溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了怎么用Python來理清楚紅樓夢里的關系,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
最近把紅樓夢又抽空看了一遍,古典中的經典,我真無法用言辭贊美她。今天,想跟大家一起用 Python 來理一理紅樓夢中的的那些關系
不要問我為啥是紅樓夢,而不是水滸三國或西游,都是經典,但我個人還是更喜歡偏古典的書,紅樓夢也是我多次反復品讀的為數不多的小說,對它的感情也是最深的。
好了好了這些都不重要,重要的是我們今天要用Python來理紅樓夢的關系!
紅樓夢 TXT 文件一份
金陵十二釵 + 賈寶玉 人物名稱列表
人物列表內容如下:
寶玉 nr
黛玉 nr
寶釵 nr
湘云 nr
鳳姐 nr
李紈 nr
元春 nr
迎春 nr
探春 nr
惜春 nr
妙玉 nr
巧姐 nr
秦氏 nr
這份列表,同時也是為了做分詞時使用,后面的 nr 就是人名的意思。
讀取數據并加載詞典
with open("紅樓夢.txt", encoding='gb18030') as f:
honglou = f.readlines()
jieba.load_userdict("renwu_forcut")
renwu_data = pd.read_csv("renwu_forcut", header=-1)
mylist = [k[0].split(" ")[0] for k in renwu_data.values.tolist()]這樣,我們就把紅樓夢讀取到了 honglou 這個變量當中,同時也通過 load_userdict 將我們自定義的詞典加載到了 jieba 庫中。
對文本進行分詞處理并提取
tmpNames = []
names = {}
relationships = {}
for h in honglou:
h.replace("賈妃", "元春")
h.replace("李宮裁", "李紈")
poss = pseg.cut(h)
tmpNames.append([])
for w in poss:
if w.flag != 'nr' or len(w.word) != 2 or w.word not in mylist:
continue
tmpNames[-1].append(w.word)
if names.get(w.word) is None:
names[w.word] = 0
relationships[w.word] = {}
names[w.word] += 1首先,因為文中"賈妃", “元春”,“李宮裁”, “李紈” 混用嚴重,所以這里直接做替換處理。
然后使用 jieba 庫提供的 pseg 工具來做分詞處理,會返回每個分詞的詞性。
之后做判斷,只有符合要求且在我們提供的字典列表里的分詞,才會保留。
一個人每出現一次,就會增加一,方便后面畫關系圖時,人物 node 大小的確定。
對于存在于我們自定義詞典的人名,保存到一個臨時變量當中 tmpNames。
處理人物關系
for name in tmpNames: for name1 in name: for name2 in name: if name1 == name2: continue if relationships[name1].get(name2) is None: relationships[name1][name2] = 1 else: relationships[name1][name2] += 1
對于出現在同一個段落中的人物,我們認為他們是關系緊密的,每同時出現一次,關系增加1.
保存到文件
with open("relationship.csv", "w", encoding='utf-8') as f:
f.write("Source,Target,Weight\n")
for name, edges in relationships.items():
for v, w in edges.items():
f.write(name + "," + v + "," + str(w) + "\n")
with open("NameNode.csv", "w", encoding='utf-8') as f:
f.write("ID,Label,Weight\n")
for name, times in names.items():
f.write(name + "," + name + "," + str(times) + "\n")文件1:人物關系表,包含首先出現的人物、之后出現的人物和一同出現次數
文件2:人物比重表,包含該人物總體出現次數,出現次數越多,認為所占比重越大。
使用 pyecharts 作圖
def deal_graph():
relationship_data = pd.read_csv('relationship.csv')
namenode_data = pd.read_csv('NameNode.csv')
relationship_data_list = relationship_data.values.tolist()
namenode_data_list = namenode_data.values.tolist()
nodes = []
for node in namenode_data_list:
if node[0] == "寶玉":
node[2] = node[2]/3
nodes.append({"name": node[0], "symbolSize": node[2]/30})
links = []
for link in relationship_data_list:
links.append({"source": link[0], "target": link[1], "value": link[2]})
g = (
Graph()
.add("", nodes, links, repulsion=8000)
.set_global_opts(title_opts=opts.TitleOpts(title="紅樓人物關系"))
)
return g首先把兩個文件讀取成列表形式
對于“寶玉”,由于其占比過大,如果統一進行縮放,會導致其他人物的 node 過小,展示不美觀,所以這里先做了一次縮放
最后得出的關系圖
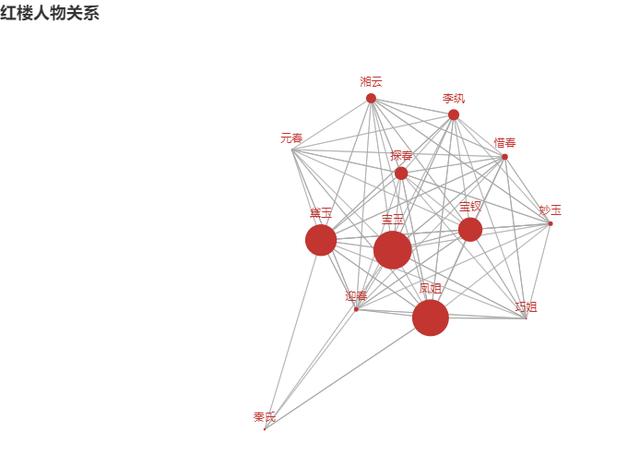
上述內容就是怎么用Python來理清楚紅樓夢里的關系,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





