溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
怎樣進行Python數據結構分析,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
數據結構是組織數據的方式,以便能夠更好的存儲和獲取數據。數據結構定義數據之間的關系和對這些數據的操作方式。數據結構屏蔽了數據存儲和操作的細節,讓程序員能更好的處理業務邏輯,同時擁有快速的數據存儲和獲取方式。
數據結構是抽象數據類型(ADT)的實現,通常,是通過編程語言提供的基本數據類型為基礎,結合相應的代碼來實現。
通常來說,數據結構分為兩類:原始數據結構和非原始數據結構,原始數據結構是用來表示簡單的數據關系,非原始數據結構包含原始數據結構,同時,數據關系更加復雜,數據操作也更加復雜。
原始數據結構 - 顧名思義 - 是最原始的或基本的數據結構。 它們是數據操作的構建塊,包含純粹,簡單的數據值。 Python有四種原始變量類型:
Integers
Float
Strings
Boolean
您可以使用Integers表示數字數據,具體地說,可以使用從負無窮大到無窮大的整數
“Float”代表“浮點數”。 您可以將它用于有理數,通常以十進制數字結尾,例如1.11或3.14。
請注意,在Python中,您不必顯式聲明變量或數據的類型。 那是因為Python是一種動態類型語言。 動態類型語言是對象可以存儲的數據類型是可變的語言。
String是字母,單詞或其他字符的集合。 在Python中,您可以通過在一對單引號或雙引號中包含一系列字符來創建字符串。 例如:‘cake’,“cookie”等。您還可以對兩個或多個字符串應用+操作來連接它們,就像下面的示例中一樣:
x = 'Cake' y = 'Cookie' x + ' & ' + y #結果:'Cake & Cookie'
以下是您可以使用字符串執行的一些其他基本操作; 例如,您可以使用*重復字符串一定次數:
# Repeat x * 2 #結果:'CakeCake'
您還可以切割字符串
z1 = x[2:] print(z1) z2 = y[0] + y[1] print(z2) # 結果 ke Co
請注意,字符串也可以是字母數字字符,但+操作仍然用于連接字符串。
x = '4' y = '2' x + y '42'
Python有許多內置方法或輔助函數來操作字符串。 替換子字符串,大寫段落中的某些單詞,在另一個字符串中查找字符串的位置是一些常見的字符串操作。 例如:
大寫首字母
str.capitalize('cookie')
'Cookie'以字符為單位檢索字符串的長度。 請注意,空格也計入最終結果:
str1 = "Cake 4 U" str2 = "404" len(str1) 8
檢查字符串是否數字
str1 = "Cake 4 U" str2 = "404" str1.isdigit() False str2.isdigit() True
替換
str1 = "Cake 4 U"
str2 = "404"
str1.replace('4 U', str2)
'Cake 404'查找子字符串
str1 = 'cookie' str2 = 'cook' str1.find(str2) str1 = 'I got you a cookie' str2 = 'cook' str1.find(str2) 12
這種內置數據類型值為:True和False,這通常使它們可以與整數1和0互換。布爾值在條件和比較表達式中很有用,就像在下面的例子中一樣:
x = 4
y = 2
x == y
False
x > y
True
x = 4
y = 2
z = (x==y)
if z:
print("Cookie")
else:
print("No Cookie")
No Cookie有時,你需要整型,但是接口返回給你的是字符串,這時,你就需要數據類型轉換,Python里,可以使用type函數來查看數據類型。
i = 4.0 type(i) float
當你把數據的類型改變時,就稱作數據類型轉換。數據類型轉換分為兩種:隱式轉換和顯示轉換。
數據類型自動轉換,不需要指定,編譯器會為您處理。 看看以下示例:
# float x = 4.0 # integer y = 2 z = x/y type(z) float
在上面的示例中,您不必將x的數據類型顯式更改為float以執行浮點值除法。 編譯器隱式地為你做了這個。
這種類型的數據類型轉換是用戶定義的,這意味著您必須明確地通知編譯器更改某些實體的數據類型。例如:
x = 2 y = "The Godfather: Part " fav_movie = y + x TypeError Traceback (most recent call last) <ipython-input-51-b8fe90df9e0e> in <module>() 1 x = 2 2 y = "The Godfather: Part " ----> 3 fav_movie = y + x TypeError: Can't convert 'int' object to str implicitly
上面的示例,沒有明確的告訴編譯器x,y的數據類型,編譯器認為x為整型,y為字符串,當你試圖連接字符串和整數,編譯器報錯了,這個問題你可以這樣解決:
