溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
原文: https://www.modb.pro/db/6143
前言
一年一度的數據庫領域頂級會議VLDB 2019于美國當地時間8月26日-8月30日在洛杉磯召開。在本屆大會上,阿里云數據庫產品團隊多篇論文入選Research Track和Industrial Track。
本文將對入圍ResearchTrack 的論文《iBTune: Individualized Buffer Tuning for Largescale Cloud Databases》進行詳細解讀,以饗讀者。
背景
大概五六年前,阿里數據庫團隊開始嘗試如何將DBA的經驗轉換成產品,為業務開發提供更高效,更智能的數據庫服務。從14年CloudDBA開始為用戶提供自助式智能診斷優化服務,經過四年的持續探索和努力,18年進化到CloudDBA下一代產品
—— 自治數據庫平臺SDDP(Self-Driving Database Platform)。
SDDP是一個賦予多種數據庫無人駕駛能力的智能數據庫平臺,讓運行于該平臺的數據庫具備自感知、自決策、自恢復、自優化的能力,為用戶提供無感知的不間斷服務。自治數據庫平臺涵蓋了非常多的能力,包括物理資源管理,實例生命周期管理,診斷優化,安全,彈性伸縮等,而其中自動異常診斷與恢復和自動優化是自治數據庫平臺最核心的能力之一。
2017年底,SDDP開始對全網數據庫實例進行端到端的全自動優化,除了常見的自動慢SQL優化和自動空間優化外,還包含了本文重點介紹的大規模數據庫自動參數優化。
基于數據驅動和機器學習算法的數據庫參數優化是近年來數據庫智能優化的一個熱點方向,但也面臨著很大的技術挑戰。要解決的問題是在大規模數據庫場景下,如何對百萬級別運行不同業務的數據庫實例完成自動配置,同時權衡性能和成本,在滿足SLA的前提下資源成本最低,該技術對于CSP(Cloud Service Provider)有重要價值。
學術界近一兩年在該方向有一些研究(比如CMU的OtterTune),但該算法依賴于一些人工先驗經驗且在大規模場景下不具備可擴展性。據了解, 其他云廠商Azure SQL Database以及AWS該方向都有投入,目前尚未看到相關論文或產品發布。
從18年初開始我們開始數據庫智能參數優化的探索,從問題定義,關鍵算法設計,算法評估及改進,到最終端到端自動化流程落地,多個團隊通力合作完成了技術突破且實現了大規模落地。
由譚劍、鐵贏、飛刀、艾奧、祺星、池院、洪林、石悅、鳴嵩、張瑞共同撰寫的論文《iBTune: Individualized Buffer Tuning for Largescale Cloud Databases》被VLDB 2019 Research Track接受,這是阿里巴巴在數據庫智能化方向的重要里程碑事件。
這項工作不僅在數據庫智能參數優化理論方面提出了創新想法,而且目前已經在阿里集團~10000實例上實現了規模化落地,累計節省~12%內存資源,是目前業界唯一一家真正實現數據庫智能參數優化大規模落地的公司。
問題定義
參數優化是數據庫優化的重要手段,而數據庫參數之多也增加了參數調優的難度,比如最新版本的MySQL參數超過500,PostgreSQL參數也超過290。通常數據庫調優化主要關心性能相關的參數,而其中對性能影響最大的是Buffer Pool的設置。
