溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關怎么進行Oracle 執行計劃的說明,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
如果要分析某條SQL的性能問題,通常我們要先看SQL的執行計劃,看看SQL的每一步執行是否存在問題。 如果一條SQL平時執行的好好的,卻有一天突然性能很差,如果排除了系統資源和阻塞的原因,那么基本可以斷定是執行計劃出了問題。
看懂執行計劃也就成了SQL優化的先決條件。 這里的SQL優化指的是SQL性能問題的定位,定位后就可以解決問題。
一. 查看執行計劃的三種方法
1.1 設置autotrace
序號 | 命令 | 解釋 |
1 | SET AUTOTRACE OFF | 此為默認值,即關閉Autotrace |
2 | SET AUTOTRACE ON EXPLAIN | 只顯示執行計劃 |
3 | SET AUTOTRACE ON STATISTICS | 只顯示執行的統計信息 |
4 | SET AUTOTRACE ON | 包含2,3兩項內容 |
5 | SET AUTOTRACE TRACEONLY | 與ON相似,但不顯示語句的執行結果 |
SQL> set autotrace on
SQL> select * from dave;
ID NAME
---------- ----------
8 安慶
1 dave
2 bl
1 bl
2 dave
3 dba
4 sf-express
5 dmm
已選擇8行。
執行計劃
----------------------------------------------------------
Plan hash value: 3458767806
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8 | 64 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| DAVE | 8 | 64 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------
統計信息
----------------------------------------------------------
0 recursive calls
0 db block gets
4 consistent gets
0 physical reads
0 redo size
609 bytes sent via SQL*Net to client
416 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
8 rows processed
SQL>
1.2 使用SQL
SQL>EXPLAIN PLAN FOR sql語句;
SQL>SELECT plan_table_output FROM TABLE(DBMS_XPLAN.DISPLAY('PLAN_TABLE'));
示例:
SQL> EXPLAIN PLAN FOR SELECT * FROM DAVE;
已解釋。
SQL> SELECT plan_table_output FROM TABLE(DBMS_XPLAN.DISPLAY('PLAN_TABLE'));
或者:
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 3458767806
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8 | 64 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| DAVE | 8 | 64 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------
已選擇8行。
執行計劃
----------------------------------------------------------
Plan hash value: 2137789089
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8168 | 16336 | 29 (0)| 00:00:01 |
| 1 | COLLECTION ITERATOR PICKLER FETCH| DISPLAY | 8168 | 16336 | 29 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
統計信息
----------------------------------------------------------
25 recursive calls
12 db block gets
168 consistent gets
0 physical reads
0 redo size
974 bytes sent via SQL*Net to client
416 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
8 rows processed
SQL>
1.3 使用Toad,PL/SQL Developer工具
二. Cardinality(基數)/ rows
Cardinality值表示CBO預期從一個行源(row source)返回的記錄數,這個行源可能是一個表,一個索引,也可能是一個子查詢。 在Oracle 9i中的執行計劃中,Cardinality縮寫成Card。 在10g中,Card值被rows替換。
這是9i的一個執行計劃,我們可以看到關鍵字Card:
執行計劃
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=402)
1 0 TABLE ACCESS (FULL) OF 'TBILLLOG8' (Cost=2 Card=1 Bytes=402)
Oracle 10g的執行計劃,關鍵字換成了rows:
執行計劃
----------------------------------------------------------
Plan hash value: 2137789089
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8168 | 16336 | 29 (0)| 00:00:01 |
| 1 | COLLECTION ITERATOR PICKLER FETCH| DISPLAY | 8168 | 16336 | 29 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Cardinality的值對于CBO做出正確的執行計劃來說至關重要。 如果CBO獲得的Cardinality值不夠準確(通常是沒有做分析或者分析數據過舊造成),在執行計劃成本計算上就會出現偏差,從而導致CBO錯誤的制定出執行計劃。
在多表關聯查詢或者SQL中有子查詢時,每個關聯表或子查詢的Cardinality的值對主查詢的影響都非常大,甚至可以說,CBO就是依賴于各個關聯表或者子查詢Cardinality值計算出最后的執行計劃。
對于多表查詢,CBO使用每個關聯表返回的行數(Cardinality)決定用什么樣的訪問方式來做表關聯(如Nested loops Join 或 hash Join)。
多表連接的三種方式詳解 HASH JOIN MERGE JOIN NESTED LOOP
http://blog.csdn.net/tianlesoftware/archive/2010/08/20/5826546.aspx
對于子查詢,它的Cardinality將決定子查詢是使用索引還是使用全表掃描的方式訪問數據。
三. SQL 的執行計劃
生成SQL的執行計劃是Oracle在對SQL做硬解析時的一個非常重要的步驟,它制定出一個方案告訴Oracle在執行這條SQL時以什么樣的方式訪問數據:索引還是全表掃描,是Hash Join還是Nested loops Join等。 比如說某條SQL通過使用索引的方式訪問數據是最節省資源的,結果CBO作出的執行計劃是全表掃描,那么這條SQL的性能必然是比較差的。
Oracle SQL的硬解析和軟解析
http://blog.csdn.net/tianlesoftware/archive/2010/04/08/5458896.aspx