x = 2 y = "The Godfather: Part " fav_movie = (y) + str(x) print(fav_movie) The Godfather: Part 2
python內置了一些類型轉換函數:int(), float(), 和 str()
非原始數據結構的數據關系更加復雜,主要包括:
Arrays
Lists
Files
首先,Python中的數組是一種收集基本數據類型的緊湊方式,數組中的所有條目必須具有相同的數據類型。 但是,與其他編程語言(如C ++或Java)不同,數組在Python中不常用。
一般來說,當人們在Python中談論數組時,他們實際上是指List。 但是,它們之間存在根本區別。 對于Python,數組可以被視為存儲某種數據列表的更有效方式。 但是,列表里的元素具有相同數據類型。
在Python中,數組由array模塊支持,在使用前需要導入并初始化。 存儲在數組中的元素受其數據類型的約束。 數組類型在數組創建期間指定,并使用類型代碼指定,類型代碼是單個字符,如下例中所示:
import array as arr
a = arr.array("I",[3,6,9])
type(a)
array.arrayPython中的列表用于存儲同類項的集合。 這些是可變的,這意味著您可以在不改變其身份的情況下更改其內容。 您可以通過方括號[和]來識別列表,其中包含以逗號分隔的元素。 列表內置于Python中:您無需單獨調用它們。
x = [] type(x) list x1 = [1,2,3] type(x1) list x2 = list([1,'apple',3]) type(x2) list print(x2[1]) apple x2[1] = 'orange' print(x2) [1, 'orange', 3]
注意:就像您在上面的示例中看到的x1一樣,列表也可以保存異構項,從而滿足數組的存儲功能。 除非您想對此集合應用某些特定操作。
Python提供了許多操作和處理列表的方法。 將新項添加到列表,從列表中刪除一些項,排序或反轉列表是常見的列表操作。 例如:
使用append()將11添加到list_num列表中。 默認情況下,此數字將添加到列表的末尾。
list_num = [1,2,45,6,7,2,90,23,435] list_char = ['c','o','o','k','i','e'] list_num.append(11) print(list_num) [1, 2, 45, 6, 7, 2, 90, 23, 435, 11]
插入數據
list_num.insert(0, 11) print(list_num) [11, 1, 2, 45, 6, 7, 2, 90, 23, 435, 11]
刪除元素
list_char.remove('o')
print(list_char)
['c', 'o', 'k', 'i', 'e']根據索引刪除元素
list_char.pop(-2) # Removes the item at the specified position print(list_char) ['c', 'o', 'k', 'e'] list_num.sort() print(list_num) [1, 2, 2, 6, 7, 11, 11, 23, 45, 90, 435] list.reverse(list_num) print(list_num) [435, 90, 45, 23, 11, 11, 7, 6, 2, 2, 1]
你可能想,既然List那么方便,為什么還要Array,這是因為由于Array存儲的數據類型一致,可以通過簡單的函數完成一些特殊的操作。例如
array_char = array.array("u",["c","a","t","s"])
array_char.tostring()
print(array_char)
array('u', 'cats')您可以應用array_char的tostring()函數,因為Python知道數組中的所有項都具有相同的數據類型,因此操作在每個元素上的行為方式相同。 因此,在處理大量同類數據類型時,數組非常有用。 因為Python不必單獨記住每個元素的數據類型細節; 對于某些用途,與列表相比,數組可能更快并且使用更少的內存。
在我們討論數組的主題時,還值得提一下NumPy數組。 NumPy數組在數據科學領域中被廣泛用于處理多維數組。 它們通常比數組模塊和Python列表更有效。 在NumPy數組中讀取和寫入元素更快,并且它們支持“矢量化”操作,例如元素添加。 此外,NumPy數組可以有效地處理大型稀疏數據集。例如:
import numpy as np arr_a = np.array([3, 6, 9]) arr_b = arr_a/3 # Performing vectorized (element-wise) operations print(arr_b) [ 1. 2. 3.] arr_ones = np.ones(4) print(arr_ones) [ 1. 1. 1. 1.] multi_arr_ones = np.ones((3,4)) print(multi_arr_ones) [[ 1. 1. 1. 1.] [ 1. 1. 1. 1.] [ 1. 1. 1. 1.]]