目前集團環境多個數據庫實例共享主機的部署方式導致經常出現主機內存嚴重不足,但CPU和存儲資源還有較多剩余,造成了機器資源浪費,因此內存資源緊張成為影響數據庫實例部署密度的關鍵瓶頸。
Buffer Pool是內存資源消耗的最大頭,如何實現Buffer Pool最優配置是影響全網機器成本的關鍵,同時也是影響數據庫實例性能的關鍵,因此我們將智能參數優化重點放在了Buffer Pool參數優化。
對于大規模數據庫場景,挑戰在于如何為每個數據庫實例配置合理的Buffer Pool Size,可以在不影響實例性能的前提下,Buffer Pool Size最小。傳統大規模數據庫場景為了方便統一管控,通常采用靜態配置模板的配置數據庫實例參數。
以阿里集團數據庫場景為例,集團內提供了10種BufferPool規格的數據庫實例供業務方選擇。開發同學在申請實例時,由于不清楚自己的業務對BP的需求是什么,通常會選用默認配置規格或者較高配置規格。這種資源分配,帶來了嚴重的資源浪費。
另外業務多樣性和持續可變性使得傳統依賴DBA手工調優方式在大規模場景下完全不可行,因此基于數據驅動和機器學習算法來根據數據庫負載和性能變化動態調整數據庫Buffer Pool成為一個重要的研究問題。
問題分析
從問題本身來看,緩存的大小(BP)與緩存命中率(hit ratio)是存在直接關系的。設想一下,如果可以找到一個公式BP=Function(hit_ratio),然后從業務方或者DBA的視角找到一個業務可接受的緩存命中率,就可以下調BP且不影響業務。
經過調研,我們發現在操作系統的Cache研究領域中,研究者已經對buffer size和hit ratio的對應關系有了很多研究,其中有研究表明在數據長尾部分這二者的關系服從Power Law分布,即:
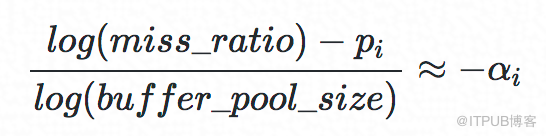
其中,
αi是Power Law分布的指數,miss_ratio=1?hit_ratio。
經過上面的理論調研,關系模型已經得到解決,接下來需要求解該模型中的超參數,即MySQL數據庫Cache的αi。
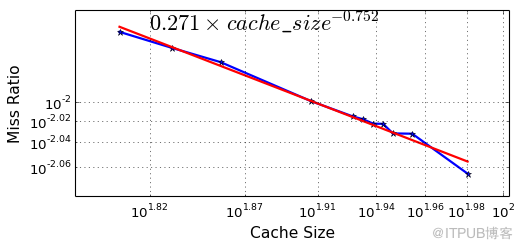
在集團DBA同學開發的Frodo工具幫助下,我們針對集團內的幾個重要OLTP場景(例如購物車場景、交易支付場景)進行了不同BP配置的壓測實驗。實驗結果也印證了前面的理論結果,在長尾部分MySQL的緩存確實是符合Power Law分布假設的。
于是,給定當前未命中率 mrcur、當前BP大小BPcur和目標未命中率 mrtarget的情況下,我們可以推導出如下公式來計算調整后的BP BPtarget,公式:
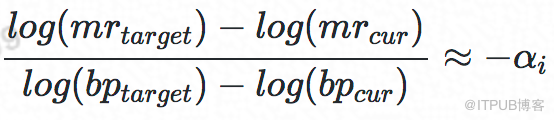
通過上面的理論調研和MySQL實際場景驗證,該理論公式經驗證在MySQL場景下成立,并且可計算出關鍵系數αi,接下來看如何計算 miss_ratiotarget。
尋找合適的miss ratio
阿里巴巴集團中有數萬+數據庫實例主節點,我們考慮從這數萬數據庫中尋找與待調整實例相似的實例,然后利用這些相似實例的miss ratio來找到待調整實例的目標miss ratio.