示例:
SQL> SET AUTOTRACE TRACEONLY; -- 只顯示執行計劃,不顯示結果集
SQL> select * from scott.emp a,scott.emp b where a.empno=b.mgr;
已選擇13行。
執行計劃
----------------------------------------------------------
Plan hash value: 992080948
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 13 | 988 | 6 (17)| 00:00:01 |
| 1 | MERGE JOIN | | 13 | 988 | 6 (17)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| EMP | 14 | 532 | 2 (0)| 00:00:01 |
| 3 | INDEX FULL SCAN | PK_EMP | 14 | | 1 (0)| 00:00:01 |
|* 4 | SORT JOIN | | 13 | 494 | 4 (25)| 00:00:01 |
|* 5 | TABLE ACCESS FULL | EMP | 13 | 494 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("A"."EMPNO"="B"."MGR")
filter("A"."EMPNO"="B"."MGR")
5 - filter("B"."MGR" IS NOT NULL)
統計信息
----------------------------------------------------------
0 recursive calls
0 db block gets
11 consistent gets
0 physical reads
0 redo size
2091 bytes sent via SQL*Net to client
416 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
13 rows processed
SQL>

圖片是Toad工具查看的執行計劃。 在Toad 里面,很清楚的顯示了執行的順序。 但是如果在SQLPLUS里面就不是那么直接。 但我們也可以判斷:一般按縮進長度來判斷,縮進最大的最先執行,如果有2行縮進一樣,那么就先執行上面的。
3.1 執行計劃中字段解釋:
ID: 一個序號,但不是執行的先后順序。執行的先后根據縮進來判斷。
Operation: 當前操作的內容。
Rows: 當前操作的Cardinality,Oracle估計當前操作的返回結果集。
Cost(CPU):Oracle 計算出來的一個數值(代價),用于說明SQL執行的代價。
Time:Oracle 估計當前操作的時間。
3.2 謂詞說明:
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("A"."EMPNO"="B"."MGR")
filter("A"."EMPNO"="B"."MGR")
5 - filter("B"."MGR" IS NOT NULL)
Access: 表示這個謂詞條件的值將會影響數據的訪問路勁(表還是索引)。
Filter:表示謂詞條件的值不會影響數據的訪問路勁,只起過濾的作用。
在謂詞中主要注意access,要考慮謂詞的條件,使用的訪問路徑是否正確。
3.3 統計信息說明:
db block gets : 從buffer cache中讀取的block的數量
consistent gets: 從buffer cache中讀取的undo數據的block的數量
physical reads: 從磁盤讀取的block的數量
redo size: DML生成的redo的大小
sorts (memory) :在內存執行的排序量
sorts (disk) :在磁盤上執行的排序量
Physical Reads通常是我們最關心的,如果這個值很高,說明要從磁盤請求大量的數據到Buffer Cache里,通常意味著系統里存在大量全表掃描的SQL語句,這會影響到數據庫的性能,因此盡量避免語句做全表掃描,對于全表掃描的SQL語句,建議增 加相關的索引,優化SQL語句來解決。
關于physical reads ,db block gets 和consistent gets這三個參數之間有一個換算公式:
數據緩沖區的使用命中率=1 - ( physical reads / (db block gets + consistent gets) )。
用以下語句可以查看數據緩沖區的命中率:
SQL>SELECT name, value FROM v$sysstat WHERE name IN ('db block gets', 'consistent gets','physical reads');
查詢出來的結果Buffer Cache的命中率應該在90%以上,否則需要增加數據緩沖區的大小。
Recursive Calls: Number of recursive calls generated at both the user and system level.
Oracle Database maintains tables used for internal processing. When it needs to change these tables, Oracle Database generates an internal SQL statement, which in turn generates a recursive call. In short, recursive calls are basically SQL performed on behalf of your SQL. So, if you had to parse the query, for example, you might have had to run some other queries to get data dictionary information. These would be recursive calls. Space management, security checks, calling PL/SQL from SQL—all incur recursive SQL calls。
DB Block Gets: Number of times a CURRENT block was requested.
Current mode blocks are retrieved as they exist right now, not in a consistent read fashion. Normally, blocks retrieved for a query are retrieved as they existed when the query began. Current mode blocks are retrieved as they exist right now, not from a previous point in time. During a SELECT, you might see current mode retrievals due to reading the data dictionary to find the extent information for a table to do a full scan (because you need the "right now" information, not the consistent read). During a modification, you will access the blocks in current mode in order to write to them. (DB Block Gets:請求的數據塊在buffer能滿足的個數)
當前模式塊意思就是在操作中正好提取的塊數目,而不是在一致性讀的情況下而產生的塊數。正常的情況下,一個查詢提取的塊是在查詢開始的那個時間點上存在的數據塊,當前塊是在這個時刻存在的數據塊,而不是在這個時間點之前或者之后的數據塊數目。
Consistent Gets: Number of times a consistent read was requested for a block.
