溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
PouchContainer CRI的設計與實現方法是怎樣的,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
1. CRI簡介
在每個Kubernetes節點的最底層都有一個程序負責具體的容器創建刪除工作,Kubernetes會對其接口進行調用,從而完成容器的編排調度。我們將這一層軟件稱之為容器運行時(Container Runtime),大名鼎鼎的Docker就是其中的代表。
當然,容器運行時并非只有Docker一種,包括CoreOS的rkt,hyper.sh的runV,Google的gvisor,以及本文的主角PouchContainer,都包含了完整的容器操作,能夠用來創建特性各異的容器。不同的容器運行時有著各自獨特的優點,能夠滿足不同用戶的需求,因此Kubernetes支持多種容器運行時勢在必行。
最初,Kubernetes原生內置了對Docker的調用接口,之后社區又在Kubernetes 1.3中集成了rkt的接口,使其成為了Docker以外,另一個可選的容器運行時。不過,此時不論是對于Docker還是對于rkt的調用都是和Kubernetes的核心代碼強耦合的,這無疑會帶來如下兩方面的問題:
新興的容器運行時,例如PouchContainer這樣的后起之秀,加入Kubernetes生態難度頗大。容器運行時的開發者必須對于Kubernetes的代碼(至少是Kubelet)有著非常深入的理解,才能順利完成兩者之間的對接。
Kubernetes的代碼將更加難以維護,這也體現在兩方面:(1)將各種容器運行時的調用接口全部硬編碼進Kubernetes,會讓Kubernetes的核心代碼變得臃腫不堪,(2)容器運行時接口細微的改動都會引發Kubernetes核心代碼的修改,增加Kubernetes的不穩定性
為了解決這些問題,社區在Kubernetes 1.5引入了CRI(Container Runtime Interface),通過定義一組容器運行時的公共接口將Kubernetes對于各種容器運行時的調用接口屏蔽至核心代碼以外,Kubernetes核心代碼只對該抽象接口層進行調用。而對于各種容器運行時,只要滿足了CRI中定義的各個接口就能順利接入Kubernetes,成為其中的一個容器運行時選項。方案雖然簡單,但是對于Kubernetes社區維護者和容器運行時開發者來說,都是一種解放。
2. CRI設計概述
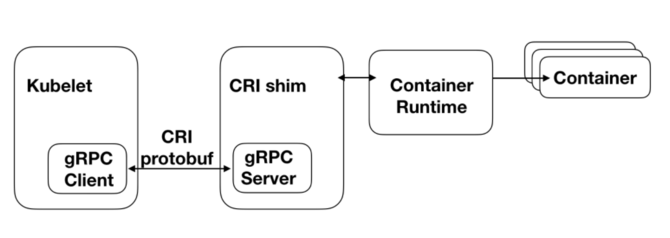
如上圖所示,左邊的Kubelet是Kubernetes集群的Node Agent,它會對本節點上容器的狀態進行監控,保證它們都按照預期狀態運行。為了實現這一目標,Kubelet會不斷調用相關的CRI接口來對容器進行同步。
CRI shim則可以認為是一個接口轉換層,它會將CRI接口,轉換成對應底層容器運行時的接口,并調用執行,返回結果。對于有的容器運行時,CRI shim是作為一個獨立的進程存在的,例如當選用Docker為Kubernetes的容器運行時,Kubelet初始化時,會附帶啟動一個Docker shim進程,它就是Docker的CRI shime。而對于PouchContainer,它的CRI shim則是內嵌在Pouchd中的,我們將其稱之為CRI manager。關于這一點,我們會在下一節討論PouchContainer相關架構時再詳細敘述。
CRI本質上是一套gRPC接口,Kubelet內置了一個gRPC Client,CRI shim中則內置了一個gRPC Server。Kubelet每一次對CRI接口的調用,都將轉換為gRPC請求由gRPC Client發送給CRI shim中的gRPC Server。Server調用底層的容器運行時對請求進行處理并返回結果,由此完成一次CRI接口調用。
