溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“HanLP關鍵詞提取算法的示例分析”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“HanLP關鍵詞提取算法的示例分析”這篇文章吧。
In this paper, we introduce the TextRank graphbased ranking model for graphs extracted from natural language texts
TextRank是一個非監督學習算法,它將文本中構造成一個圖,將文本中感興趣的東西(比如分詞)當成一個個頂點,然后應用TextRank算法來抽取文本中的一些信息。
Such keywords may constitute useful entries for building an automatic index for a document collection, can be used to classify a text, or may serve as a concise summary for a given document.
提取出來的關鍵詞,可用來作為文本分類,或者概括文本的中心思想。
TextRank通過不斷地迭代來提取關鍵詞,每一輪迭代,算法給圖中的頂點打分。直到滿足某個條件(比如說迭代次數克到200次,或者設置的某個參數達到一個閾值)為止。
For loosely connected graphs, with the number of edges proportional with the number of vertices, undirected graphs tend to have more gradual convergence curves.
對于稀疏圖而言,邊的數目與頂點的數目成線性關系,對這樣的圖進行關鍵詞提取,有著更平緩的收斂曲線(或者叫收斂得慢吧)
It may be therefore useful to indicate and incorporate into the model the “strength”
of the connection between two vertices $V_i$ and $V_j$ as a weight $w_{ij}$ added to the corresponding edge that connects the two vertices.有時,圖中頂點之間的關系并不完全平等,比如某些頂點之間關系密切,這里可用邊的權重來衡量頂點之間的相關性重要程度,而這就是帶權圖模型。
給定若干個句子,提取關鍵詞。而TextRank算法是 graphbased ranking model,因此需要構造一個圖,要想構造圖,就需要確定圖中的頂點如何構造,于是就把句子進行分詞,將分得的每個詞作為圖中的頂點。
在選取某個詞作為圖的頂點的時候,可以應用一些過濾規則:比如說,去除掉分詞結果中的停用詞、根據詞性來添加頂點(比如只將名詞和動詞作為圖的頂點)……
The vertices added to the graph can be restricted with syntactic filters, which select only lexical units of a certain part of speech. One can for instance consider only nouns and verbs for addition to the graph, and consequently draw potential edges based only on relations that can be established between nouns and verbs.
在確定好哪些詞作為圖的頂點之后,另一個是確定詞與詞之間的關系,也即:圖中的哪些頂點有邊?比如說設置一個窗口大小,落在這個窗口內的詞,都添加一條邊。
it is the application that dictates the type of relations that are used to draw connections between any two such vertices,
確定了邊的關系后,接下來是確定邊上權值。這個也是根據實際情況而定。
前面提到,若干句話分詞之后,得到的一個個的詞,或者叫Term。假設窗口大小為5。解釋一下 TextRank算法提取關鍵詞的Java實現 文章中提到的如何確定某個Term有哪些鄰接Term。
比如說:‘程序員‘ 這個Term,它在多個句子中出現了,因此分詞結果‘程序員‘ 出現在四個地方:
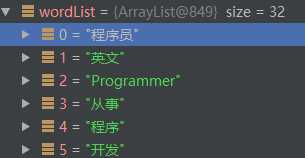
索引0處:‘程序員‘的鄰接點有:
英文、programmer、從事、程序
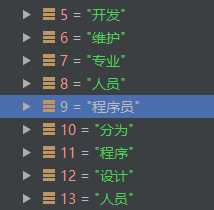
索引9處:‘程序員‘的鄰接點有:
開發、維護、專業、人員、分為、程序、設計、人員
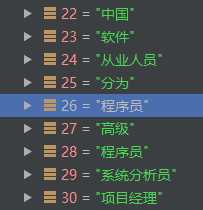
索引26處,‘程序員‘的鄰接點有:
中國、軟件、從業人員、分為、高級、程序員、系統分析員、項目經理
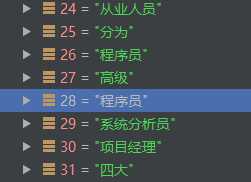
索引28處,‘程序員‘的鄰接點有:
從業人員、分為、程序員、高級、系統分析員、項目經理、四大
結合這四處窗口中的所有的詞,得到‘程序員‘的鄰接點如下:
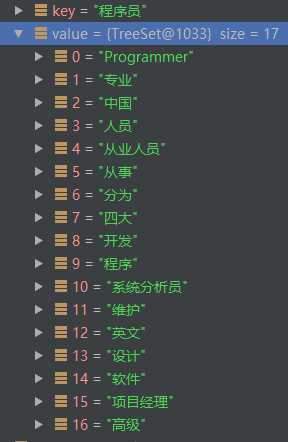
因此,當窗口大小設置為5時,Term的前后四個Term都將視為它的鄰接點,并且當這個Term出現多次時,則是將它各次出現位置處的前后4個Term合并,最終作為這個Term的鄰接點。
從這里可看出:如果某個Term在句子中出現了多次,意味著該Term會比較重要。因為它的鄰接點會比較多,也即有很多其他Term給它投了票。這就有點類似于Term Frequency來衡量Term的重要性。
m.put(key, m.get(key) + d / size * (score.get(element) == null ? 0 : score.get(element)));代碼的解讀:
m.get(key)如果是第一次進入for (String element : value),則是拿到公式前半部分1-d的結果;如果是已經在for (String element : value)進行了迭代,for循環相當于求和:\(\Sigma_{v_j\in In(v_i)}\)