This is how many blocks you processed in "consistent read" mode. This will include counts of blocks read from the rollback segment in order to roll back a block. This is the mode you read blocks in with a SELECT, for example. Also, when you do a searched UPDATE/DELETE, you read the blocks in consistent read mode and then get the block in current mode to actually do the modification. (Consistent Gets: 數據請求總數在回滾段Buffer中的數據一致性讀所需要的數據塊)
這里的概念是在處理你這個操作的時候需要在一致性讀狀態上處理多少個塊,這些塊產生的主要原因是因為由于在你查詢的過程中,由于其他會話對數據塊進行操 作,而對所要查詢的塊有了修改,但是由于我們的查詢是在這些修改之前調用的,所以需要對回滾段中的數據塊的前映像進行查詢,以保證數據的一致性。這樣就產 生了一致性讀。
Physical Reads: Total number of data blocks read from disk. This number equals the value of "physical reads direct" plus all reads into buffer cache. (Physical Reads:實例啟動后,從磁盤讀到Buffer Cache數據塊數量)
就是從磁盤上讀取數據塊的數量,其產生的主要原因是:
(1) 在數據庫高速緩存中不存在這些塊
(2) 全表掃描
(3) 磁盤排序
它們三者之間的關系大致可概括為:
邏輯讀指的是Oracle從內存讀到的數據塊數量。一般來說是'consistent gets' + 'db block gets'。當在內存中找不到所需的數據塊的話就需要從磁盤中獲取,于是就產生了'physical reads'。
Sorts(disk):
Number of sort operations that required at least one disk write. Sorts that require I/O to disk are quite resource intensive. Try increasing the size of the initialization parameter SORT_AREA_SIZE.
bytes sent via SQL*Net to client:
Total number of bytes sent to the client from the foreground processes.
bytes received via SQL*Net from client:
Total number of bytes received from the client over Oracle Net.
SQL*Net roundtrips to/from client:
Total number of Oracle Net messages sent to and received from the client.
更多內容參考Oracle聯機文檔:
Statistics Descriptions
http://download.oracle.com/docs/cd/E11882_01/server.112/e10820/stats002.htm#i375475
3.4 動態分析
如果在執行計劃中有如下提示:
Note
------------
-dynamic sampling used for the statement
這提示用戶CBO當前使用的技術,需要用戶在分析計劃時考慮到這些因素。 當出現這個提示,說明當前表使用了動態采樣。 我們從而推斷這個表可能沒有做過分析。
這里會出現兩種情況:
(1) 如果表沒有做過分析,那么CBO可以通過動態采樣的方式來獲取分析數據,也可以或者正確的執行計劃。
