溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何基于 Flink 搭建大規模準實時數據分析平臺?在 Flink Forward Asia 2019 上,來自 Lyft 公司實時數據平臺的徐贏博士和計算數據平臺的高立博士分享了 Lyft 基于 Apache Flink 的大規模準實時數據分析平臺。
查看FFA大會視頻。
本次分享主要分為四個方面:
重要:文末「閱讀原文」可查看 Flink Forward Asia 大會視頻。
Lyft 是位于北美的一個共享交通平臺,和大家所熟知的 Uber 和國內的滴滴類似,Lyft 也為民眾提供共享出行的服務。Lyft 的宗旨是提供世界最好的交通方案來改善人們的生活。
Lyft 的流數據可以大致分為三類,秒級別、分鐘級別和不高于 5 分鐘級別。分鐘級別流數據中,自適應定價系統、欺詐和異常檢測系統是最常用的,此外還有 Lyft 最新研發的機器學習特征工程。不高于 5 分鐘級別的場景則包括準實時數據交互查詢相關的系統。

如下圖所示的是 Lyft 之前的數據分析平臺架構。Lyft 的大部分流數據都是來自于事件,而事件產生的來源主要有兩種,分別是手機 APP 和后端服務,比如乘客、司機、支付以及保險等服務都會產生各種各樣的事件,而這些事件都需要實時響應。
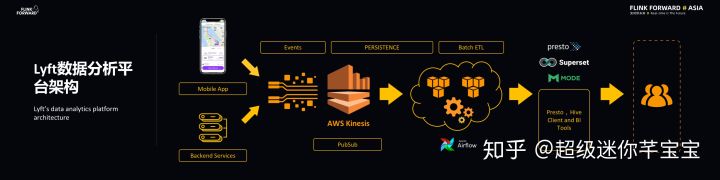
在分析平臺這部分,事件會流向 AWS 的 Kinesis 上面,這里的 Kinesis 與 Apache Kafka 非常類似,是一種 AWS 上專有的 PubSub 服務,而這些數據流都會量化成文件,這些文件則都會存儲在 AWS 的 S3 上面,并且很多批處理任務都會彈出一些數據子集。在分析系統方面,Lyft 使用的是開源社區中比較活躍的 presto 查詢引擎。Lyft 數據分析平臺的用戶主要有四種,即數據工程師、數據分析師以及機器學習專家和深度學習專家,他們往往都是通過分析引擎實現與數據的交互。
Lyft 之所以要基于 Apache Flink 實現大規模準實時數據分析平臺,是因為以往的平臺存在一些問題。比如較高的延遲,導入數據無法滿足準實時查詢的要求;并且基于 Kinesis Client Library 的流式數據導入性能不足;導入數據存在太多小文件導致下游操作性能不足;數據 ETL 大多是高延遲多日多步的架構;此外,以往的平臺對于嵌套數據提供的支持也不足。

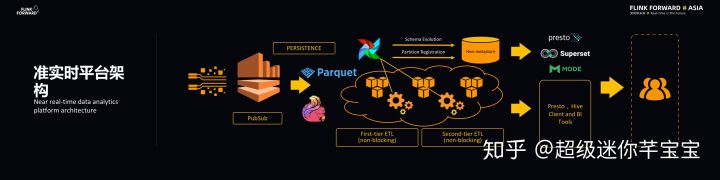
在新的準實時平臺架構中,Lyft 采用 Flink 實現流數據持久化。Lyft 使用云端存儲,而使用 Flink 直接向云端寫一種叫做 Parquet 的數據格式,Parquet 是一種列數據存儲格式,能夠有效地支持交互式數據查詢。Lyft 在 Parquet 原始數據上架構實時數倉,實時數倉的結構被存儲在 Hive 的 Table 里面,Hive Table 的 metadata 存儲在 Hive metastore 里面。
平臺會對于原始數據做多級的非阻塞 ETL 加工,每一級都是非阻塞的(nonblocking),主要是壓縮和去重的操作,從而得到更高質量的數據。平臺主要使用 Apache Airflow 對于 ETL 操作進行調度。所有的 Parquet 格式的原始數據都可以被 presto 查詢,交互式查詢的結果將能夠以 BI 模型的方式顯示給用戶。
Lyft 基于 Apache Flink 實現的大規模準實時數據分析平臺具有幾個特點:

Lyft 準實時數據分析平臺需要每天處理千億級事件,能夠做到數據延遲小于 5 分鐘,而鏈路中使用的組件確保了數據完整性,同時基于 ETL 去冗余操作實現了數據單一性保證。
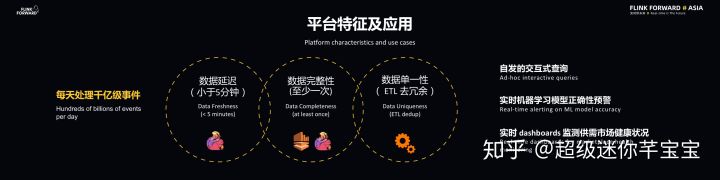
數據科學家和數據工程師在建模時會需要進行自發的交互式查詢,此外,平臺也會提供實時機器學習模型正確性預警,以及實時數據面板來監控供需市場健康狀況。
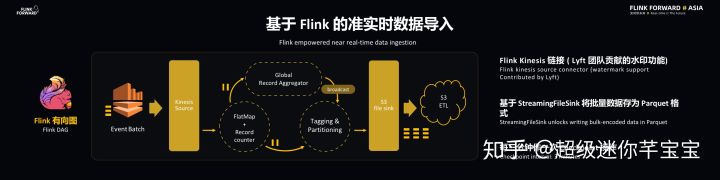
下圖可以看到當事件到達 Kinesis 之后就會被存儲成為 EventBatch。通過 Flink-Kinesis 連接器可以將事件提取出來并送到 FlatMap 和 Record Counter 上面,FlatMap 將事件打撒并送到下游的 Global Record Aggregator 和 Tagging Partitioning 上面,每當做 CheckPoint 時會關閉文件并做一個持久化操作,針對于 StreamingFileSink 的特征,平臺設置了每三分鐘做一次 CheckPoint 操作,這樣可以保證當事件進入 Kinesis 連接器之后在三分鐘之內就能夠持久化。
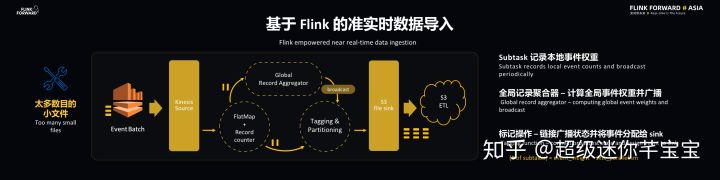
以上的方式會造成太多數量的小文件問題,因為數據鏈路支持成千上萬種文件,因此使用了 Subtasks 記錄本地事件權重,并通過全局記錄聚合器來計算事件全局權重并廣播到下游去。而 Operator 接收到事件權重之后將會將事件分配給 Sink。
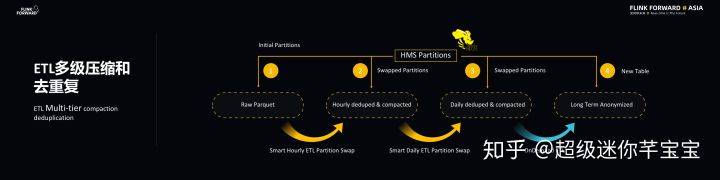
上述的數據鏈路也會做 ETL 多級壓縮和去重工作,主要是 Parquet 原始數據會經過每小時的智能壓縮去重的 ETL 工作,產生更大的 Parquet File。同理,對于小時級別壓縮去重不夠的文件,每天還會再進行一次壓縮去重。對于新產生的數據會有一個原子性的分區交換,也就是說當產生新的數據之后,ETL Job 會讓 Hive metastore 里的表分區指向新的數據和分區。這里的過程使用了啟發性算法來分析哪些事件必須要經過壓縮和去重以及壓縮去重的時間間隔級別。此外,為了滿足隱私和合規的要求,一些 ETL 數據會被保存數以年計的時間。
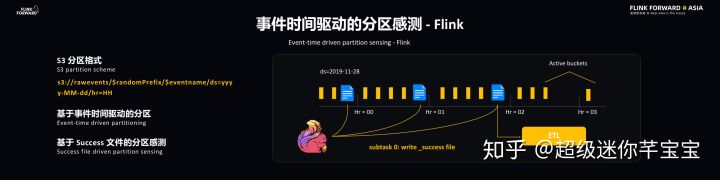
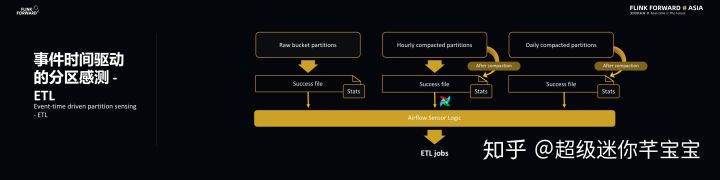
Flink 和 ETL 是通過事件時間驅動的分區感測實現同步的。S3 采用的是比較常見的分區格式,最后的分區是由時間戳決定的,時間戳則是基于 EventTime 的,這樣的好處在于能夠帶來 Flink 和 ETL 共同的時間源,這樣有助于同步操作。此外,基于事件時間能夠使得一些回填操作和主操作實現類似的結果。Flink 處理完每個小時的事件后會向事件分區寫入一個 Success 文件,這代表該小時的事件已經處理完畢,ETL 可以對于該小時的文件進行操作了。
Flink 本身的水印并不能直接用到 Lyft 的應用場景當中,主要是因為當 Flink 處理完時間戳并不意味著它已經被持久化到存儲當中,此時就需要引入分區水印的概念,這樣一來每個 Sink Source 就能夠知道當前寫入的分區,并且維護一個分區 ID,并且通過 Global State Aggregator 聚合每個分區的信息。每個 Subtasks 能夠知道全局的信息,并將水印定義為分區時間戳中最小的一個。
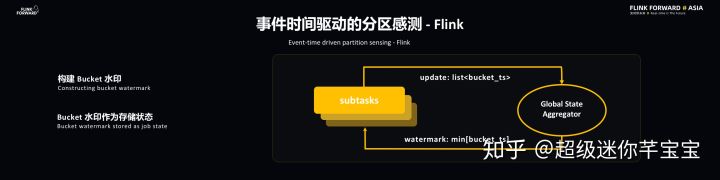
ETL 主要有兩個特點,分別是及時性和去重,而 ETL 的主要功能在于去重和壓縮,最重要的是在非阻塞的情況下就進行去重。前面也提到 Smart ETL,所謂 Smart 就是智能感知,需要兩個相應的信息來引導 Global State Aggregator,分別是分區完整性標識 SuccessFile,在每個分區還有幾個相應的 States 統計信息能夠告訴下游的 ETL 怎樣去重和壓縮以及操作的頻率和范圍。
ETL 除了去重和壓縮的挑戰之外,還經常會遇到 Schema 的演化挑戰。Schema 演化的挑戰分為三個方面,即不同引擎的數據類型、嵌套結構的演變、數據類型演變對去重邏輯的影響。