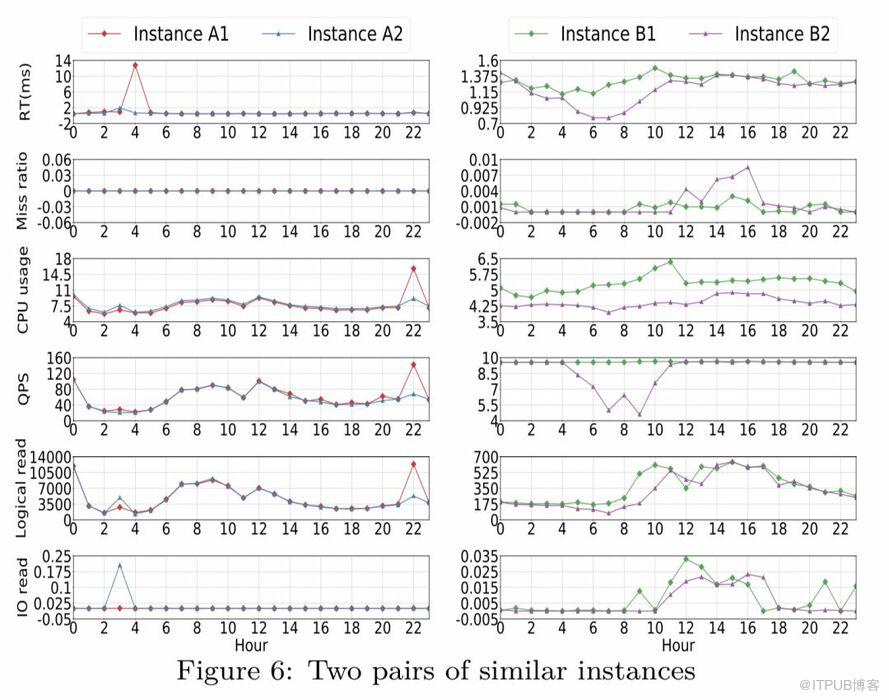
特征選擇上,我們選用了CPU usage, logical read, io read, miss ratio, response time 等性能指標來描述一個業務workload,并對這些特征選取了幾個統計量(如mean、media、70th percentile、90th percentile)作為具體的特征數值。
為了降低工作日、周末對數據的影響,我們選取了跨度4周的性能數據來做相似度計算,下圖為兩對相似實例的示例。
算法挑戰
經 過前部分的處理,公式、參數和目標mr都有了,已經可以代入公式計算出目標BP,接下來需要解決算法在工程落地過程中所面臨的問題。
由于hit ratio這個指標并不能直接的反應數據庫對業務的影響,導致業務方和DBA都沒有直接的體感,并且該指標也不能用來直接衡量數據庫業務穩定性。因此,受限于穩定性要求,該算法在無法給出對業務影響的量化數值情況下,尚不能落地具體業務。
針對這個問題,經過與DBA和業務方的多次討論,我們發現業務方和DBA最關心的是數據庫的Response Time(RT),尤其是數據庫實例對應用服務時的最大RT。
設想一下,如果可以預測出BP調整后的數據庫實例RT的最差值,也就是RT的上界RT upperbound,那么就可以量化的描述出調整BP之后對業務的影響,也就消除了業務方與DBA對該參數優化的擔憂,算法就具備了落地生產環境的必要條件。于是,我們對數據庫實例RT upperbound進行了算法預測。
RT預測模型
針對RT預測問題,我們提出了一個pairwise的DNN模型,具體的結構如圖:
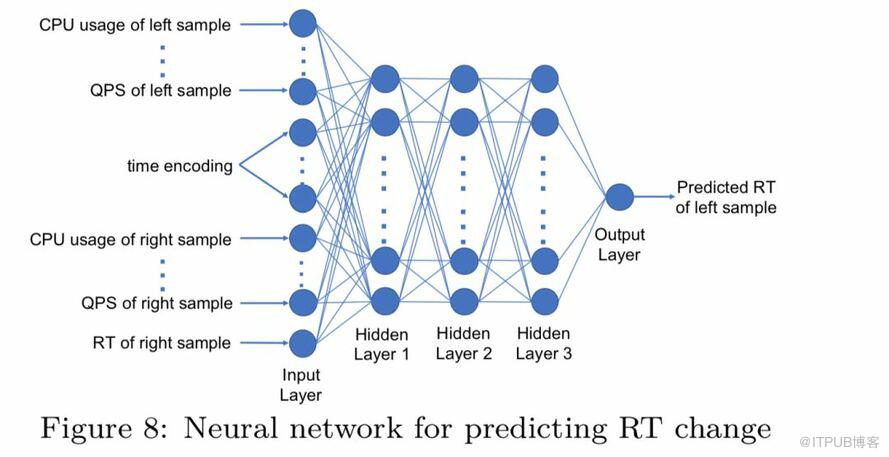
在訓練階段,左實例代表的是我們要預測RT的實例,右實例代表的是某一個相似實例(前面尋找 mrtarget時篩選出的相似實例),左右實例的RT都是已知的。
在測試階段,我們用該模型來預測實例BP調整后的RT,左右實例均是當前實例,但是把mrcur替換成 mrtarget。
