溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹Java中怎么實現一個TFIDF算法,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
算法介紹
最近要做領域概念的提取,TFIDF作為一個很經典的算法可以作為其中的一步處理。
計算公式比較簡單,如下:

預處理
由于需要處理的候選詞大約后3w+,并且語料文檔數有1w+,直接挨個文本遍歷的話很耗時,每個詞處理時間都要一分鐘以上。
為了縮短時間,首先進行分詞,一個詞輸出為一行方便統計,分詞工具選擇的是HanLp。
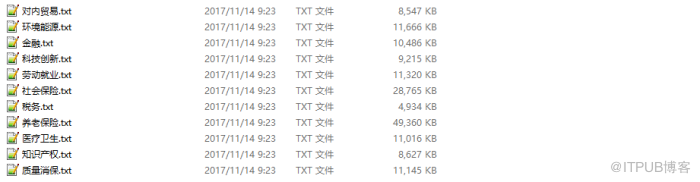
然后,將一個領域的文檔合并到一個文件中,并用“$$$”標識符分割,方便記錄文檔數。

下面是選擇的領域語料(PATH目錄下):
代碼實現
package edu.heu.lawsoutput;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* @ClassName: TfIdf
* @Description: TODO
* @author LJH
* @date 2017年11月12日 下午3:55:15
*/
public class TfIdf {
static final String PATH = "E:\\corpus"; // 語料庫路徑
public static void main(String[] args) throws Exception {
String test = "離退休人員"; // 要計算的候選詞
computeTFIDF(PATH, test);
}
/**
* @param @param path 語料路經
* @param @param word 候選詞
* @param @throws Exception
* @return void
*/
static void computeTFIDF(String path, String word) throws Exception {
File fileDir = new File(path);
File[] files = fileDir.listFiles();
// 每個領域出現候選詞的文檔數
Map<String, Integer> containsKeyMap = new HashMap<>();
// 每個領域的總文檔數
Map<String, Integer> totalDocMap = new HashMap<>();
// TF = 候選詞出現次數/總詞數
Map<String, Double> tfMap = new HashMap<>();
// scan files
for (File f : files) {
// 候選詞詞頻
double termFrequency = 0;
// 文本總詞數
double totalTerm = 0;
// 包含候選詞的文檔數
int containsKeyDoc = 0;
// 詞頻文檔計數
int totalCount = 0;
int fileCount = 0;
// 標記文件中是否出現候選詞
boolean flag = false;
FileReader fr = new FileReader(f);
BufferedReader br = new BufferedReader(fr);
String s = "";
// 計算詞頻和總詞數
while ((s = br.readLine()) != null) {
if (s.equals(word)) {
termFrequency++;
flag = true;
}
// 文件標識符
if (s.equals("$$$")) {
if (flag) {
containsKeyDoc++;
}
fileCount++;
flag = false;
}
totalCount++;
}
// 減去文件標識符的數量得到總詞數
