溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
很多同學一定聽說過MariaDB。作為MySQL的重要分支之一,它繼續秉承完全開源的姿態(MySQL也有不少好用功能是收費的喲),被很多大型互聯網企業廣泛使用(如Google、Twitter)。同時,紅帽7(包括CentOS)也將默認數據庫由MySQL更改為MariaDB。在這種情況下,一定要了解一下這個逆生長的MariaDB。
本文,著重介紹MariaDB 10.0 GA版中的非常吸引人的若干特性,方便大家和MySQL進行比較。
1. Feedback插件--不推薦:
a) 開啟方式:my.cnf配置文件的[mysqld]模塊,加入feedback=on
b) 作用:會發送使用數據給開發人員,幫助其優化代碼。
2. InnoDB和XtraDB轉換:
a) MDB默認使用XtraDB。
b) 開啟方式:
1) 停止mysql服務。
2) 在my.cnf配置文件的[mysqld]模塊,加入ignore_builtin_innodb、
plugin_load=innodb=ha_innodb.so
3. MYSQL客戶端報告:
a) 控制參數:global.progress_report_time 值范圍要大于5.單位秒。5以下的值被忽略。
b) 關閉的方法:
1) 啟動服務時加入--disable-progress-reports
2) 設置global.progress_report_time 值等于0.
c) MariaDB附帶的mytop腳本一樣也支持此功能
4. SHOW EXPLAIN FOR query_id:Explain命令的變種。
可以在得知QID的情況下查詢執行計劃。
5. LIMIT ROWS EXAMINED:LIMIT命令的進化版本。
語法:LIMIT [m] ROWS EXAMINED n (m可選)
作用:普通的LIMIT語句在查詢到指定數量的分頁結果后還會繼續執行。如果是大表的話這樣的分頁操作會消耗過多的資源。
舉例:LIMIT 100 ROWS EXAMINED 10000 將從一個含有10000條記錄的分頁中再次篩選出前100條記錄。
6. INSTALL SONAME:安裝指定插件、引擎。INSTALL PLUGIN命令變種。
語法:INSTALL SONAME engine_name.
舉例:安裝BLACKHOLE引擎。
INSTALL SONAME ‘ha_blackhole’;
INSTALL PLUGIN Blackhole SONAME ‘ha_blackhole’;
卸載某插件使用UNINSTALL替換INSTALL
7. 生成HTML/XML文件:
舉例:mysql --html/--xml isfdb < isfdb-001.sql > isfdb-001.html/ isfdb-001.xml
會將isfdb-001.sql中的查詢語句返回的結果生成相應的html或者xml文件。
8. MYISAM引擎轉換為ARIA引擎:
ARIA引擎與MYISAM引擎的主要區別是ARIA引擎自帶crash safe功能,在災難性斷電或其他意想不到的表錯誤導致的表損壞時,可以恢復數據。
使用ALTER TABLE命令轉換引擎。
轉換引擎操作步驟和MYSQL一致:
a) 首先創建新表
b) 導入數據
c) Rename操作
因此對于千萬級的大表來說這一過程將相當漫長。建議不要在生產數據庫上進行此操作。
9. 控制MariaDB查詢優化器策略:
a) 查看當前查詢優化器中的優化策略狀態:
SELECT @@optimizer_switch\G
開啟或關閉某個優化策略:
如:SET [GLOBAL] optimizer_switch="mrr=on";
或者在my.cnf配置文件中的[mysqld]模塊中添加:
[mysqld]
optimizer_switch = "mrr=on, mrr_cost_based=on,mrr_sort_keys=on"
b) 在INNODB和XTRADB上打開優化器extended keys策略:
1) 打開方法如上文所示,參數名為:extended_keys=on
2) 作用:由于優化器是基于成本的(CBO),因此執行計劃中會出現有很多索引但是優化器無法使用的查詢。打開優化器extended keys策略將會使優化器在出現這一情況時,盡量使用索引來返回,而不是掃描全表。
10. 配置Aria引擎兩步死鎖監測:
a) 原理:
當Aria引擎無法在表上創建鎖時,它首先會依據deadlock_search_depth_short的值為可能出現的死鎖創建一個深度搜索等待圖(WFG)。當搜索結束后如果還無法創建鎖,那么Aria引擎并不急著判斷出死鎖,而是會等待deadlock_timeout_short定義的微秒后,再搜索一遍。如果還是無法創建鎖,那么Aria引擎會使用deadlock_search_depth_long參數的值,創建一個深度搜索等待圖。當搜索結束后,如果還沒有定義死鎖,那么Aria引擎將等待deadlock_timeout_long定義的微秒后,返回超時錯誤。