Lyft 的數據存儲系統其實可以認為是數據湖,對于 S3 而言,Lyft 也有一些性能的優化考量。S3 本身內部也是有分區的,為了使其具有并行的讀寫性能,添加了 S3 的熵數前綴,在分區里面也增加了標記文件,這兩種做法能夠極大地降低 S3 的 IO 性能的影響。標識符對于能否觸發 ETL 操作會產生影響,與此同時也是對于 presto 的集成,能夠讓 presto 決定什么情況下能夠掃描多少個文件。

Lyft 的準實時數據分析平臺在 Parquet 方面做了很多優化,比如文件數據值大小范圍統計信息、文件系統統計信息、基于主鍵數據值的排序加快 presto 的查詢速度以及二級索引的生成。

如下兩個圖所示的是 Lyft 準實時數據分析平臺的基于數據回填的平臺容錯機制。對于 Flink 而言,因為平臺的要求是達到準實時,而 Flink 的 Job 出現失效的時候可能會超過一定的時間,當 Job 重新開始之后就會形成兩個數據流,主數據流總是從最新的數據開始往下執行,附加數據流則可以回溯到之前中斷的位置進行執行直到中斷結束的位置。這樣的好處是既能保證主數據流的準實時特性,同時通過回填數據流保證數據的完整性。

對于 ETL 而言,基于數據回填的平臺容錯機制則表現在 Airflow 的冪等調度系統、原子壓縮和 HMS 交換操作、分區自建自修復體系和 Schema 整合。

利用 Flink 能夠準實時注入 Parquet 數據,使得交互式查詢體驗為可能。同時,Flink 在 Lyft 中的應用很多地方也需要提高,雖然 Flink 在大多數情況的延時都能夠得到保證,但是重啟和部署的時候仍然可能造成分鐘級別的延時,這會對于 SLO 產生一定影響。
此外,Lyft 目前做的一件事情就是改善部署系統使其能夠支持 Kubernetes,并且使得其能夠接近 0 宕機時間的效果。因為 Lyft 準實時數據分析平臺在云端運行,因此在將數據上傳到 S3 的時候會產生一些隨機的網絡情況,造成 Sink Subtasks 的停滯,進而造成整個 Flink Job 的停滯。而通過引入一些 Time Out 機制來檢測 Sink Subtasks 的停滯,使得整個 Flink Job 能夠順利運行下去。
ETL 分區感應能夠降低成本和延遲,成功文件則能夠表示什么時候處理完成。此外,S3 文件布局對性能提升的影響還是非常大的,目前而言引入熵數還屬于經驗總結,后續 Lyft 也會對于這些進行總結分析并且公開。因為使用 Parquet 數據,因此對于 Schema 的兼容性要求就非常高,如果引入了不兼容事件則會使得下游的 ETL 癱瘓,因此 Lyft 已經做到的就是在數據鏈路上游對于 Schema 的兼容性進行檢查,檢測并拒絕用戶提交不兼容的 Schema。

Lyft 對于準實時數據分析平臺也有一些設想。
原文鏈接
本文為阿里云原創內容,未經允許不得轉載。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





