溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
復雜SQL查詢跑不動以及DRDS 只讀的解決方法,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
背景
在實際業務生產環境中,業務應用系統在使用 OLTP 數據庫將數據進行存儲后,均會存在如后臺運營類系統進行統計報表分析等場景的復雜 SQL 查詢訴求。
為滿足此類復雜 SQL 查詢快速響應的需求,DRDS 團隊基于第三代分布式SQL引擎,進一步引入自研 MPP 多機并行計算引擎(Fireworks)及對應的優化策略,極大地補強了 DRDS 的復雜查詢處理能力。
千萬級數據下的分布式多表Join、聚合、排序、子查詢操作秒級返回結果,可極大的提升響應速度。自身利用同一份數據(RDS只讀)進行處理,無需數據同步至其他數據源,降低業務架構整體鏈路復雜度,節省業務運維及預算成本。cdn.com/bad94739b4a209f57ac0b01de9d57aeabf467d49.png">
主要特性
自研 MPP 多機并行計算引擎 Fireworks
DRDS 只讀實例搭載了一個具備完整多機并行處理能力的 SQL 執行引擎(Fireworks)。它與 DRDS 主實例上搭載的 SQL 執行引擎有顯著差異。
DRDS 主實例的執行引擎采用單機架構,采取盡可能將計算下推至底層各物理分庫執行的策略,依靠物理分庫的計算能力實現了邏輯SQL的分布式計算。
而 DRDS 只讀實例上搭載的 Fireworks 引擎是一個由多個計算節點組成的集群,將一個 SQL 查詢轉換為一個分布式計算任務,突破下掛
物理庫計算能力的限制,大幅提升針對復雜邏輯SQL的計算速度,對 Join、Aggregate 和 Sort 計算有顯著加速效果。
Fireworks 會將 Join、Aggregate 和 Sort 這類計算任務通過 Shuffle 的方式打散并分發到計算集群的多個計算節點上,通過多計算節點并行計算達到計算加速的目的。
針對多機并行執行模式定制打造的優化器
原 DRDS 主實例優化器主要側重 OLTP 場景,核心理念是盡量將一切計算下推至下掛的物理庫執行。其目的是充分利用物理庫的計算資源,同時可以避免產生大量的數據流動,從而得到較快的響應速度。
而當面對涉及較大數據量級下的復查查詢場景時,整體性能會受到下掛物理庫的限制,同時也會對物理庫產生較大的壓力從而影響穩定性,總體來看其 OLAP 能力有很多局限性。
在引入了 MPP 多機并行計算引擎 Fireworks 之后,DRDS 本身在計算能力上得到了極大地提升,優化器的整體優化策略也有所調整:
盡量將復雜計算(如 Join 、Aggregation 、Sort )上提至自身執行引擎計算,通過 Fireworks 計算集群實現計算加速與可擴展性;
將輕量級的計算(如 Project 、Filter )繼續下推至至物理庫從而減少數據拉取的成本。
DRDS 分布式 SQL 優化器通過對執行計劃最細粒度的優化可以產生出對多機并行執行引擎友好的執行計劃,獲得更好執行效率。
同時提供精細化算子下推策略,將對 RDS 較小壓力的算子下推至物理庫取得更高的計算性價比,同時保護 RDS 免受代價較大算子的影響,從而保證在線流量的穩定性。
基于在線數據直接分析
以新零售業務為代表的新興互聯網業務不斷涌現,這類業務除了有實時的 OLTP 需求,還伴隨著一些有一定復雜度的準實時 OLAP 的需求用以支持實時決策等需求。
而目前大多數的數據分析場景的解決方案均需要將 OLTP 數據庫的生產數據導出至其他數據源進行再次離線分析,這種傳統方案很難滿足準實時的需求,同時在數據導出至離線系統時也存在數據丟失的風險。
DRDS 只讀實例無需進行冗長繁瑣的數據同步任務,基于 RDS 只讀實例或 RDS 主實例直接進行復雜數據處理,降低業務架構整體鏈路復雜度,節省業務運維及預算成本。
DRDS 只讀實例在避免數據同步的同時,可保證數據處理時效性,最高可做到 READ COMMITED 的實時性 (基于 RDS 主實例)。
