溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關如何進行MapReduce數據序列化讀寫概念的淺析,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
MapReduce為處理簡單數據格式(如日志文件)提供了簡明的文檔支持,但MapReduce已經從日志文件發展到更復雜的數據序列化格式(如文本,XML和JSON)處理,本章的目標是記錄如何使用常見的數據序列化格式,以及檢查更結構化的序列化格式,并比較它們與MapReduce的適用性。下面主要介紹了MapReduce處理以不同格式(如XML和JSON)存儲數據的方法,為更深入了解Avro和Parquet等這類適合大數據和Hadoop的數據格式鋪平了道路。
數據序列化 - 使用文本及其他方法
如果希望使用無處不在的XML和JSON數據序列化格式,這些格式在大多數編程語言中都可直接工作,有多種工具可用于編組、解組和驗證。但是,在MapReduce中使用XML和JSON面臨兩大挑戰。首先,MapReduce需要能夠支持讀寫特定數據序列化格式的類,如果想使用自定義文件格式,那么很可能沒有相應的類支持正在使用的序列化格式;其次,MapReduce的強大之處在于能夠并行讀取輸入數據,如果輸入文件很大(數百兆字節甚至更多),讀取序列化格式的類能夠將較大文件拆分以便多個任務可以并行讀取,這一點至關重要。
XML和JSON格式
MapReduce中的數據序列化支持是讀取和寫入MapReduce數據輸入和輸出類屬性,讓我們首先概述MapReduce如何支持數據輸入和輸出。
3.1 了解MapReduce中的輸入和輸出
你的數據可能位于許多FTP服務器后面的XML文件、中央Web服務器上的文本日志文件或HDFS中的Lucene索引。MapReduce如何跨多種存儲機制讀取和寫入這些不同的序列化結構?
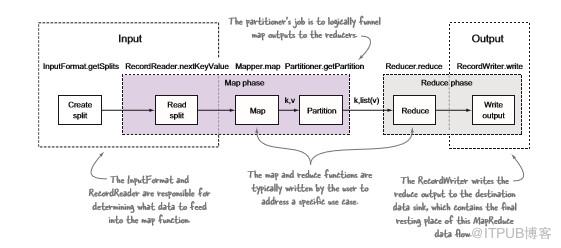
圖3.1 MapReduce中的輸入和輸出actor
圖3.1顯示了通過MapReduce的數據流,并確定了負責流的各部分參與者。在輸入端,我們可以看到某些工作(創建拆分)在map階段以外執行,而其他工作則作為map階段的一部分執行(讀取拆分),所有輸出工作都在reduce階段(寫輸出)執行。
圖3.2 顯示了僅使用map作業的相同流程,在僅map作業中,MapReduce框架仍使用OutputFormat和RecordWriter類將輸出直接寫入數據接收器。讓我們來看看數據流并討論各角色的責任,我們還將查看內置TextInputFormat和TextOutputFormat類中的相關代碼,以更好地理解這些概念,TextInputFormat和TextOutputFormat類讀取和寫入面向行的文本文件。
3.1.1數據輸入支持
MapReduce中數據輸入的兩個類是InputFormat和RecordReader,查詢InputFormat類以確定應如何為map任務分區輸入數據,并且RecordReader執行從輸入讀取數據。
INPUTFORMAT
MapReduce中的每個作業都必須根據InputFormat抽象類中指定的規則定義其輸入。InputFormat實現者必須完成三步:描述map輸入鍵和值類型信息;指定輸入數據應該如何分區;指示應該從源讀取數據的RecordReader實例。
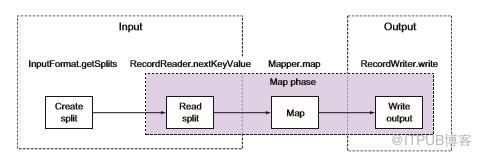
圖3.2沒有Reducer的MapReduce輸入和輸出actor
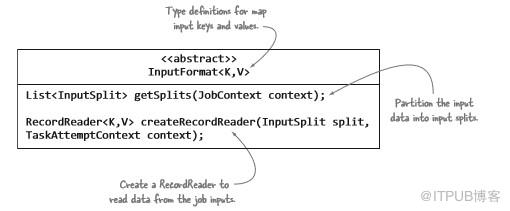
圖3.3帶注釋的InputFormat類及其三個規則
可以說,最重要的規則是確定如何劃分輸入數據。在MapReduce命名法中,這些劃分稱為輸入拆分。輸入拆分直接影響map并行效率,因為每個拆分由單個map任務處理。 使用無法在單個數據源(例如文件)上創建多個輸入拆分的InputFormat將導致map階段進行緩慢,因為將會按順序處理該文件。
TextInputFormat類提供了InputFormat類的createRecordReader方法實現,但它將輸入拆分的計算委托給其父類FileInputFormat。以下代碼顯示了TextInputFormat類的相關部分:

確定輸入拆分的FileInputFormat代碼稍微復雜,以下示例顯示了代碼的簡化形式,以描述getSplits方法的主要元素:

以下代碼顯示了如何指定用于MapReduce作業的InputFormat:
job.setInputFormatClass(TextInputFormat.class);
RECORDREADER
我們將在map任務中創建和使用RecordReader類,以從輸入拆分中讀取數據,并以 key/value形式提供每個記錄供mapper使用。通常為每個輸入拆分創建一個任務,每個任務都有一個RecordReader,負責讀取該輸入拆分的數據。

圖3.4 帶注釋的RecordReader類及其抽象方法
如前所示,TextInputFormat類創建一個LineRecordReader以從輸入拆分中讀取記錄。LineRecordReader直接擴展RecordReader類,并使用LineReader類從輸入拆分中讀取行。LineRecordReader使用文件中的字節偏移量作為map key,并使用行的內容作為map value。 以下示例顯示了LineRecordReader的簡化版本:

因為LineReader類很簡單,所以我們將跳過該代碼。下一步是查看MapReduce如何支持數據輸出。
3.1.2 數據輸出
MapReduce使用與輸入類似的過程來支持輸出數據。必須存在兩個類:OutputFormat和RecordWriter。OutputFormat執行數據接收器屬性的一些基本驗證,RecordWriter將每個reducer輸出寫入數據接收器。
OUTPUTFORMAT
與InputFormat類非常相似,OutputFormat類(如圖3.5所示)定義了實現必須滿足的條件:檢查與作業輸出相關的信息;提供RecordWriter并指定輸出提交者;允許寫入并在任務完成時保持“permanent”。
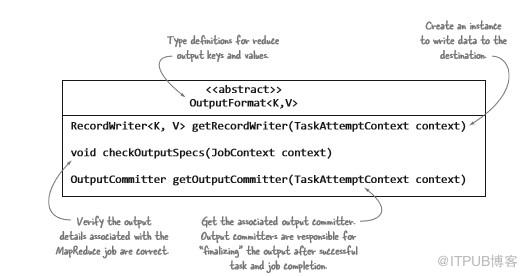
圖3.5 帶注釋的OutputFormat類
就像TextInputFormat一樣,TextOutputFormat還擴展了一個基類FileOutputFormat,負責復雜的數據流操作,例如輸出提交。接下來,我們來看看TextOutputFormat執行工作流程,以下代碼顯示了如何指定用于MapReduce作業的OutputFormat:
job.setOutputFormatClass(TextOutputFormat.class);
RECORDWRITER
我們將使用RecordWriter將reducer輸出寫入目標數據接收器。這是一個簡單的類,如圖3.6所示。

TextOutputFormat返回一個LineRecordWriter對象,它是TextOutputFormat的內部類,用于執行對文件寫入,以下示例顯示了該類的簡化版本:

在map端,InputFormat可確定執行了多少個map任務;在reducer端,任務的數量完全基于客戶端設置的mapred.reduce.tasks值(如果沒有設置, 該值會從mapred-site.xml中獲取,如果站點文件中不存在,則從mapred-default.xml獲取)。
上述就是小編為大家分享的如何進行MapReduce數據序列化讀寫概念的淺析了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