(2) 如果表分析過,但是分析信息過舊,這時CBO就不會在使用動態采樣,而是使用這些舊的分析數據,從而可能導致錯誤的執行計劃。
總結:
在看執行計劃的時候,除了看執行計劃本身,還需要看謂詞和提示信息。 通過整體信息來判斷SQL 效率。
第二章相關文章:
一、什么是執行計劃(explain plan)
執行計劃:一條查詢語句在ORACLE中的執行過程或訪問路徑的描述。
二、如何查看執行計劃
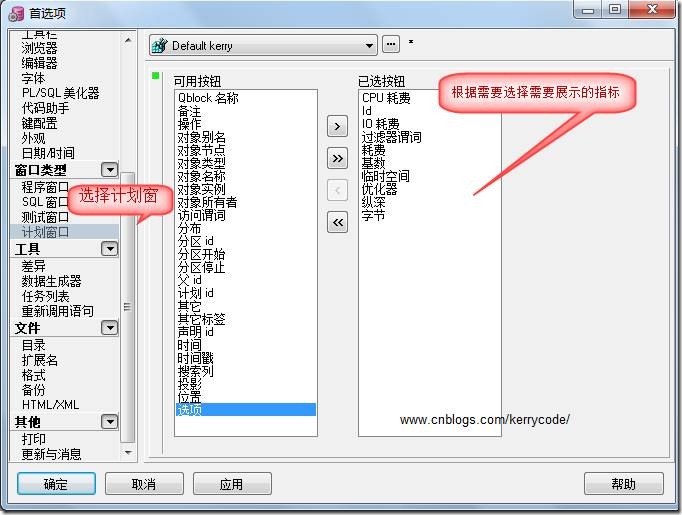
1: 在PL/SQL下按F5查看執行計劃。第三方工具toad等。
很多人以為PL/SQL的執行計劃只能看到基數、優化器、耗費等基本信息,其實這個可以在PL/SQL工具里面設置的。可以看到很多其它信息,如下所示
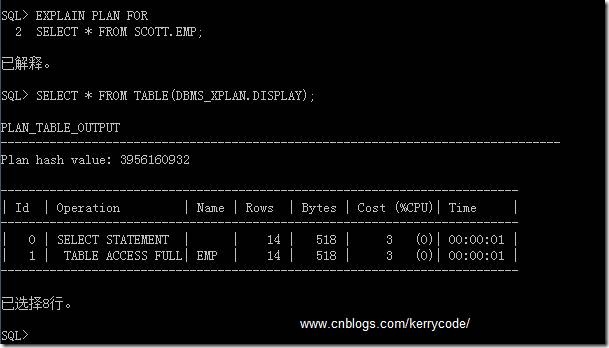
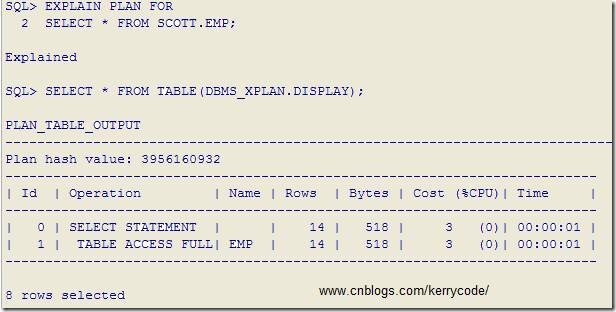
2: 在SQL*PLUS(PL/SQL的命令窗口和SQL窗口均可)下執行下面步驟
復制代碼 代碼如下:
SQL>EXPLAIN PLAN FOR
SELECT * FROM SCOTT.EMP; --要解析的SQL腳本
SQL>SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);
3: 在SQL*PLUS下(有些命令在PL/SQL下無效)執行如下命令:
復制代碼 代碼如下:
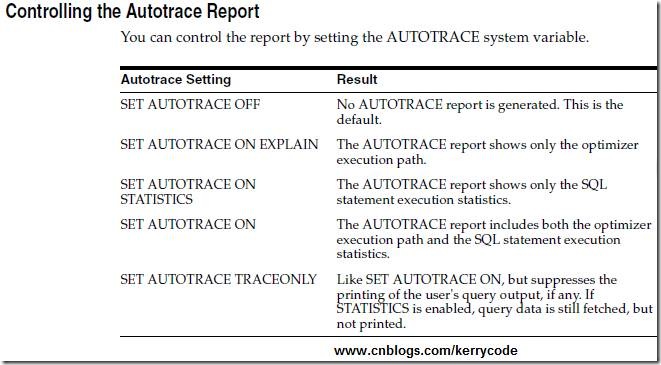
SQL>SET TIMING ON --控制顯示執行時間統計數據
SQL>SET AUTOTRACE ON EXPLAIN --這樣設置包含執行計劃、腳本數據輸出,沒有統計信息
SQL>執行需要查看執行計劃的SQL語句
SQL>SET AUTOTRACE OFF --不生成AUTOTRACE報告,這是缺省模式
SQL> SET AUTOTRACE ON --這樣設置包含執行計劃、統計信息、以及腳本數據輸出
SQL>執行需要查看執行計劃的SQL語句
SQL>SET AUTOTRACE OFF
SQL> SET AUTOTRACE TRACEONLY --這樣設置會有執行計劃、統計信息,不會有腳本數據輸出
SQL>執行需要查看執行計劃的SQL語句
SQL>SET AUTOTRACE TRACEONLY STAT --這樣設置只包含有統計信息
SQL>執行需要查看執行計劃的SQL語句
SET AUTOT[RACE] {ON | OFF | TRACE[ONLY]} [EXP[LAIN]] [STAT[ISTICS]]
參考文檔:SQLPlus User's Guide and Reference Release 11.1
注意:PL/SQL Developer 工具并不完全支持所有的SQL*Plus命令,像SET AUTOTRACE ON 就如此,在PL/SQL Developer工具下執行此命令會報錯
SQL> SET AUTOTRACE ON;
Cannot SET AUTOTRACE
4:SQL_TRACE可以作為參數在全局啟用,也可以通過命令形式在具體SESSION啟用
4.1 在全局啟用,在參數文件(pfile/spfile)中指定SQL_TRACE =true,在全局啟用SQL_TRACE時會導致所有進程活動被跟蹤,包括后臺進程以及用戶進程,通常會導致比較嚴重的性能問題,所以在生產環境要謹慎使用。
提示:通過在全局啟用SQL_TRACE, 我們可以跟蹤到所有后臺進程的活動,很多在文檔中的抽象說明,通過跟蹤文件的實時變化,我們可以清晰的看到各個進程間的緊密協調。
4.2在當前SESSION級別設置,通過跟蹤當前進程可以發現當前操作的后臺數據庫遞歸活動(這在研究數據庫新特性時尤其有效),研究SQL執行時,發現后臺
錯誤等。
復制代碼 代碼如下:
SQL> ALTER SESSION SET SQL_TRACE=TRUE;
SQL> SELECT * FROM SCOTT.EMP;
SQL> ALTER SESSION SET SQL_TRACE =FALSE;
那么此時如何查看相關信息?不管你在SQL*PLUS抑或PL/SQL DEVELOPER工具里面執行上面腳本過后都看不到什么信息,你可以通過下面腳本查詢到trace日志信息
復制代碼 代碼如下:
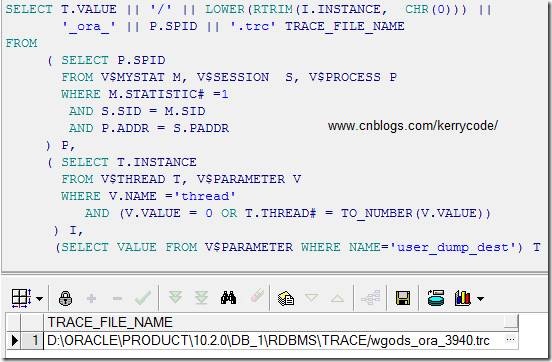
SELECT T.VALUE || '/' || LOWER(RTRIM(I.INSTANCE, CHR(0))) || '_ora_' ||
P.SPID || '.trc' TRACE_FILE_NAME
FROM
( SELECT P.SPID
FROM V$MYSTAT M, V$SESSION S, V$PROCESS P
WHERE M.STATISTIC# =1
AND S.SID = M.SID
AND P.ADDR = S.PADDR
) P,
( SELECT T.INSTANCE
FROM V$THREAD T, V$PARAMETER V
WHERE V.NAME ='thread'
AND (V.VALUE = 0 OR T.THREAD# = TO_NUMBER(V.VALUE))
) I,
(SELECT VALUE FROM V$PARAMETER WHERE NAME='user_dump_dest') T
TKPROF的幫助信息如下
復制代碼 代碼如下:
TKPROF 選項
選項 說明
TRACEFILE 跟蹤輸出文件的名稱
OUTPUTFILE 已設置格式的文件的名稱
SORT=option 語句的排序順序
PRINT=n 打印前 n 個語句
EXPLAIN=user/password 以指定的用戶名運行 EXPLAIN PLAN
INSERT=filename 生成 INSERT 語句
SYS=NO 忽略作為用戶 sys 運行的遞歸 SQL 語句
AGGREGATE=[Y|N] 如果指定 AGGREGATE = NO TKPROF 不聚集相同
SQL 文本的多個用戶
RECORD=filename 記錄在跟蹤文件中發現的語句
TABLE=schema.tablename 將執行計劃放入指定的表而不是缺省的PLAN_TABLE
可以在操作系統中鍵入 tkprof 以獲得所有可用選項和輸出的列表
注 排序選項有
排序 選項說明
prscnt execnt fchcnt 調用分析執行提取的次數
prscpu execpu fchcpu 分析執行提取所占用的 CPU 時間
prsela exela fchela 分析執行提取所占用的時間
prsdsk exedsk fchdsk 分析執行提取期間的磁盤讀取次數
prsqry exeqry fchqry 分析執行提取期間用于持續讀取的緩沖區數
prscu execu fchcu 分析執行提取期間用于當前讀取的緩沖區數
prsmis exemis 分析執行期間庫高速緩存未命中的次數
exerow fchrow 分析執行期間處理的行數
userid 分析游標的用戶的用戶 ID
TKPROF 統計數據
Count: 執行調用數
CPU: CPU 的使用秒數
Elapsed: 總共用去的時間
Disk: 物理讀取次數
Query: 持續讀取的邏輯讀取數
Current: 當前模式下的邏輯讀取數
Rows: 已處理行數
TKPROF 統計信息
統計 含義
Count 分析或執行語句的次數以及為語句發出的提取調用數
CPU 每個階段的處理時間以秒為單位如果在共享池中找到該語句對于分析階段為 0
Elapsed 占用時間以秒為單位通常不是非常有用因為其它進程影響占用時間
Disk 從數據庫文件讀取的物理數據塊如果該數據被緩沖則該統計可能很低
Query 為持續讀取檢索的邏輯緩沖區通常用于 SELECT 語句
Current 在當前模式下檢索的邏輯緩沖區通常用于 DML 語句
Rows 外部語句所處理的行對于 SELECT 語句在提取階段顯示它對于 DML 語句在執行階段顯示它
Query 和Current 的總和為所訪問的邏輯緩沖區的總數
執行下面命令:tkprof D:\ORACLE\PRODUCT\10.2.0\DB_1\RDBMS\TRACE/wgods_ora_3940.trc h:\out.txtoutputfile explain=etl/etl

執行上面命令后,可以查看生成的文本文件
復制代碼 代碼如下:
TKPROF: Release 10.2.0.1.0 - Production on 星期三 5月 23 16:56:41 2012
Copyright (c) 1982, 2005, Oracle. All rights reserved.