該DNN網絡模型中采用了全連接形式,激活函數為ReLU,隱藏層節點數分別為100,50,50。
損失函數:
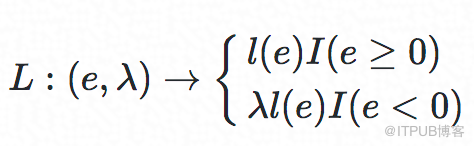
其中I(.)是個指示函數,e=RT? RTpredict,λ∈[0,1]是個超參數,e=RT?RTpredict,用來控制underestimate時的懲罰程度。
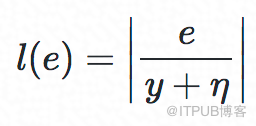
其中,y為實際RT觀測值。由于不同實例y的值域跨度很大,我們將e用y來做正則化,同時增加η來避免RT非常小時引入的優化誤差。
實驗
在預測RT的實驗中,我們對比了包括線性回歸模型(LR)、XGBoost、RANSAC、決策樹(DTree)、ENet、AdaBoost線性回歸(Ada)、GBDT、k近鄰回歸(KNR)、bagging Regressor(BR)、extremely randomized trees regressor (ETR)、隨機森林(RF)、sparse subspace clustering (SSC)等回歸算法,DNN模型、添加了embedding層進行instance-to-vector轉換的DNN(I2V-DNN)模型,以及pairwise DNN模型等深度學習算法。
I2V-DNN的結構如圖:
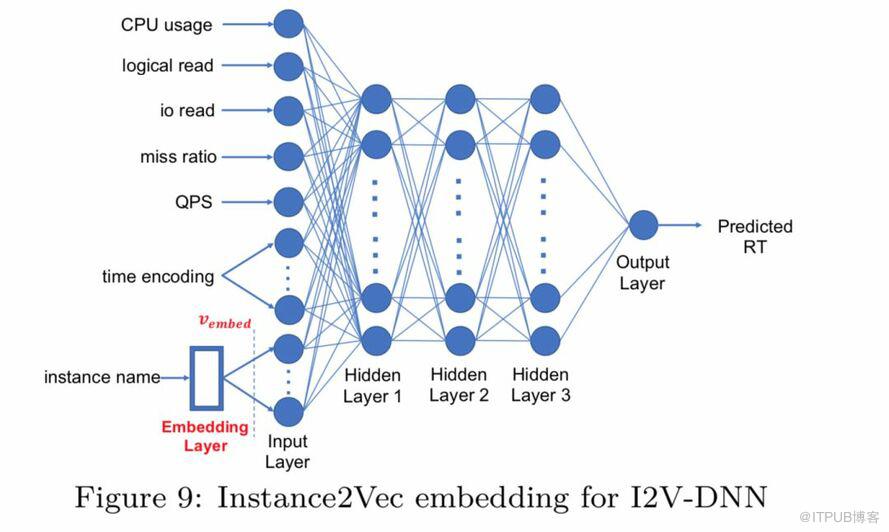
為了證明該算法的普適性,我們從集團數據庫的幾個重要業務場景中選擇了1000個實例,覆蓋了不同讀寫比的示例,包括只讀示例、只寫實例、讀寫均衡實例等情況。
在評價算法效果方面,我們主要采用了如下3個評價指標:
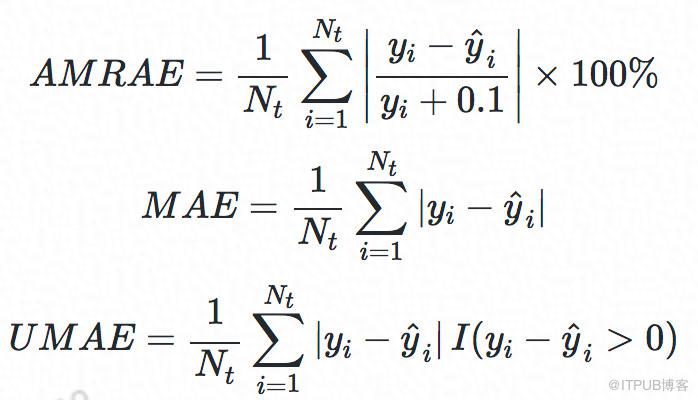
其中,AMRAE可以評估出RT預測結果的誤差比例,MAE用于衡量RT預測的平均誤差,UMAE用于衡量RT預測值低估的情況。
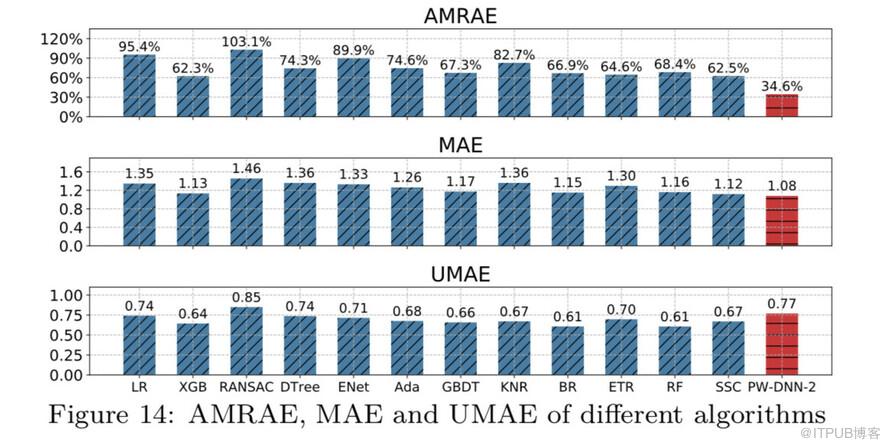
