溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
數據缺失是數據科學家在處理數據時經常遇到的問題,本文作者基于不同的情境提供了相應的數據插補解決辦法。沒有完美的數據插補法,但總有一款更適合當下情況。
我在數據清理與探索性分析中遇到的最常見問題之一就是處理缺失數據。首先我們需要明白的是,沒有任何方法能夠完美解決這個問題。不同問題有不同的數據插補方法
——時間序列分析,機器學習,回歸模型等等,很難提供通用解決方案。在這篇文章中,我將試著總結最常用的方法,并尋找一個結構化的解決方法。
插補數據
vs
刪除數據
在討論數據插補方法之前,我們必須了解數據丟失的原因。
1
、
隨機丟失(
MAR
,
Missing at Random
):隨機丟失意味著數據丟失的概率與丟失的數據本身無關,而僅與部分已觀測到的數據有關。
2
、
完全隨機丟失(
MCAR
,
Missing Completely at Random
):數據丟失的概率與其假設值以及其他變量值都完全無關。
3
、
非隨機丟失(
MNAR
,
Missing not at Random
):有兩種可能的情況。缺失值取決于其假設值(例如,高收入人群通常不希望在調查中透露他們的收入);或者,缺失值取決于其他變量值(假設女性通常不想透露她們的年齡,則這里年齡變量缺失值受性別變量的影響)。
在前兩種情況下可以根據其出現情況刪除缺失值的數據,而在第三種情況下,刪除包含缺失值的數據可能會導致模型出現偏差。因此我們需要對刪除數據非常謹慎。請注意,插補數據并不一定能提供更好的結果。
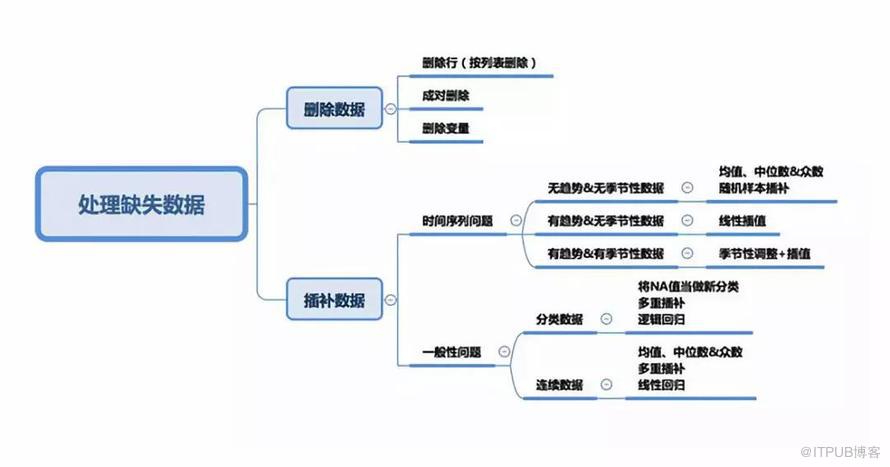
刪除
列表刪除
按列表刪除(完整案例分析)會刪除一行觀測值,只要其包含至少一個缺失數據。你可能只需要直接刪除這些觀測值,分析就會很好做,尤其是當缺失數據只占總數據很小一部分的時候。然而在大多數情況下,這種刪除方法并不好用。因為完全隨機缺失( MCAR )的假設通常很難被滿足。因此本刪除方法會造成有偏差的參數與估計。

成對刪除
在重要變量存在的情況下,成對刪除只會刪除相對不重要的變量行。這樣可以盡可能保證充足的數據。該方法的優勢在于它能夠幫助增強分析效果,但是它也有許多不足。它假設缺失數據服從完全隨機丟失( MCAR )。如果你使用此方法,最終模型的不同部分就會得到不同數量的觀測值,從而使得模型解釋非常困難。
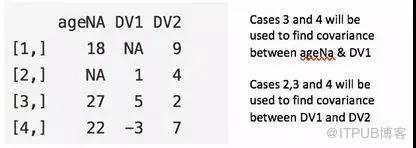
觀測行 3 與 4 將被用于計算 ageNa 與 DV1 的協方差;觀測行 2 、 3 與 4 將被用于計算 DV1 與 DV2 的協方差。
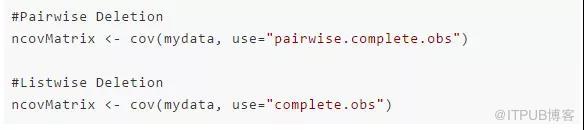
刪除變量
在我看來,保留數據總是比拋棄數據更好。有時,如果超過 60 %的觀測數據缺失,直接刪除該變量也可以,但前提是該變量無關緊要。話雖如此,插補數據總是比直接丟棄變量好一些。

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