Trace file: D:\ORACLE\PRODUCT\10.2.0\DB_1\RDBMS\TRACE/wgods_ora_3940.trc
Sort options: default
********************************************************************************
count = number of times OCI procedure was executed
cpu = cpu time in seconds executing
elapsed = elapsed time in seconds executing
disk = number of physical reads of buffers from disk
query = number of buffers gotten for consistent read
current = number of buffers gotten in current mode (usually for update)
rows = number of rows processed by the fetch or execute call
********************************************************************************
ALTER SESSION SET SQL_TRACE = TRUE
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 0 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 1 0.00 0.00 0 0 0 0
Misses in library cache during parse: 0
Misses in library cache during execute: 1
Optimizer mode: CHOOSE
Parsing user id: 89 (ETL)
********************************************************************************
begin :id := sys.dbms_transaction.local_transaction_id; end;
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 2 0.00 0.00 0 0 0 0
Execute 2 0.00 0.00 0 0 0 2
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.00 0.00 0 0 0 2
Misses in library cache during parse: 0
Optimizer mode: CHOOSE
Parsing user id: 89 (ETL)
********************************************************************************
SELECT *
FROM
SCOTT.EMP
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 2 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1 0.00 0.00 0 7 0 14
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.00 0.00 0 7 0 14
Misses in library cache during parse: 1
Optimizer mode: CHOOSE
Parsing user id: 89 (ETL)
Rows Execution Plan
------- ---------------------------------------------------
SELECT STATEMENT MODE: CHOOSE
TABLE ACCESS MODE: ANALYZED (FULL) OF 'EMP' (TABLE)
********************************************************************************
ALTER SESSION SET SQL_TRACE = FALSE
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 2 0.00 0.00 0 0 0 0
Misses in library cache during parse: 1
Optimizer mode: CHOOSE
Parsing user id: 89 (ETL)
********************************************************************************
OVERALL TOTALS FOR ALL NON-RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 5 0.00 0.00 0 0 0 0
Execute 5 0.00 0.00 0 0 0 2
Fetch 1 0.00 0.00 0 7 0 14
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 11 0.00 0.00 0 7 0 16
Misses in library cache during parse: 2
Misses in library cache during execute: 1
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 0 0.00 0.00 0 0 0 0
Execute 0 0.00 0.00 0 0 0 0
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 0 0.00 0.00 0 0 0 0
Misses in library cache during parse: 0
user SQL statements in session.
internal SQL statements in session.
SQL statements in session.
statement EXPLAINed in this session.
********************************************************************************
Trace file: D:\ORACLE\PRODUCT\10.2.0\DB_1\RDBMS\TRACE/wgods_ora_3940.trc
