溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

HAWQ, 取自Hadoop With Query,這是一款原生Hadoop并行SQL引擎。同時作為一款面向企業的分析型數據庫HAWQ有很多優良的特性,例如它完整兼容ANSI-SQL標準語法,支持標準JDBC/ODBC連接,支持ACID事務特性,高性能,擁有比傳統MPP數據庫更先進的彈性執行引擎,可以秒級動態加減節點,擁有各種容錯機制,支持多級資源和負載管理,提供Hadoop上PB級數據高性能交互式查詢能力,并且提供對主要BI工具的描述性分析支持,以及支持預測型分析的機器學習庫。目前HAWQ屬于Apache的孵化項目,即將成為Apache頂級項目。而由HAWQ創始團隊成立的偶數科技推出的HAWQ++則是基于Apache HAWQ的增強企業版。
HAWQ++體系架構
HAWQ++是典型的主從架構。其中有幾個Master節點:HAWQ++ master節點,HDFS master節點NameNode,YARN master節點ResourceManager。現階段HAWQ++元數據服務還集成在HAWQ++ master節點里面,未來會獨立開來成為單獨的Catalog Service。將元數據獨立會帶來很多的好處,一方面可以將HAWQ++元數據與Hadoop集群元數據進行融合,另一方面可以不再區分HAWQ++ master/slave角色,任意節點都可以接收查詢處理查詢,更好地實現負載均衡。HAWQ++每個Slave節點上都部署有一個HDFS DataNode,一個YARN NodeManager以及一個HAWQ++ Segment。其中YARN是可選組件。如果沒有YARN的話,HAWQ++會使用自己內置的資源管理器。HAWQ++ Segment在執行查詢的時候會啟動多個QE(Query Executor,查詢執行器)。查詢執行器運行在資源容器里。在這個架構下,節點可以動態的加入集群,并且不需要數據重分布。當一個節點加入集群時,它會向HAWQ++ Master節點發送心跳,然后就可以接收未來查詢了。
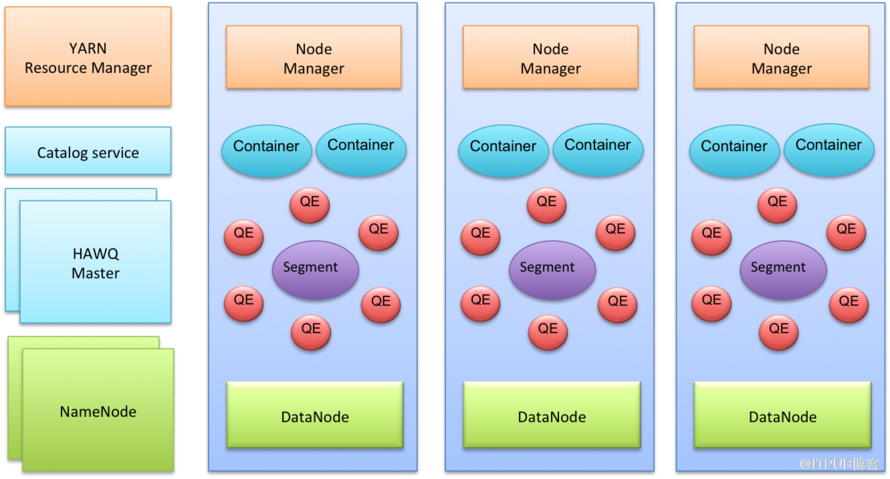
圖1 HAWQ++體系架構
HAWQ++內部架構