b) 查看當前設置:SHOW VARIABLES LIKE ‘deadlock_%’\G
c) 修改參數值,如:

d) 或寫入配置文件my.cnf的[mysqld]模塊中。
e) 注意:上述timeout參數中的單位是微秒。
11. 配置MYISAM引擎鍵緩存段(key_cache_segments):
作用:增強MYISAM引擎表性能。高并發環境中提高MYISAM引擎性能。
a) 原理:
當MYISAM引擎的線程使用鍵緩存時(key cache),線程將首先獲得一把鎖。在高并發場景中,大量的線程同時申請鎖。對大表或者熱點表來說,完整的鍵緩存會成為性能瓶頸。分割后的鍵緩存可以減少鎖競爭,獲得鎖的線程只需要鎖定相應的鍵緩存段就可以了,無需鎖定整個鍵緩存。
b) 查看當前設置:SHOW VARIABLES LIKE ‘key_cache_segments’\G
c) 修改參數值:
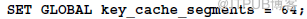
d) 或寫入配置文件my.cnf的[mysqld]模塊中。
12. 配置線程池(重中之重啊,核心功能啊):
MariaDB的線程池提供了更強大的將線程集中使用的功能。并替換了mysql之前的one tread per client connection方法。該方法在典型的web壓力場景(數量多但是返回結果小的場景)中對線程的復用效果并不理想。
a) 修改參數值:
在my.cnf中的[mysqld]模塊中添加thread_handling = pool-of-threads。
b) 重啟服務
c) 作用:
生產場景中出現大量的短查詢或者CPUload過高時,線程池是處理這一問題的最好方案。但是在短時間出現的大量長查詢時,就不適用了。通常這種情況,linux下可以使用thread_pool_idle_timeout參數來緩解壓力。
d) 其他重要的參數:
1) thread_pool_stall_limit:單位毫秒。
用于出現大量長連接查詢,該參數控制線程被stall的時間。默認值500。如果查詢已經被stall,MDB將創建一個新線程,線程池中的最大線程數由thread_pool_max_threads參數控制。默認值500。當線程池中的線程數達到最大值后,將不會在創建新線程,即使線程已經被stall。
這一情況可以使用參數extra_port來解決。該參數將打開一個額外的端口,來保持查詢進行連接。該參數的值必須和默認端口不同。
2) thread_pool_idle_timeout:單位秒。
定義線程在撤銷之前的等待時間。默認值60.
如果發現在某線程被撤銷后會定期的創建新的線程,那么應當增加該參數的值。
3) thread_pool_size:LINUX平臺定義線程池大小。
13. 配置Aria引擎pagecache:
Aria引擎的PAGE是row format型。它的pagecache由三個參數控制:

a) aria_pagecache_buffer_size:單位byte。默認值128M-512M。
該參數不能動態修改。
b) aria_pagecache_age_threshold:定義在pagecache中的數據塊留存長度。
c) aria_pagecache_division_limit:單位百分比。定義pagecache中溫數據所占的百分比。
14. 使用子查詢緩存(subquery cache)優化查詢:MariaDB獨占功能!
a) subquery cache極大提升子查詢性能。
b) 默認開啟.
c) 兩個狀態值變量:
1) subquery_cache_hit:子查詢緩存命中次數
2) subquery_cache_miss:未命中次數
15. 優化半連接子查詢(semijoin query):
半連接子查詢中常見的是帶where條件的IN子句。這種子句在MYSQL中是很難被優化的。而MDB提供了一個可以開啟的優化器參數,指導優化器對這種類型的查詢進行優化。
a) 參數:exists_to_in=on。默認不開啟。
b) 對EXISTS 型的查詢也可以起到優化作用。
c) 修改參數值:
1) SET optimizer_switch='exists_to_in=on';
2) 或者修改配置文件:
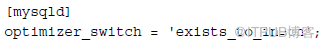
16. 創建全文索引(full-text index)--不推薦:
a) full-text index是一個特殊類型的索引,用來搜索基于text類型的列.
b) 只可以為char, varchar, text類型創建全文索引.
c) 全文索引允許我們使用"MATCH() ... AGAINST"語法來查詢數據.
語法的MATCH部分包含一個以逗號分隔的待查詢columns列表.
語法的AGAINST部分包含需要搜索的字符串也包含一個可選的修飾符來表明所執行查詢的類型.
查詢類型有:
IN NATURAL LANGUAGE MODE, IN BOOLEAN MODE, WITH QUERY EXPANSION
默認類型為: IN NATURAL LANGUAGE MODE.