邊界清晰的 SQL 兼容性
DRDS 只讀實例全面兼容 DRDS 主實例的 SQL 查詢語法,與 DRDS 5.3 版本的 SQL 兼容性和 SQL 支持邊界高度保持一致。
與同類產品相比具備兼容性高以及支持邊界清晰的特點。可以提供與 DRDS 主實例幾乎一致的體驗。
DRDS 主實例上無法執行或執行較慢的復雜 SQL 可以直接遷移到只讀實例來執行,免去SQL改寫的額外開銷。
產品體驗靈活自主
DRDS 只讀實例自動同步 DRDS 主實例的賬號權限信息,原生VPC支持,內外網可同時開啟,根據業務情況靈活變配,數據處理能力線性提升。
技術架構總覽
DRDS 只讀實例整體架構與 DRDS 主實例基本保持一致,僅在查詢層有所變化,增加了 MPP 執行引擎和對應優化器,如下如所示:
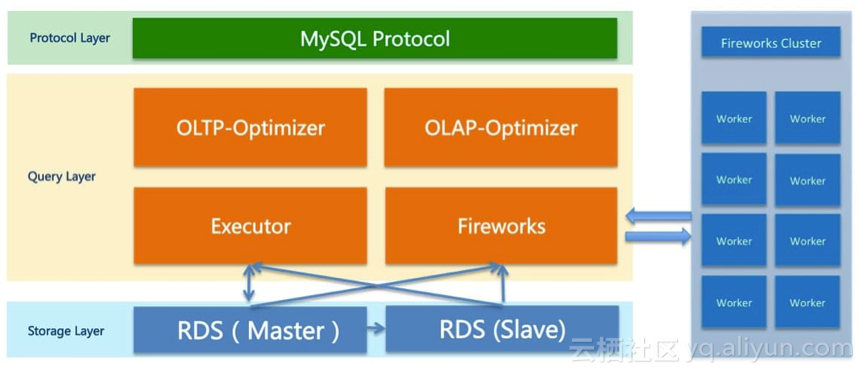
DRDS協議層負責處理網絡交互與 MySQL 協議的解析,收到查詢請求后會將 SQL 轉交至查詢層處理。查詢層負責解析 SQL 并由執行器產生經過優化的執行計劃,然后交由執行引擎到存儲層進行查詢以及計算。
如果需要使用 Fireworks 引擎計算,在得到執行計劃之后查詢層還會將該執行計劃進一步轉換為分布式執行計劃并將其作為分布式任務提交給 Fireworks Cluster。由遠端的 Fireworks 集群完成到存儲層進行數據查詢以及后續計算的工作。
簡單來說,DRDS 只讀實例可以認為是在原 DRDS 基礎上增加了一條具備多機并行處理能力的執行鏈路。
適用場景
總體來說 DRDS 只讀實例適用于處理低并發高延遲的大數據量級下的復雜查詢。如數據分析及報表類場景,該類場景的典型特征為含有大
量的關聯、聚合及排序操作且參與計算的數據規模較大。
目前 DRDS 只讀實例在阿里集團內部已經落地了多個業務,其中最具代表性的當屬盒馬、商業大腦等新零售場景。圍繞人、貨、場、倉多個維度進行關聯分析,對分散在不同邏輯庫的幾張甚至十幾張邏輯表進行關聯然后再聚合、排序以滿足庫存對賬、決策支持等業務上的需求。
DRDS 只讀實例的出現使業務開發同學不再需要配置、維護數量繁多的數據同步鏈路,不用擔心因數據不同步而造成的結果時效性差或不準確等問題,一定程度上減輕了開發同學的工作負擔。
對于已經在使用 DRDS 的用戶來說,DRDS 只讀實例可以解決如下兩類已知問題:
在使用 DRDS 過程中可能會發現某一些涉及Join、聚合、排序的復雜 SQL因為不能完全下推而需要在DRDS執行引擎中進行二次計算,而這種計算因為受到單機執行引擎在內存方面的限制而無法執行。
SQL 的復雜計算部分可以下推但是涉及到的數據規模較大造成物理庫壓力增高影響 OLTP 業務或者響應時間過慢達不到要求。
小結
長期以來 DRDS 受到單機架構執行引擎的限制一直無法對基于大數據規模的復雜查詢提供很好的支持,也無法通過擴展物理資源來實現對自身本地計算能力的線性擴展。
DRDS只讀實例的推出徹底地彌補了 DRDS 在 OLAP 場景下的短板,使得 DRDS 在提供強大 OLTP 能力的同時提供可擴展的 OLAP 能力,為同時具有 OLTP 需求與中等規模數據分析需求的用戶提供了一站式整體解決方案,為用戶帶來便利。
后續半年時間內 DRDS 只讀實例將發布跨邏輯庫的關聯查詢功能,并通過更多的技術手段,不斷增強只讀實例核心能力,在并發度、響應時間、數據量、交互式查詢等方面將擁有更好的表現,滿足企業級應用對數據庫的嚴苛要求。
目前 DRDS 只讀實例與 DRDS 主實例同享8折限時優惠,活動詳情
https://promotion.aliyun.com/ntms/act/drdsreadonlydisc.html
歡迎大家持續關注 DRDS(阿里云分布式關系型數據庫服務),產品詳情
https://www.aliyun.com/product/drds
關于復雜SQL查詢跑不動以及DRDS 只讀的解決方法問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