通常,列表數據結構可以進一步分類為線性和非線性數據結構。 堆棧和隊列稱為線性數據結構,而圖形和樹是非線性數據結構。 這些結構及其概念可能相對復雜,但由于它們與現實世界模型的相似性而被廣泛使用。
注意:在線性數據結構中,數據項按順序組織。 數據項一個接一個地遍歷,并且可以在單次運行期間遍歷線性數據結構中的所有數據項。 但是,在非線性數據結構中,數據項不是按順序組織的。 這意味著元素可以連接到多個元素,以反映這些項目之間的特殊關系。 在單次運行期間,可能無法遍歷非線性數據結構中的所有數據項。
堆棧是根據Last-In-First-Out(LIFO)概念插入和移除的對象的容器。 想象一下這樣一種場景,即在一個有一堆盤子的晚宴上,總是在堆頂部添加或移除盤子。 在計算機科學中,這個概念用于評估表達式和語法分析,調度算法/例程等。
可以使用Python中的列表來實現堆棧。 將元素添加到堆棧時,它被稱為推送操作,而當您刪除或刪除元素時,它被稱為彈出操作。 請注意,當您在Python中使用堆棧時,實際上有一個pop()方法可供使用:
# Bottom -> 1 -> 2 -> 3 -> 4 -> 5 (Top) stack = [1,2,3,4,5] stack.append(6) # Bottom -> 1 -> 2 -> 3 -> 4 -> 5 -> 6 (Top) print(stack) [1, 2, 3, 4, 5, 6] stack.pop() # Bottom -> 1 -> 2 -> 3 -> 4 -> 5 (Top) stack.pop() # Bottom -> 1 -> 2 -> 3 -> 4 (Top) print(stack) [1, 2, 3, 4]
隊列是根據先進先出(FIFO)原則插入和移除的對象的容器。 在現實世界中排隊的一個很好的例子是售票柜臺的線路,根據他們的到達順序上車,因此首先到達的人也是第一個離開的人。
隊列可以有許多不同的類型,但在本教程中僅討論最基本的類型。 列表實現隊列效率不高,因為列表末尾的append()和pop()速度很快, 但是,最后插入和從列表開頭刪除不是那么快,因為它需要元素位置的移動。
數學和計算機科學中的圖是由節點組成的網絡,節點也稱為頂點,它們可以相互連接,也可以不相互連接。 連接兩個節點的線或路徑稱為邊。 如果邊緣具有特定的流動方向,那么它是有向圖,方向邊緣被稱為弧。 否則,如果未指定方向,則該圖形稱為無向圖。
這可能聽起來非常理論化,當你深入挖掘時會變得相當復雜。 然而,圖形是數據科學中特別重要的概念,通常用于模擬現實生活中的問題。 社會網絡,化學和生物學的分子研究,地圖,推薦系統都依賴于圖形和圖形理論原理。這有個Python實現圖的例子:
graph = { "a" : ["c", "d"],
"b" : ["d", "e"],
"c" : ["a", "e"],
"d" : ["a", "b"],
"e" : ["b", "c"]
}
def define_edges(graph):
edges = []
for vertices in graph:
for neighbour in graph[vertices]:
edges.append((vertices, neighbour))
return edges
print(define_edges(graph))
[('a', 'c'), ('a', 'd'), ('b', 'd'), ('b', 'e'), ('c', 'a'), ('c', 'e'), ('e', 'b'), ('e', 'c'), ('d', 'a'), ('d', 'b')]您可以使用Graph做一些很酷的事情,例如嘗試找到兩個節點之間存在路徑,或者找到兩個節點之間的最短路徑,確定圖形中的周期。
事實上,著名的“旅行商問題”是找到一個最短路徑,它只訪問每個節點一次并返回起點。 有時圖形的節點或弧已經分配了權重或成本,您可以將其視為指定行走難度級別,并且您有興趣找到最便宜或最簡單的路徑。
現實世界中的一棵樹是一種生物,它的根在地上,樹枝上有葉子、果實。樹的分支以一種有組織的方式展開。在計算機科學中,樹被用來描述數據如何被組織,除了根在頂部并且樹枝,樹葉跟隨,向底部蔓延并且樹被繪制為與真實樹相比被倒置。
為了引入更多的符號,根始終位于樹的頂部。后面的其他節點稱為分支,每個分支中的最終節點稱為葉。您可以將每個分支想象成一個較小的樹本身。根通常稱為父節點,它在其下面引用的節點稱為子節點。具有相同父節點的節點稱為兄弟節點。
樹有助于定義現實世界場景,并且從游戲世界到設計XML解析器,以及PDF設計原則都基于樹。在數據科學中,“基于決策樹的學習”實際上構成了一個大范圍的研究。存在許多著名的方法,如裝袋,提升使用樹模型來生成預測模型。像國際象棋這樣的游戲構建了一棵巨大的樹,其中包含所有可能的動作來分析和應用啟發式方法來決定最佳操作。
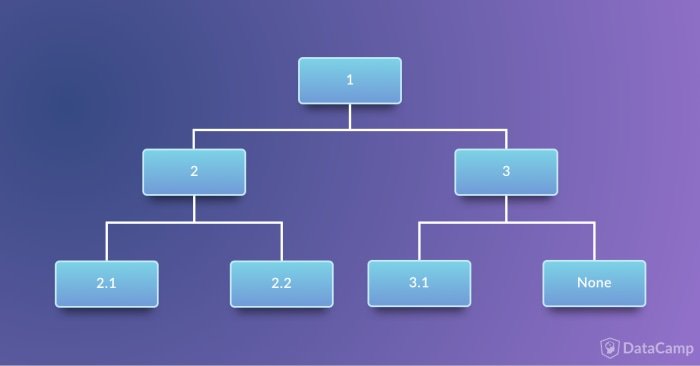
class Tree: def __init__(self, info, left=None, right=None): self.info = info self.left = left self.right = right def __str__(self): return (str(self.info) + ', Left child: ' + str(self.left) + ', Right child: ' + str(self.right)) tree = Tree(1, Tree(2, 2.1, 2.2), Tree(3, 3.1)) print(tree) 1, Left child: 2, Left child: 2.1, Right child: 2.2, Right child: 3, Left child: 3.1, Right child: None