Trace file compatibility: 10.01.00
Sort options: default
session in tracefile.
user SQL statements in trace file.
internal SQL statements in trace file.
SQL statements in trace file.
unique SQL statements in trace file.
SQL statements EXPLAINed using schema:
ETL.prof$plan_table
Default table was used.
Table was created.
Table was dropped.
lines in trace file.
elapsed seconds in trace file.
4.3跟蹤其它用戶的進程,在很多時候我們需要跟蹤其它用戶的進程,而不是當前用戶,可以通過ORACLE提供的系統包
DBMS_SYSTEM.SET_SQL_TRACE_IN_SESSION來完成。
例如:
復制代碼 代碼如下:
SELECT SID, SERIAL#, USERNAME FROM V$SESSION WHERE USERNAME = 'ETL'
EXEC DBMS_SYSTEM.SET_SQL_TRACE_IN_SESSION(61,76,TRUE);
EXEC DBMS_SYSTEM.SET_SQL_TRACE_IN_SESSION(61,76,FALSE);
5 利用10046事件
復制代碼 代碼如下:
ALTER SESSION SET TRACEFILE_IDENTIFIER = 10046;
ALTER SESSION SET EVENTS='10046 trace name context forever, level 8';
SELECT * FROM SCOTT.EMP;
ALTER SESSION SET EVENTS ='10046 trace name context off';
然后你可以用腳本查看追蹤文件的位置
SELECT T.VALUE || '/' || LOWER(RTRIM(I.INSTANCE, CHR(0))) || '_ora_' ||
P.SPID || '.trc' TRACE_FILE_NAME
FROM
( SELECT P.SPID
FROM V$MYSTAT M, V$SESSION S, V$PROCESS P
WHERE M.STATISTIC# =1
AND S.SID = M.SID
AND P.ADDR = S.PADDR
) P,
( SELECT T.INSTANCE
FROM V$THREAD T, V$PARAMETER V
WHERE V.NAME ='thread'
AND (V.VALUE = 0 OR T.THREAD# = TO_NUMBER(V.VALUE))
) I,
(SELECT VALUE FROM V$PARAMETER WHERE NAME='user_dump_dest') T
查詢結果為wgods_ora_28279.trc文件, 但是去相應目錄卻沒有找到對應的追蹤文件,而是如下trace文件:wgods_ora_28279_10046.trc
6 利用10053事件
有點類似10046,在此略過、
7 系統視圖
通過下面一些系統視圖,你可以看到一些零散的執行計劃的相關信息,有興趣的話可以多去研究一下。
復制代碼 代碼如下:
SELECT * FROM V$SQL_PLAN
SELECT * FROM V$RSRC_PLAN_CPU_MTH
SELECT * FROM V$SQL_PLAN_STATISTICS
SELECT * FROM V$SQL_PLAN_STATISTICS_ALL
SELECT * FROM V$SQLAREA_PLAN_HASH
SELECT * FROM V$RSRC_PLAN_HISTORY
三、看懂執行計劃
1.執行順序
執行順序的原則是:由上至下,從右向左
由上至下:在執行計劃中一般含有多個節點,相同級別(或并列)的節點,靠上的優先執行,靠下的后執行
從右向左:在某個節點下還存在多個子節點,先從最靠右的子節點開始執行。
當然,你在PL/SQL工具中也可以通過它提供的功能來查看執行順序。如下圖所示:
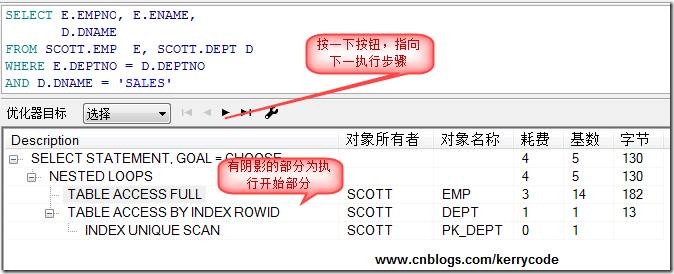
2.執行計劃中字段解釋
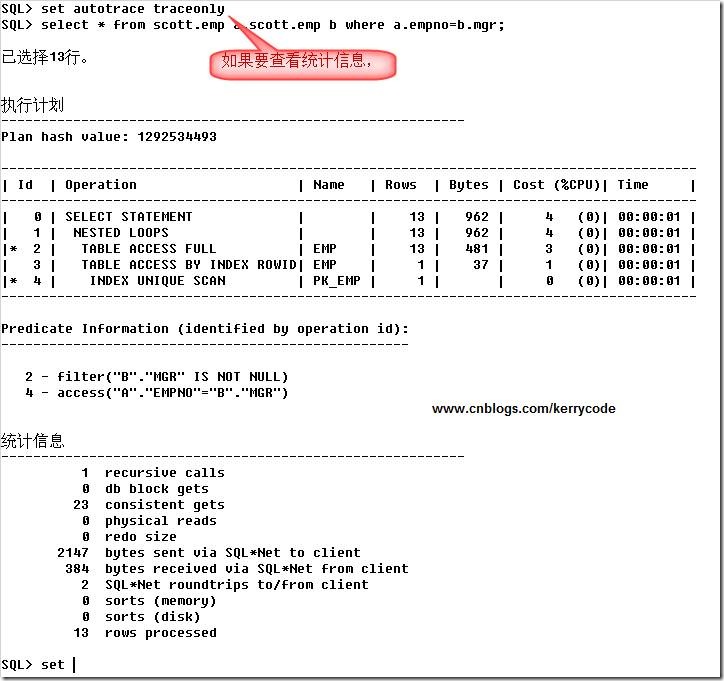
SQL>
名詞解釋:
recursive calls 遞歸調用
db block gets 從buffer cache中讀取的block的數量當前請求的塊數目,當前模式塊意思就是在操作中正好提取的塊數目,而不是在一致性讀的情況下而產生的正常情況下,一個查詢提取的塊是在查詢查詢開始的那個時間點上存在的數據庫,當前塊是在這個時候存在數據塊,而不是這個時間點之前或者之后的的數據塊數目。
consistent gets 從buffer cache中讀取的undo數據的block的數量數據請求總數在回滾段Buffer中的數據一致性讀所需要的數據塊,,這里的概念是在你處理你這個操作的時侯需要在一致性讀狀態上處理多個塊,這些塊產生的主要原因是因為你在查詢過程中,由于其它會話對數據 塊進行操作,而對所要查詢的塊有了修改,但是由于我們的查詢是在這些修改之前調用的,所要需要對回滾 段中的數據塊的前映像進行查詢,以保證數據的一致性。這樣就產生了一致性讀。
physical reads 物理讀 就是從磁盤上讀取數據塊的數量。其產生的主要原因是:
1:在數據庫高速緩存中不存在這些塊。
2:全表掃描
3:磁盤排序
redo size DML生成的redo的大小
sorts (memory) 在內存執行的排序量
sorts (disk) 在磁盤執行的排序量
2091 bytes sent via SQL*Net to client 從SQL*Net向客戶端發送了2091字節的數據
416 bytes received via SQL*Net from client 客戶端向SQL*Net發送了416字節的數據。
參考文檔:SQLPlus User's Guide and Reference Release 11.1
db block gets 、 consistent gets 、 physical reads這三者的關系可以概括為:邏輯讀指的是ORACLE從內存讀到的數據塊塊數量,一般來說是:
consistent gets + db block gets. 當在內存中找不到所需要的數據塊的話,就需要從磁盤中獲取,于是就產生了物理讀。
3.具體內容查看
1> Plan hash Value
這一行是這一條語句的的hash值,我們知道ORACLE對每一條ORACLE語句產生的執行計劃放在SHARE POOL里面,第一次要經過硬解析,產生hash值。下次再執行時比較hash值,如果相同就不會執行硬解析。