在實驗數據集上,RT預測結果對比如圖:
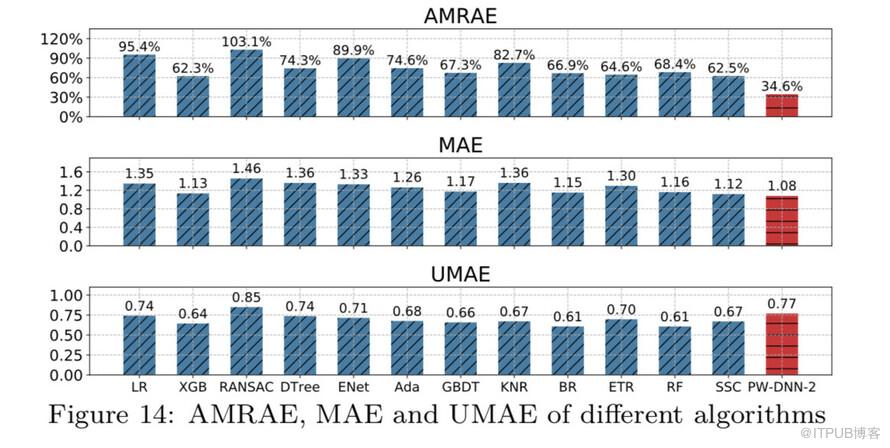
由上圖看出,PW-DNN模型在AMRAE這一指標上對比其他算法優勢比較明顯,綜合其他指標,PW-DNN模型的算法效果最好,所以我們最終選擇用來預測RT的算法是PW-DNN。
實際效果
為了更加直觀的觀察實例變更BP前后的變化,我們隨機選擇了10個實例來展示調整BP前后數據庫各項指標,數據如圖:
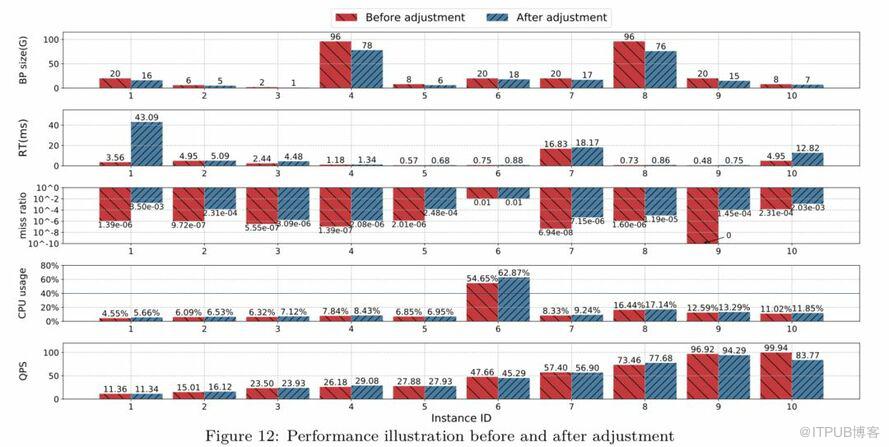
從上圖中可以看出,不同規格實例在調整BP之后的RT與調整之前的RT相差不大(實例1除外)。通過QPS、CPU usage可以看出,調整前后的業務訪問量相差不大,并且資源消耗很接近,但節省了不同幅度的內存。
在實例1中出現了調整后RT大幅上升的情況,經過對該case的仔細排查發現,該業務的日常QPS非常低,耗時占比最高的只有一個query,在調整后該query查詢的值不一樣,導致logical read和physical read升高很多,因此最終平均RT的值也升高很多。但是調整后RT的絕對值并不大,沒有發生慢SQL異常,對業務來說是可以接受的,因此沒有觸發回滾操作。
落地
我們實現了一個端到端的算法落地流程,從數據采集到BP優化指令的執行。該系統包含4個主要模塊,分別是指標采集、數據處理、決策和執行,模塊設計如圖:
· 指標采集:數據庫管控平臺已經實現對集團內全部數據庫實例的指標數據采集,覆蓋了算法所使用的各項指標;
· 數據處理:采集后的指標經過流式處理進行不同窗口維度的統計匯總,并存儲在odps中供算法使用;
· 決策:本文算法的具體實現部分,讀取odps中存儲的指標統計數據,經算法模型計算得到待優化實例調整后的BP值;
· 執行:數據庫管控平臺對BP優化指令進行專項實現,并調度該優化操作的具體執行時間窗口,在符合發布約束的前提下高效執行該操作。
穩定性挑戰
由于降低BufferPool配置的這個操作是個會降低穩定性的操作,一旦操作不當,輕則給DBA帶來額外工作,重則引發業務故障。因此,該項目受到了BU內DBA和各穩定性相關同學的挑戰和壓力。