CRI定義的gRPC接口可劃分兩類,ImageService和RuntimeService:其中ImageService負責管理容器的鏡像,而RuntimeService則負責對容器生命周期進行管理以及與容器進行交互(exec/attach/port-forward)。
3. CRI Manager架構設計
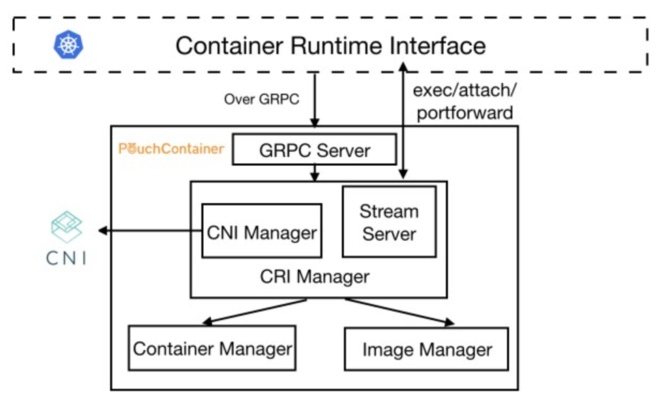
在PouchContainer的整個架構體系中,CRI Manager實現了CRI定義的全部接口,擔任了PouchContainer中CRI shim的角色。當Kubelet調用一個CRI接口時,請求就會通過Kubelet的gRPC Client發送到上圖的gRPC Server中。Server會對請求進行解析,并調用CRI Manager相應的方法進行處理。
我們先通過一個例子來簡單了解一下各個模塊的功能。例如,當到達的請求為創建一個Pod,那么CRI Manager會先將獲取到的CRI格式的配置轉換成符合PouchContainer接口要求的格式,調用Image Manager拉取所需的鏡像,再調用Container Manager創建所需的容器,并調用CNI Manager,利用CNI插件對Pod的網絡進行配置。最后,Stream Server會對交互類型的CRI請求,例如exec/attach/portforward進行處理。
值得注意的是,CNI Manager和Stream Server是CRI Manager的子模塊,而CRI Manager,Container Manager以及Image Manager是三個平等的模塊,它們都位于同一個二進制文件Pouchd中,因此它們之間的調用都是最為直接的函數調用,并不存在例如Docker shim與Docker交互時,所需要的遠程調用開銷。下面,我們將進入CRI Manager內部,對其中重要功能的實現做更為深入的理解。
4. Pod模型的實現
在Kubernetes的世界里,Pod是最小的調度部署單元。簡單地說,一個Pod就是由一些關聯較為緊密的容器構成的容器組。作為一個整體,這些“親密”的容器之間會共享一些東西,從而讓它們之間的交互更為高效。例如,對于網絡,同一個Pod中的容器會共享同一個IP地址和端口空間,從而使它們能直接通過localhost互相訪問。對于存儲,Pod中定義的volume會掛載到其中的每個容器中,從而讓每個容器都能對其進行訪問。
事實上,只要一組容器之間共享某些Linux Namespace以及掛載相同的volume就能實現上述的所有特性。下面,我們就通過創建一個具體的Pod來分析PouchContainer中的CRI Manager是如何實現Pod模型的:
1、當Kubelet需要新建一個Pod時,首先會對RunPodSandbox這一CRI接口進行調用,而CRI Manager對該接口的實現是創建一個我們稱之為"infra container"的特殊容器。從容器實現的角度來看,它并不特殊,無非是調用Container Manager,創建一個鏡像為pause-amd64:3.0的普通容器。但是從整個Pod容器組的角度來看,它是有著特殊作用的,正是它將自己的Linux Namespace貢獻出來,作為上文所說的各容器共享的Linux Namespace,將容器組中的所有容器聯結到一起。它更像是一個載體,承載了Pod中所有其他的容器,為它們的運行提供基礎設施。而一般我們也用infra container代表一個Pod。