圖2是HAWQ++內部架構圖。可以看到在HAWQ++ Master節點內部有如下重要組件:查詢解析器,優化器,資源代理,資源管理器,HDFS元數據緩存,容錯服務,查詢派遣器和元數據服務。在Slave節點上安裝有一個物理Segment,在查詢執行時,針對一個查詢,彈性執行引擎會啟動多個虛擬Segment同時執行查詢,節點間數據交換通過Interconnect(高速互聯網絡)進行。如果一個查詢啟動了1000個虛擬Segment,意思是這個查詢被均勻的分成了1000份任務,這些任務會并行執行。所以說虛擬Segment數其實表明了查詢的并行度。查詢的并行度是由彈性執行引擎根據查詢大小以及當前資源使用情況動態確定的。這里簡單說一下幾個組件的作用。Parser做詞法語法分析,生成一棵Parse Tree,交給Analyzer做語義分析生成一棵Query Tree,再經過基于規則系統的Rewriter將一棵Query Tree可能改寫成Query Tree List,交給優化器做邏輯優化和基于cost的物理優化,生成優化的并行Plan。資源管理器通過資源代理向全局資源管理器(比如YARN)動態申請資源并緩存資源,在不需要的時候返回資源。HDFS元數據緩存用于確定HAWQ++哪些Segment掃描表的哪些部分。因為HAWQ++的計算和數據是完全分離的,所以需要data locality信息把計算派遣到數據所在的地方。如果每個查詢都去訪問NameNode獲取位置信息會造成NameNode的瓶頸,所以建立了元數據緩存。容錯服務負責檢測哪些節點可用,哪些節點不可用。不可用的機器會被排除出資源池。優化完的Plan由查詢派遣器發送到各個節點上執行,并協調查詢執行的全過程。元數據服務負責存儲HAWQ++的各種元數據,包括數據庫和表信息,以及訪問權限等等。高速互聯網絡負責在各節點間傳輸數據,默認基于UDP協議。UDP協議不需要建立連接,可以避免TCP高并發連接數的限制。HAWQ++通過libhdfs3模塊訪問HDFS。libhdfs3是Hadoop Native的C/C++接口,相比JNI的接口具有部署方便,消耗資源少和高性能的優勢。
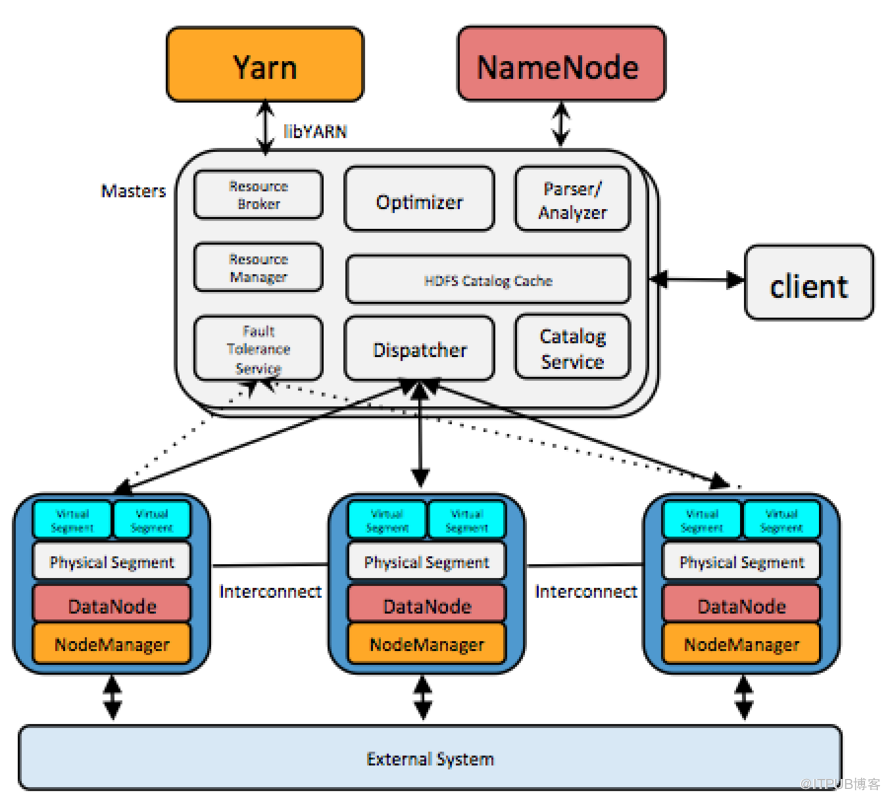
圖2 HAWQ++內部架構
HAWQ++并行優化器
接下來具體解釋一下HAWQ++并行優化器這個模塊,因為在一款數據庫系統里優化器在很大程度上決定了SQL執行性能的好壞。HAWQ++原生優化器是在PostgresSQL優化器的基礎上開發的,簡單來說就是在pg生成的串行plan上插入了Motion的操作。Motion代表數據的移動,底層是通過高速互聯網絡實現的。基于插入的Motion,plan被切割成若干個Slice。同一個Slice在不同節點上可以并行執行。Motion一共有三類:1.Redistribute Motion,負責按照hash鍵值重新分布數據;2.Broadcast Motion,負責廣播數據;3.Gather Motion,負責搜集數據到一起。