溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!

昨天幫一個朋友看了MySQL數據清理的問題,感覺比較有意思,具體的實施這位朋友還在做,已經差不多了,我就發出來大家一起參考借鑒下。
為了保證信息的敏感,里面的問題描述可能和真實情況不符,但是問題的處理方式是真實的。
首先這位朋友在昨天下午反饋說他有一個表大小是近600G,現在需要清理數據,只保留近幾個月的數據。按照這個量級,我發現這個問題應該不是很好解決,得非常謹慎才對。如果是通用的思路和方法,我建議是使用冷熱數據分離的方式。大體有下面的幾類玩法:
exchange partition,這是亮點的特性,可以把分區數據和表數據交換,效率還不錯。
rename table,這是MySQL歸檔數據的一大利器,在其他商業數據庫里很難實現。
但是為了保險起見,我說還是得看看表結構再說。結果看到表結構,我發現這個問題和我預想的完全不一樣。
這個表的ibd文件大概是600G,不是分區表,InnoDB存儲引擎。字段看起來也不多。需要根據時間字段update_time抽取時間字段來刪除數據。
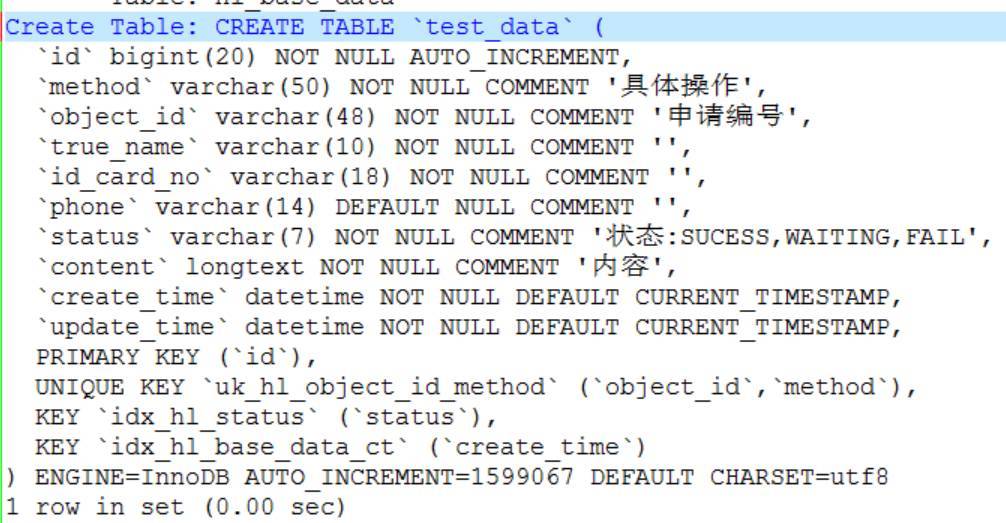
我看了下這個表結構,字段不多,除了索引的設計上有些冗余外,直接看不到其他的問題,但是根據數據的存儲情況來看,我發現這個問題有些奇怪。不知道大家發現問題沒有。
這個表的主鍵是基于字段id,而且是主鍵自增,這樣來看,如果要存儲600G的數據,表里的數據量至少得是億級別。但是大家再仔細看看自增列的值,會發現只有150萬左右。這個差別也實在太大了。
為了進一步驗證,我讓朋友查詢一下這個表的數據量,早上的時候他發給了我最新的數據,一看更加驗證了我的猜想。
mysql> select max(Id) from test_data;
+---------+
| max(Id) |
+---------+
| 1603474 |
+---------+
1 row in set (0.00 sec)
現在的問題很明確,表里的數據不到200萬,但是占用的空間近600G,這個存儲比例也實在太高了,或者說碎片也實在太多了吧。
按照這個思路來想,自己還有些成就感,發現這么大的一個問題癥結,如果數據沒有特別的存儲,200萬的數據其實也不算大,清理起來還是很容易的。
朋友聽了下覺得也有道理,從安全的角度來說,只是需要注意一些技巧而已,但是沒過多久,他給我反饋,說表里的數據除過碎片,大概也有100多G,可能還有更多。這個問題和我之前的分析還是有一些沖突的。至少差別沒有這么大。200萬的數據量,基本就在1G以內。但是這里卻是100多個G,遠遠超出我的預期。
mysql> select round(sum(data_length+index_length)/1024/1024) as total_mb,
-> round(sum(data_length)/1024/1024) as data_mb,
-> round(sum(index_length)/1024/1024) as index_mb
-> from information_schema.tables where table_name='hl_base_data';
+----------+---------+----------+
| total_mb | data_mb | index_mb |
+----------+---------+----------+
| 139202 | 139156 | 47 |
+----------+---------+----------+
1 row in set (0.00 sec)
這個問題接下來該怎么解釋呢。我給這位朋友說,作為DBA,不光要對物理的操作要熟練,還要對數據需要保持敏感。
怎么理解呢,update_time沒有索引,id是主鍵,我們完全可以估算數據的變化情況。
怎么估算呢,如果大家觀察仔細,會發現兩次提供的信息相差近半天,自增利的值相差是大概4000左右。一天的數據變化基本是1萬。
現在距離10月1日已經有24天了,就可以直接估算出數據大概是在1363474附近。
mysql> select current_date-'20171001';
+-------------------------+
| current_date-'20171001' |
+-------------------------+
| 24 |
+-------------------------+
1 row in set (0.00 sec)
按照這個思路,我提供了語句給朋友,他一檢查,和我初步的估算值差不了太多。
mysql> select id , create_time ,update_time from test_data where id=1363474;
+---------+---------------------+---------------------+
| id | create_time | update_time |
+---------+---------------------+---------------------+
| 1363474 | 2017-09-29 10:37:29 | 2017-09-29 10:37:29 |
+---------+---------------------+---------------------+
1 row in set (0.07 sec)
簡單調整一下,就可以完全按照id來過濾數據來刪除數據了,這個過程還是建議做到批量的刪除,小步快進 。
前提還是做好備份,然后慢慢自動化完成。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