2、在infra container創建完成之后,Kubelet會對Pod容器組中的其他容器進行創建。每創建一個容器就是連續調用CreateContainer和StartContainer這兩個CRI接口。對于CreateContainer,CRI Manager僅僅只是將CRI格式的容器配置轉換為PouchContainer格式的容器配置,再將其傳遞給Container Manager,由其完成具體的容器創建工作。這里我們唯一需要關心的問題是,該容器如何加入上文中提到的infra container的Linux Namespace。其實真正的實現非常簡單,在Container Manager的容器配置參數中有PidMode, IpcMode以及NetworkMode三個參數,分別用于配置容器的Pid Namespace,Ipc Namespace和Network Namespace。籠統地說,對于容器的Namespace的配置一般都有兩種模式:"None"模式,即創建該容器自己獨有的Namespace,另一種即為"Container"模式,即加入另一個容器的Namespace。顯然,我們只需要將上述三個參數配置為"Container"模式,加入infra container的Namespace即可。具體是如何加入的,CRI Manager并不需要關心。對于StartContainer,CRI Manager僅僅只是做了一層轉發,從請求中獲取容器ID并調用Container Manager的Start接口啟動容器。
3、最后,Kubelet會不斷調用ListPodSandbox和ListContainers這兩個CRI接口來獲取本節點上容器的運行狀態。其中ListPodSandbox羅列的其實就是各個infra container的狀態,而ListContainer羅列的是除了infra container以外其他容器的狀態。現在問題是,對于Container Manager來說,infra container和其他container并不存在任何區別。那么CRI Manager是如何對這些容器進行區分的呢?事實上,CRI Manager在創建容器時,會在已有容器配置的基礎之上,額外增加一個label,標志該容器的類型。從而在實現ListPodSandbox和ListContainers接口的時候,以該label的值作為條件,就能對不同類型的容器進行過濾。
綜上,對于Pod的創建,我們可以概述為先創建infra container,再創建pod中的其他容器,并讓它們加入infra container的Linux Namespace。
5. Pod網絡配置
因為Pod中所有的容器都是共享Network Namespace的,因此我們只需要在創建infra container的時候,對它的Network Namespace進行配置即可。
在Kubernetes生態體系中容器的網絡功能都是由CNI實現的。和CRI類似,CNI也是一套標準接口,各種網絡方案只要實現了該接口就能無縫接入Kubernetes。CRI Manager中的CNI Manager就是對CNI的簡單封裝。它在初始化的過程中會加載目錄/etc/cni/net.d下的配置文件,如下所示:
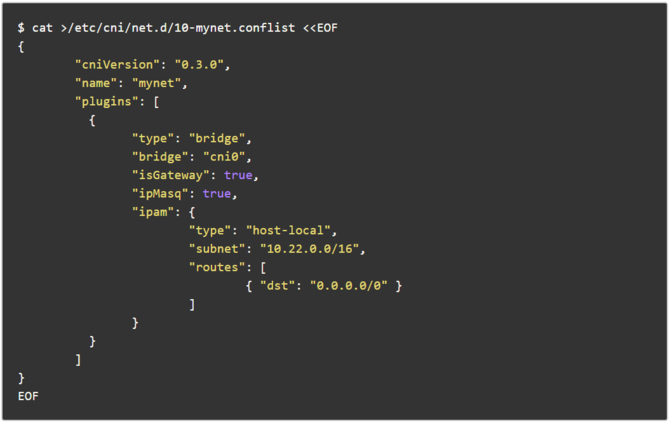
其中指定了配置Pod網絡會使用到的CNI插件,例如上文中的bridge,以及一些網絡配置信息,例如本節點Pod所屬的子網范圍和路由配置。
下面我們就通過具體的步驟來展示如何將一個Pod加入CNI網絡:
1、當調用container manager創建infra container時,將NetworkMode設置為"None"模式,表示創建一個該infra container獨有的Network Namespace且不做任何配置。
2、根據infra container對應的PID,獲取其對應的Network Namespace路徑/proc/{pid}/ns/net。
3、調用CNI Manager的SetUpPodNetwork方法,核心參數為步驟二中獲取的Network Namespace路徑。該方法做的工作就是調用CNI Manager初始化時指定的CNI插件,例如上文中的bridge,對參數中指定的Network Namespace進行配置,包括創建各種網絡設備,進行各種網絡配置,將該Network Namespace加入插件對應的CNI網絡中。