元組是另一種標準序列數據類型。 元組和列表之間的區別在于元組是不可變的,這意味著一旦定義,您就無法刪除,添加或編輯其中的任何值。 這可能在您可能將控件傳遞給其他人但您不希望它們操縱集合中的數據但可能只是在數據副本中看到它們或單獨執行操作的情況下有用。例如
x_tuple = 1,2,3,4,5
y_tuple = ('c','a','k','e')
x_tuple[0]
1
y_tuple[3]
x_tuple[0] = 0 # Cannot change values inside a tuple
---------------------------------------------------------------------------
TypeError
Traceback (most recent call last)
<ipython-input-74-b5d6da8c1297> in <module>()
1 y_tuple[3]
----> 2 x_tuple[0] = 0 # Cannot change values inside a tuple
TypeError: 'tuple' object does not support item assignment如果你想實現類似于電話簿的東西,字典是要使用的數據結構。 您之前看到的所有數據結構都不適用于電話簿。
這是一本字典可以派上用場的時候。 字典由鍵值對組成。
x_dict = {'Edward':1, 'Jorge':2, 'Prem':3, 'Elisa':4}
del x_dict['Elisa']
x_dict
{'Edward': 1, 'Jorge': 2, 'Prem': 3}
x_dict['Edward'] # Prints the value stored with the key 'Kevin'.
1您可以在詞典上應用許多其他內置功能:
len(x_dict) 3 x_dict.keys() dict_keys(['Prem', 'Edward', 'Jorge']) x_dict.values() dict_values([3, 1, 2])
集合是唯一對象的集合。 這些對于創建僅在數據集中包含唯一值的列表很有用。 它是一個無序的集合,但是一個可變的集合。
x_set = set('CAKE&COKE')
y_set = set('COOKIE')
print(x_set)
{'A', '&', 'O', 'E', 'C', 'K'}
print(y_set) # Single unique 'o'
{'I', 'O', 'E', 'C', 'K'}
print(x - y) # All the elements in x_set but not in y_set
NameError Traceback (most recent call last)
<ipython-input-3-31abf5d98454> in <module>()
----> 1 print(x - y) # All the elements in x_set but not in y_set
NameError: name 'x' is not defined
print(x_set|y_set) # Unique elements in x_set or y_set or both
{'C', '&', 'E', 'A', 'O', 'K', 'I'}
print(x_set & y_set) # Elements in both x_set and y_set
{'O', 'E', 'K', 'C'}文件傳統上是數據結構的一部分。 雖然大數據在數據科學行業中很常見,但是沒有存儲和檢索先前存儲的信息的能力的編程語言幾乎沒有用。在Python中讀取和寫入文件的語法與其他編程語言類似,但更容易處理。 以下是一些可幫助您使用Python處理文件的基本功能:
open()打開系統中的文件,文件名是要打開的文件的名稱;
read()讀取整個文件;
readline()一次讀取一行;
write()將字符串寫入文件,并返回寫入的字符數; 和
close()關閉文件。
# File modes (2nd argument): 'r'(read), 'w'(write), 'a'(appending), 'r+'(both reading and writing)
f = open('file_name', 'w')
# Reads entire file
f.read()
# Reads one line at a time
f.readline()
# Writes the string to the file, returning the number of char written
f.write('Add this line.')
f.close()open()函數中的第二個參數是打開文件模式。 它允許您指定是要讀取(r),寫入(w),追加(a)還是讀取和寫入(r +)。
到此,好學的你對Python的數據結構已經有了一個基本的了解了。看完了歸看完了,需要勤勞的你動手操練起來呀!
關于怎樣進行Python數據結構分析問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