2> COST
COST沒有單位,是一個相對值,是SQL以CBO方式解析執行計劃時,供ORACLE來評估CBO成本,選擇執行計劃用的。沒有明確的含義,但是在對比是就非常有用。
公式:COST=(Single Block I/O COST + MultiBlock I/O Cost + CPU Cost)/ Sreadtim
3> 對上面執行計劃列字段的解釋:
Id: 執行序列,但不是執行的先后順序。執行的先后根據Operation縮進來判斷(采用最右最上最先執行的原則看層次關系,在同一級如果某個動作沒有子ID就最先執行。一般按縮進長度來判斷,縮進最大的最先執行,如果有2行縮進一樣,那么就先執行上面的。)
Operation:當前操作的內容。
Name:操作對象
Rows:也就是10g版本以前的Cardinality(基數),Oracle估計當前操作的返回結果集行數。
Bytes:表示執行該步驟后返回的字節數。
Cost(CPU):表示執行到該步驟的一個執行成本,用于說明SQL執行的代價。
Time:Oracle 估計當前操作的時間。
4.謂詞說明:
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("B"."MGR" IS NOT NULL)
4 - access("A"."EMPNO" = "B"."MGR")
Access: 表示這個謂詞條件的值將會影響數據的訪問路勁(全表掃描還是索引)。
Filter:表示謂詞條件的值不會影響數據的訪問路勁,只起過濾的作用。
在謂詞中主要注意access,要考慮謂詞的條件,使用的訪問路徑是否正確。
5、 動態分析
如果在執行計劃中有如下提示:
Note
------------
-dynamic sampling used for the statement
這提示用戶CBO當前使用的技術,需要用戶在分析計劃時考慮到這些因素。 當出現這個提示,說明當前表使用了動態采樣。我們從而推斷這個表可能沒有做過分析。
這里會出現兩種情況:
(1) 如果表沒有做過分析,那么CBO可以通過動態采樣的方式來獲取分析數據,也可以或者正確的執行計劃。
(2) 如果表分析過,但是分析信息過舊,這時CBO就不會在使用動態采樣,而是使用這些舊的分析數據,從而可能導致錯誤的執行計劃。
四、表訪問方式
1.Full Table Scan (FTS) 全表掃描
2.Index Lookup 索引掃描
There are 5 methods of index lookup:
index unique scan --索引唯一掃描
通過唯一索引查找一個數值經常返回單個ROWID,如果存在UNIQUE或PRIMARY KEY約束(它保證了語句只存取單行的話),ORACLE
經常實現唯一性掃描
Method for looking up a single key value via a unique index. always returns a single value, You must supply AT LEAST the leading column of the index to access data via the index.
index range scan --索引局部掃描
Index range scan is a method for accessing a range values of a particular column. AT LEAST the leading column of the index must be supplied to access data via the index. Can be used for range operations (e.g. > < <> >= <= between) .
使用一個索引存取多行數據,在唯一索引上使用索引范圍掃描的典型情況是在謂詞(WHERE 限制條件)中使用了范圍操作符號(如>, < <>, >=, <=,BWTEEN)
index full scan --索引全局掃描
Full index scans are only available in the CBO as otherwise we are unable to determine whether a full scan would be a good idea or not. We choose an index Full Scan when we have statistics that indicate that it is going to be more efficient than a Full table scan and a sort. For example we may do a Full index scan when we do an unbounded scan of an index and want the data to be ordered in the index order.
index fast full scan --索引快速全局掃描,不帶order by情況下常發生
Scans all the block in the index, Rows are not returned in sorted order, Introduced in 7.3 and requires V733_PLANS_ENABLED=TRUE and CBO, may be hinted using INDEX_FFS hint, uses multiblock i/o, can be executed in parallel, can be used to access second column of concatenated indexes. This is because we are selecting all of the index.
index skip scan --索引跳躍掃描,where條件列是非索引的前提情況下常發生
Index skip scan finds rows even if the column is not the leading column of a concatenated index. It skips the first column(s) during the search.
3.Rowid 物理ID掃描
This is the quickest access method available.Oracle retrieves the specified block and extracts the rows it is interested in. --Rowid掃描是最快的訪問數據方式
上述就是小編為大家分享的怎么進行Oracle 執行計劃的說明了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