totalTerm += totalCount - fileCount;
br.close();
// key都為領域的名字
containsKeyMap.put(f.getName(), containsKeyDoc);
totalDocMap.put(f.getName(), fileCount);
tfMap.put(f.getName(), (double) termFrequency / totalTerm);
System.out.println("----------" + f.getName() + "----------");
System.out.println("該領域文檔數:" + fileCount);
System.out.println("候選詞出現詞數:" + termFrequency);
System.out.println("總詞數:" + totalTerm);
System.out.println("出現候選詞文檔總數:" + containsKeyDoc);
System.out.println();
}
//計算TF*IDF
for (File f : files) {
// 其他領域包含候選詞文檔數
int otherContainsKeyDoc = 0;
// 其他領域文檔總數
int otherTotalDoc = 0;
double idf = 0;
double tfidf = 0;
System.out.println("~~~~~" + f.getName() + "~~~~~");
Set<Map.Entry<String, Integer>> containsKeyset = containsKeyMap.entrySet();
Set<Map.Entry<String, Integer>> totalDocset = totalDocMap.entrySet();
Set<Map.Entry<String, Double>> tfSet = tfMap.entrySet();
// 計算其他領域包含候選詞文檔數
for (Map.Entry<String, Integer> entry : containsKeyset) {
if (!entry.getKey().equals(f.getName())) {
otherContainsKeyDoc += entry.getValue();
}
}
// 計算其他領域文檔總數
for (Map.Entry<String, Integer> entry : totalDocset) {
if (!entry.getKey().equals(f.getName())) {
otherTotalDoc += entry.getValue();
}
}
// 計算idf
idf = log((float) otherTotalDoc / (otherContainsKeyDoc + 1), 2);
// 計算tf*idf并輸出
for (Map.Entry<String, Double> entry : tfSet) {
if (entry.getKey().equals(f.getName())) {
tfidf = (double) entry.getValue() * idf;
System.out.println("tfidf:" + tfidf);
}
}
}
}
static float log(float value, float base) {
return (float) (Math.log(value) / Math.log(base));
}
}
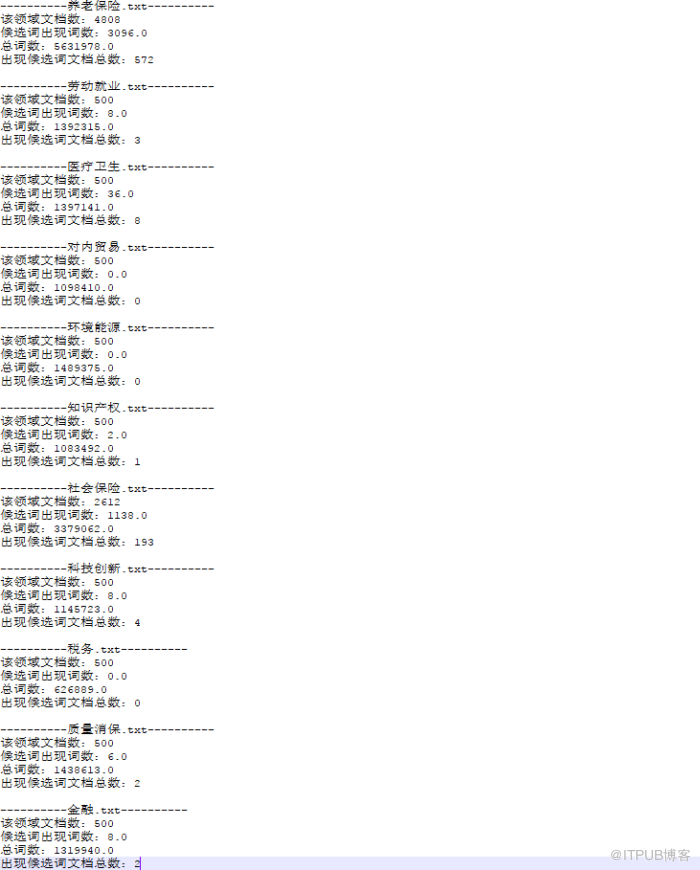
運行結果
測試詞為“離退休人員”,中間結果如下:
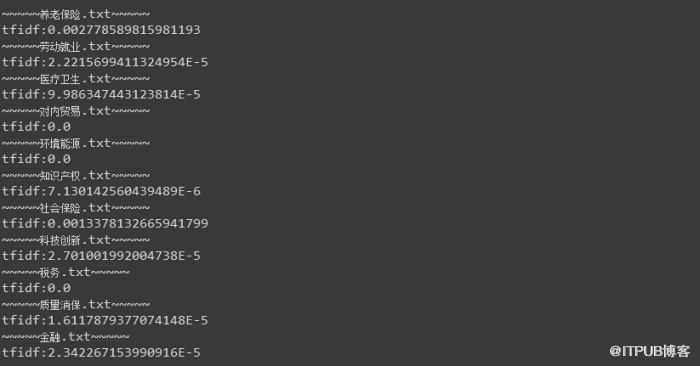
最終結果:
關于Java中怎么實現一個TFIDF算法就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