圖3中左邊的查詢計劃表示了一個不需要重新分布數據的例子,因為表lineitem和orders都使用了連接鍵進行分布。而如果這兩張表都是隨機分布,那么就會生成右邊的查詢計劃,和左邊查詢計劃相比多了一個Redistribute Motion的節點。可能有些人會有疑問,HAWQ++的數據存儲在HDFS上,如果遇到HDFS加減節點某個Datanode上的block可能會被rebalance到其他Datanode上,那么對于hash分布的表不做Redistribute Motion怎么能夠直接做HashJoin?原因在于對于hash分布的表HAWQ++有維護QE和寫入文件的映射關系,所以即便該文件某個block不在本地了,那么影響的也只是對于該block的本地讀還是遠程讀,和是否需要做Redistribute Motion是沒有關系的。另外基于cost的物理優化的輸入數據來源于統計信息,因此預先通過analyze命令收集表的統計信息可以幫助優化器產生更為優化的Plan。
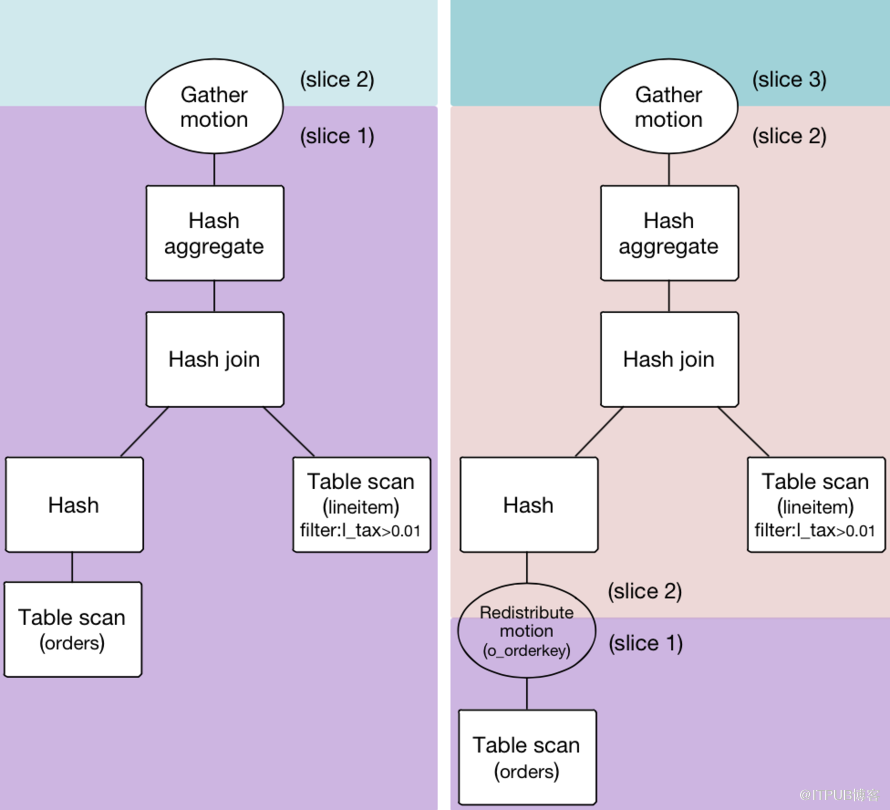
圖3 并行查詢計劃
HAWQ++查詢處理流程
圖4展示了圖3中右邊查詢計劃的處理流程。HAWQ++的Master節點收到客戶端的連接請求會啟動QD(Query Dispatcher,查詢派遣器),進入詞法分析,語法分析,語義分析,優化器生成并行的Plan,再根據查詢數據量大小以及當前資源使用情況,結合datalocality的信息,計算出需要啟動多少個virtual segment以及在哪些segment節點上啟動這些VSEG。接著dispatcher模塊會通過libpq協議連接這些segment節點啟動QE,同時把并行plan做序列化經過壓縮dispatch過去。VSEG是一個邏輯的概念,如圖4中包含任意一組分別執行slice1和slice2的QE進程。同一個slice在所有VSEG上的QE進程集合我們稱為一個gang。每一個QE收到屬于自己的slice構建一棵查詢執行器樹,樹中每一個節點稱做一個operator,對應各自的執行器節點實現邏輯。HAWQ++整個執行流程是Pipeline的模式,從上往下pull數據。Gang與gang之間的slice通過Motion傳輸數據,最終所有數據通過Gather Motion匯集到Master節點上返回給客戶端。
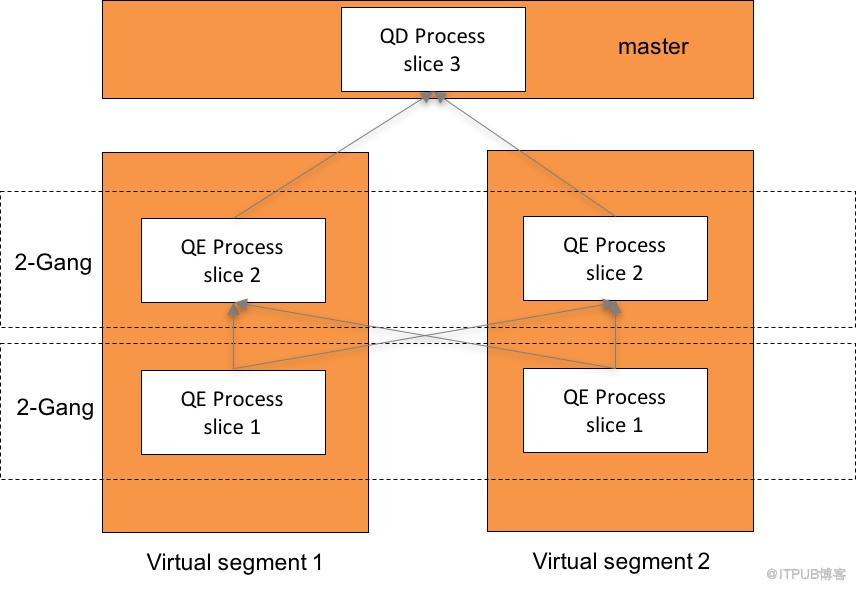
圖4 查詢處理流程
HAWQ++彈性執行引擎