我們主要采取了多項措施來確保業務穩定性,具體包括:
1. 算法模型: 調整BufferPool大小與緩存命中率映射關系的敏感系數αα,使調整結果較為保守;
2. 在線調整:我們僅針對可online調整參數的實例進行調整,避免因MySQL內核原因導致MySQL crash的情況;
3. 灰度策略:全網規模化參數調整采用了嚴格的灰度策略,最開始由業務DBA根據算法給出的BP大小進行少量實例調整,確保業務穩定;然后通過較多實例的白名單機制,僅對白名單中的實例自動調整BufferPool大小,在指定范圍內實例上進行灰度;最后,在業務DBA確認過非核心實例上,嚴格按照發布流程和管控流程進行規模化全自動操作,并嚴格限制每次操作的數量。
4. 流程閉環:從數據采集,BP大小決策、自動化BP調整到調整后的量化跟蹤,以及回滾機制,整個流程閉環,每天發出調整后的統計分析報告。
成果
經過算法探索和端到端自動Buffer Pool優化流程建設,FY2019集團內全網最終優化 ~10000 個實例,將整體內存使用量從 217T內存縮減到 190T內存,節省 12.44%內存資源(27TB)。
未來
業務方面,FY2020我們一方面繼續擴大BP優化的實例范圍以節省更多的內存資源;另一方面將繼續優化該算法模型通過HDM產品輸出到公有云,為云上用戶提供數據庫實例規格建議。
技術方面,我們將從Buffer Pool參數優化擴展到數據庫其他性能參數優化,探索多性能參數之間的關系及影響,建立基于數據庫負載和性能關系影響模型,從整個數據庫實例視角進行統一數據庫參數優化。
想了解更多關于數據庫、云技術的內容嗎?
快來關注“數據和云"、"云和恩墨,"公眾號及"云和恩墨"官方網站,我們期待大家一同學習與進步!

數據和云小程序”DBASK“在線問答,隨時解惑,歡迎了解和關注!

免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