對于大多數Pod,網絡配置都是按照上述步驟操作的,大部分的工作將由CNI以及對應的CNI插件替我們完成。但是對于一些特殊的Pod,它們會將自己的網絡模式設置為"Host",即和宿主機共享Network Namespace。這時,我們只需要在調用Container Manager創建infra container時,將NetworkMode設置為"Host",并且跳過CNI Manager的配置即可。
對于Pod中其他的容器,不論Pod是處于"Host"網絡模式,還是擁有獨立的Network Namespace,都只需要在調用Container Manager創建容器時,將NetworkMode配置為"Container"模式,加入infra container所在的Network Namespace即可。
6. IO流處理
Kubernetes提供了例如kubectl exec/attach/port-forward這樣的功能來實現用戶和某個具體的Pod或者容器的直接交互。如下所示:

可以看到,exec一個Pod等效于ssh登錄到該容器中。下面,我們根據kubectl exec的執行流來分析Kubernetes中對于IO請求的處理,以及CRI Manager在其中扮演的角色。
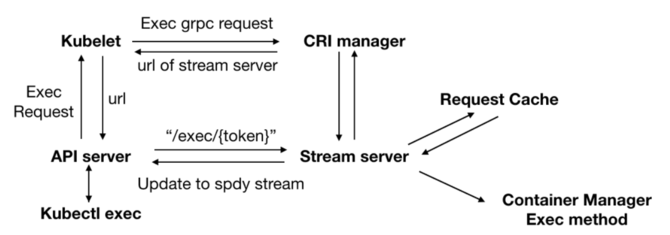
如上圖所示,執行一條kubectl exec命令的步驟如下:
1、kubectl exec命令的本質其實是對Kubernetes集群中某個容器執行exec命令,并將由此產生的IO流轉發到用戶的手中。所以請求將首先層層轉發到達該容器所在節點的Kubelet,Kubelet再根據配置調用CRI中的Exec接口。請求的配置參數如下:
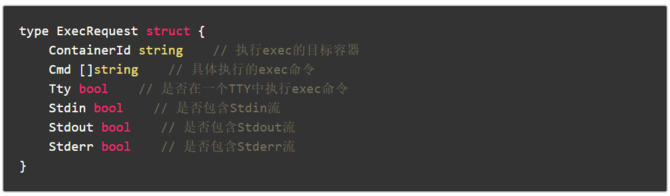
2、令人感到意外的是,CRI Manager的Exec方法并沒有直接調用Container Manager,對目標容器執行exec命令,而是轉而調用了其內置的Stream Server的GetExec方法。
3、Stream Server的GetExec方法所做的工作是將該exec請求的內容保存到了上圖所示的Request Cache中,并返回一個token,利用該token,我們可以重新從Request Cache中找回對應的exec請求。最后,將這個token寫入一個URL中,并作為執行結果層層返回到ApiServer。
4、ApiServer利用返回的URL直接對目標容器所在節點的Stream Server發起一個http請求,請求的頭部包含了"Upgrade"字段,要求將http協議升級為websocket或者SPDY這樣的streaming protocol,用于支持多條IO流的處理,本文我們以SPDY為例。
5、Stream Server對ApiServer發送的請求進行處理,首先根據URL中的token,從Request Cache中獲取之前保存的exec請求配置。之后,回復該http請求,同意將協議升級為SPDY,并根據exec請求的配置等待ApiServer創建指定數量的stream,分別對應標準輸入Stdin,標準輸出Stdout,標準錯誤輸出Stderr。
6、待Stream Server獲取指定數量的Stream之后,依次調用Container Manager的CreateExec和startExec方法,對目標容器執行exec操作并將IO流轉發至對應的各個stream中。
7、最后,ApiServer將各個stream的數據轉發至用戶,開啟用戶與目標容器的IO交互。
事實上,在引入CRI之前,Kubernetes對于IO的處理方式和我們的預期是一致的,Kubelet會直接對目標容器執行exec命令,并將IO流轉發回ApiServer。但是這樣會讓Kubelet承載過大的壓力,所有的IO流都需要經過它的轉發,這顯然是不必要的。因此上述的處理雖然初看較為復雜,但是有效地緩解了Kubelet的壓力,并且也讓IO的處理更為高效。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