17. 開啟用戶統計:
a) 修改配置文件:
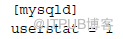
b) 或SET GLOBAL USERSTAT = 1;
c) 開啟后可以查看統計數據。如:
SHOW INDEX_STATISTICS;
18. 使用全局事務ID(global transaction IDs):
更直觀的全局事務。比5.6逗比般的GTID更容易理解。
a) 全局事務ID(GTID)是在10.0.2版本中新添加的特性,它將使復制機能更穩定、更靈活。這里需要注意的是:MariaDB和MYSQL 5.6中提到的GTID不能通用,而且差別較大。
b) GTID信息的存放位置在mysql.gtid_slave_pos表,在更新數據的同一事務中更新此表的最新位置信息。
c) GTID的組成:0-1-12345
1) 第一位是domain ID。這是由MariaDB特有的多源復制場景決定的。是32位的無符號整型。單源場景下,該值為0.domain id 的值在my.cnf中設定,如gtid-domain-id = 1。
2) 第二位是server_id。是32位的無符號整型。
3) 第三位是Commit_id。是64位的無符號整型。事務在master提交階段指定的提交id號,這是一個遞增的值,每次提交都不一樣,而在group commit中所有被group的事務所指定的commit id都是相同的。
d) 默認開啟,查看GTID的值使用show binlog events命令,結果如下所示:
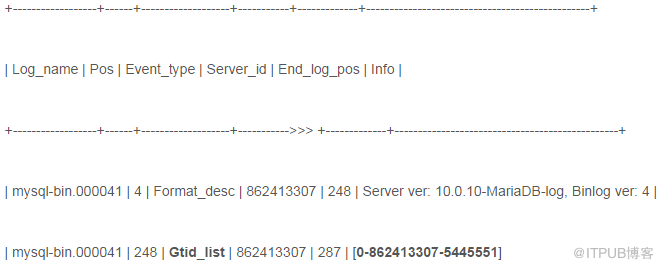
GTID_LIST列中的值就是GTID。
其實值為[]。
查看從庫的當前GTID 值,使用命令 SELECT @@global.gtid_slave_pos,主庫上返回空值。
查看master的當前gtid值,使用命令 select @@global.gtid_current_pos;
e) 從庫采用gtid的復制,語法為:CHANGE MASTER TO master_use_gtid = { slave_pos | current_pos | no }
f) 在一般的復制場景中,從庫使用的是slave_pos的值。如A是B的主庫,當A掛掉后B充當主庫,A重新上線后想要做B的從庫時,使用的是current_pos值。因為A之前是主庫,沒有做過從庫,所以不存在slave_pos值。注:沒有做過從庫的主庫沒有slave_pos
如果之前的從庫沒有開啟binlog,那么current_pos和slave_pos的值是相等的。
g) 可以使用set global gtid_slave_pos= ‘XXXX’修改slave_pos的值。
查詢slave_pos和current_pos:
select @@global.gtid_slave_pos / gtid_current_pos
h) 實測主庫在不停寫入時崩潰,當主庫重新上線后,從庫可以根據slave_pos追上主庫。
i) 理解current_pos和slave_pos概念:
Current_pos:值由主庫操作決定。當機器開啟binlog,在執行事務時就會記錄該值。使用select @@gtid_current_pos中展示的是所有的pos值。
Slave_pos: 從庫上的該值與current_pos一致。使用select @@gtid_current_pos中展示的是本機復制到的GTID。
19. 多源復制:
a) 多源復制中應當注意的要點:
1) 各源my.cnf中應當增加relay-log參數,如:relay_log = db01-relay-binlog。格式中建議增加主機名來區分。
2) 不同源的domain-id一定要不同。否則會出現復制失敗。配置domain-id在my.cnf文件中增加gtid-domain-id=n 參數。重啟服務。
3) change master 語法中可以增加源主機名來增加區分,如:
Change master [“connect_name”] to
master_host = ‘xxx.xxx.xxx.xxx’,
master_port=3306,
master_user=’replication’,
master_password=’replication’,
master_use_gtid=current_pos;
注:使用源主機名來做change master后,只能只用start all slaves命令來啟動復制。其余命令也類似。
4) 啟動所有復制:start all slaves;
停止所有復制:stop all slaves;
查看所有連接復制狀態:show all slaves status;
查看某連接復制狀態:show slave [“connect_name”] status;
清空某連接復制狀態:reset slave [“connect_name”];
注意:這里的清空只是將relay_log從1開始重做。不能將復制信息從slave status的展示中清除。
清空某連接復制狀態并從slave status展示中刪除:
reset slave [“connect_name”] ALL
b) 多源復制的引用場景:
1) 將各主庫上的數據整合到一個slave上,方便查詢。
2) 將各主庫的數據整合到一個slave上,方便備份。
20. 增加基于行復制的binlog注釋:
在配置文件中增加binlog_ annotate_row_events參數。會在mysqlbinlog命令查看binlog時,在基于行復制的部分展示SQL語句。
21. 配置binlog事件總和檢查器(binlog event checksum):
a) 作用:用于在文件系統出現故障前快速發現。
b) 參數設置:

也可以通過在my.cnf配置文件中添加參數BINLOG_CHECKSUM開啟。
22. 在復制過程中跳過指定的binlog事件:
a) 參數設置:開啟。
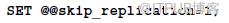
b) 作用:
在開啟功能的這一階段中處理的所有事務都不會被從庫復制。類似的功能還有將binlog功能關閉:set @@sql_log_bin = 0。但是這樣的參數設置會停止所有事務記錄binlog。Skip_replication參數則不會。
Perry.Zhang
02.18.2016
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