for (String element : value) { int size = words.get(element).size();
m.put(key, m.get(key) + d / size * (score.get(element) == null ? 0 : score.get(element)));
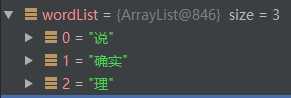
}以”他說的確實在理“ 舉例來說:,選取窗口大小為5,經過分詞并去除停用詞后:
構造的無向圖如下:(每條邊的權值都為1)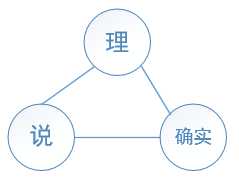
以頂點‘理‘為例,來看一下‘理‘的得分是如何被更新的。在for (String element : value)一共有兩個頂點對 ‘理‘進行投票,首先是 ‘確實‘頂點,與‘確實‘頂點鄰接的頂點有兩個,因此:int size = words.get(element).size();中size=2。接下來,來分解一下這行代碼:
m.put(key, m.get(key) + d / size * (score.get(element) == null ? 0 : score.get(element)))
m.get(key)為1-d,因為在外層for循環中,m.put(key, 1 - d)已經公式的前半分部(1-d)存儲了。
score.get(element) == null ? 0 : score.get(element)這個是獲取上一輪迭代的結果。對于初始第一輪迭代而言,score.get(element)為0.8807971,這個值是每個頂點的得分初始值:
//依據TF來設置初值, words 代表的是 一張 無向圖
for (Map.Entry<String, Set<String>> entry : words.entrySet()) {
score.put(entry.getKey(), sigMoid(entry.getValue().size()));//無向圖的每個頂點 得分值 初始化
}score.get(element)相當于公式中的\(WS(V_j)\)
最后來分析一個 size,size是由代碼int size = words.get(element).size()獲得的,由于每條邊權值為1,size其實相當于:\(\Sigma_{V_k\in Out(V_j)}w_{jk}\)。
In(‘理‘)={‘確實‘,‘說‘}
當\(V_j\)為‘確實‘時,\(Out(V_j)\)為{‘說‘,‘理‘},因此:\(\Sigma_{V_k\in Out(V_j)}w_{jk}=2\)。于是,更新頂點‘理‘的得分:\(1-d+d*(1/2)*0.8807971=0.5243387\)。然后再通過m.put將臨時結果保存起來。
接下來,for (String element : value)繼續,此時:\(V_j\)為頂點‘說‘,由于頂點‘說‘也有兩條鄰接邊,因此有:\(\Sigma_{V_k\in Out(V_j)}w_{jk}=2\)。于是更新頂點‘理‘的得分:\(0.5243387+d*(1/2)*0.8807971=0.89867747\)。而這就是第一輪迭代時,頂點‘理‘的得分。
根據上面的1、2中的步驟,for (String element : value)就相當于:\(\Sigma_{V_j\in In(V_i)}\),因為每次都把計算好的結果再put回HashMap m中。
因此,在第一輪迭代中,頂點‘理‘的得分就是:0.89867747
類似于,經過:max_iter次迭代,或者達到閾值:
if (max_diff <= min_diff) break;
時,就不再迭代了。
下面再來對代碼作個總體說明:
這里是構造無向圖的過程
for (String w : wordList) { if (!words.containsKey(w)) { //排除了 wordList 中的重復term, 對每個已去重的term, 用 TreeSet<String> 保存該term的鄰接頂點
words.put(w, new TreeSet<String>());
} // 復雜度O(n-1)
if (que.size() >= 5) { //窗口的大小為5,是寫死的. 對于一個term_A而言, 它的前4個term、后4個term 都屬于term_A的鄰接點
que.poll();
} for (String qWord : que) { if (w.equals(qWord)) { continue;
} //既然是鄰居,那么關系是相互的,遍歷一遍即可
words.get(w).add(qWord);
words.get(qWord).add(w);
}
que.offer(w);
}這里是對圖中每個頂點賦值一個初始score過程:
Map<String, Float> score = new HashMap<String, Float>();//保存最終每個關鍵詞的得分
//依據TF來設置初值, words 代表的是 一張 無向圖
for (Map.Entry<String, Set<String>> entry : words.entrySet()) {
score.put(entry.getKey(), sigMoid(entry.getValue().size()));//無向圖的每個頂點 得分值 初始化
}接下來,三個for循環:第一個for循環代表迭代次數;第二個for循環代表:對無向圖中每一個頂點計算得分;第三個for循環代表:對某個具體的頂點而言,計算它的每個鄰接點給它的投票權重。
for (int i = 0; i < max_iter; ++i) { //....
for (Map.Entry<String, Set<String>> entry : words.entrySet()) { //...
for (String element : value) {這樣,就實現了論文中公式:
\[WS(v_i)=(1-d)+d*\Sigma_{V_j\in In(V_i)}\frac{w_{ji}}{\Sigma_{V_k\in Out(V_j)}w_{jk}}*WS(V_j)\]
而最終提取出來的關鍵詞是:
[理, 確實, 說]
上面只是用 ”他說的確實在理“ 這句話 演示了TextRank算法的具體細節,在實際應用中可能 不合理 。因為會存在:
現有統計信息不足以讓TextRank支持 某個詞 的重要性,算法有局限性。
可見:TextRank提取關鍵詞是受到分詞結果的影響的;其次,也受窗口大小的影響。
以上是“HanLP關鍵詞提取算法的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





