa.movielens.hdb:MOVIELENS.hdbschema: SELECT, EXECUTE, CREATE ANY;
}這個role定義了我們創建的這個應用工作時需要的權限:
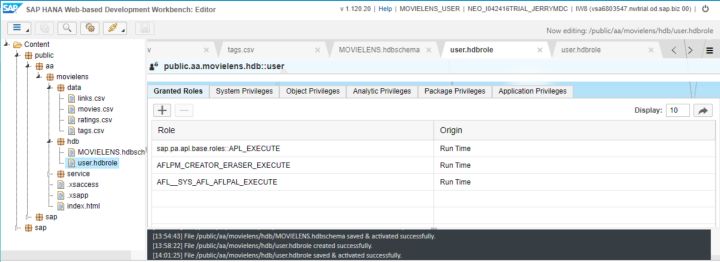
最后創建CDS artifacts:
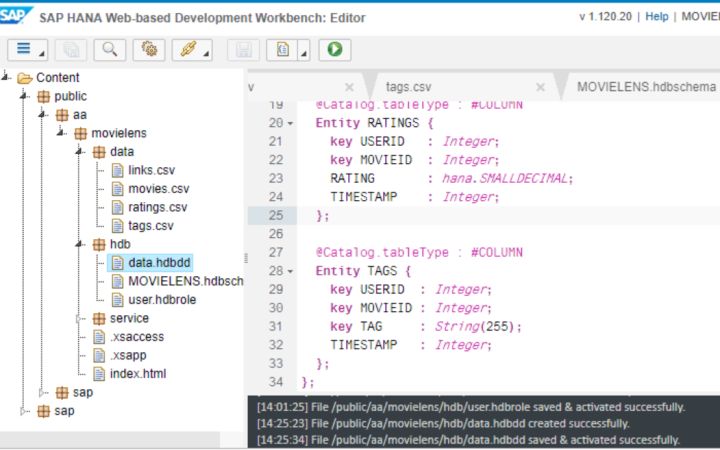
新建一個data.hdbdd文件:
namespace public.aa.movielens.hdb;
@Schema : 'MOVIELENS'
context "data" {
@Catalog.tableType : #COLUMN
Entity LINKS {
key MOVIEID : Integer;
IMDBID : Integer;
TMDBID : Integer;
};
@Catalog.tableType : #COLUMN
Entity MOVIES {
key MOVIEID : Integer;
TITLE : String(255);
GENRES : String(255);
};
@Catalog.tableType : #COLUMN
Entity RATINGS {
key USERID : Integer;
key MOVIEID : Integer;
RATING : hana.SMALLDECIMAL;
TIMESTAMP : Integer;
};
@Catalog.tableType : #COLUMN
Entity TAGS {
key USERID : Integer;
key MOVIEID : Integer;
key TAG : String(255);
TIMESTAMP : Integer;
};
};
使用下列的SQL語句將新創建的user role分配給用戶MOVIELENS_USER:

創建一個table-import配置文件,在里面指定存儲于csv文件里的數據,按照怎樣的邏輯寫入HANA MDC的持久化對象,比如數據庫表里。
hdb package里創建一個新的文件data.hdbti :
import = [
{
table = "public.aa.movielens.hdb::data.LINKS";
schema = "MOVIELENS" ;
file = "public.aa.movielens.data:links.csv";
header = true;
delimField = ",";
delimEnclosing= "\"";
},
{
table = "public.aa.movielens.hdb::data.MOVIES";
schema = "MOVIELENS" ;
file = "public.aa.movielens.data:movies.csv";
header = true;
delimField = ",";
delimEnclosing = "\"";
},
{
table = "public.aa.movielens.hdb::data.RATINGS";
schema = "MOVIELENS" ;
file = "public.aa.movielens.data:ratings.csv";
header = true;
delimField = ",";
delimEnclosing= "\"";
},
{
table = "public.aa.movielens.hdb::data.TAGS";
schema = "MOVIELENS" ;
file = "public.aa.movielens.data:tags.csv";
header = true;
delimField = ",";
delimEnclosing= "\"";
}
];此時執行下列SQL語句,就可以成功從HANA MDC實例的數據庫表里讀取源自csv文件里的數據了:
select 'links' as "table name", count(1) as "row count" from "MOVIELENS"."public.aa.movielens.hdb::data.LINKS" union all select 'movies' as "table name", count(1) as "row count" from "MOVIELENS"."public.aa.movielens.hdb::data.MOVIES" union all select 'ratings' as "table name", count(1) as "row count" from "MOVIELENS"."public.aa.movielens.hdb::data.RATINGS" union all select 'tags' as "table name", count(1) as "row count" from "MOVIELENS"."public.aa.movielens.hdb::data.TAGS";

到此,關于“怎么將csv包含的數據導入SAP Cloud Platform HANA MDC里”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