HAWQ++彈性執行引擎是區別于傳統MPP數據庫的關鍵技術。針對傳統MPP數據庫,比如Greenplum Database,因為Segment配置死板,SQL計算執行往往必須調動所有集群節點,造成資源浪費,約束SQL并發能力。每個節點又有各自獨占的目錄和數據,對每個節點的可用性有比較嚴格的要求,擴展復雜。而HAWQ++引入的彈性執行引擎通過存儲和計算的完全分離使得我們可以啟動任意多個虛擬Segment來執行查詢。每一個Segment都是無狀態的,元數據和事務管理在Master節點實現,因此加入集群的Segment節點無需狀態同步,用戶可根據需要動態加減節點。針對每一條具體的查詢,根據用戶配置、SQL特征以及實時數據庫運轉狀態動態決定SQL執行的計算并發度,動態分配使用健康低負載節點。同時根據表數據塊分布動態分配IO任務到并行VSEG上,實現最優本地讀取比例,保障最優SQL執行性能。
HAWQ++可插拔外部存儲
HAWQ++可插拔外部存儲基于增強版的外部表讀寫框架開發完成,通過新框架HAWQ++可以更加高效地訪問更多類型外部存儲,可以實現可插拔文件系統,比如S3,Ceph等,以及可插拔文件格式,比如ORC,Parquet等。同內部表一樣,HAWQ++可以根據查詢數據量大小和數據庫資源利用率等動態調整集群中外部表讀寫并發數,根據數據分布選擇最優計算節點,從而達到優化和靈活控制外部表訪問性能的效果。相比于Apache HAWQ原有的外部數據訪問方案PXF,可插拔外部存儲避免了數據傳輸路徑中的多次數據轉換,打破了通過固有并行度提供外部代理的方式,給用戶提供了更簡單更有效的數據導入導出方案,而且性能高數倍。
HAWQ++容器云支持
HAWQ++是世界上第一個可以原生運行在容器云平臺中的MPP SQL引擎。眾所周知,將簡單的無狀態應用(比如Web服務器)遷移到容器比較簡單,而將大數據平臺遷移到容器卻面臨很多技術挑戰。HAWQ++支持在主流Kubernetes CaaS平臺的安裝部署,HAWQ++ 的服務運行在CaaS平臺管理的Docker容器中。在Kubernetes上部署HAWQ++和部署其他應用集群一樣,都可以通過Dashboard用戶界面或者命令行進行部署,也可以像管理其他CaaS平臺應用程序一樣來管理HAWQ++集群。將HAWQ++和云平臺結合帶來應用和服務一體化,很容易做彈性擴容,自恢復和滾動升級。在資源管理和自動化運維也帶來很多便捷。
HAWQ++展望
目前HAWQ++還在持續不斷的開發過程當中,在不久的將來會添加update/delete 功能,成為云時代大數據管理引擎當之無愧的領跑者。

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





