oracle btree索引概述
今天研究下oracle的btree索引,通過這篇文章你會了解到,oracle btree索引都有哪幾種類型、oracle btree索引的實現原理,oracle通過btree索引檢索數據的過程、以及b*tree索引的限制,并且oracle和
mysql的btree索引的區別。
一:oracle中 btree索引的子類型:
b*tree索引是oracle乃至大部分其他數據庫中最常用的索引,b*tree的構造類似于二叉樹,但是這里的“B”不代表二叉(binary),而代表平衡(balanced),b*tree索引有以下子類型:
1)索引組織表(index organized table): 索引組織表以B*樹結構存儲,我們知道oracle默認的表是是堆表,堆表是以一種無組織的方式存儲的(只要有可用的空間,就可以放數據),而IOT與之不同,IOT中的數據按著主鍵的順序存儲和排序的,對于應用來說,IOT表現得和常規的堆表并無區別,需要使用sql來正確的來訪問IOT, IOT對信息獲取、空間系統和OLAP應用最為有用,簡單的概述起來:索引組織表----索引就是數據,數據就是索引,因為數據就是按著B*樹結構存儲的。
2)b*tree聚簇索引(B*tree cluster index):基于聚簇鍵(如 age=27),在傳統的btree索引中,鍵都指向一行,而B*樹聚簇不同,一個聚簇鍵會指向一個塊,其中包含與這個聚簇鍵相關的多行,
3)降序索引:允許數據在索引結構中按“從大到小”的順序(降序)排序,而不是“從小到大的順序(升序)排序,當你查詢數據的時候,最后排序oder by A desc,B asc的時候,創建降序索引就能避免做昂貴的排序(sort order by )操作,如下語句創建:
SQL>create index idex_name on table_name(A desc,B asc);
4)反向鍵索引(reverse key index):這也是 btree索引,只不過鍵的字節會“反轉”,利用反向鍵索引,如果索引中填充的是遞增的值,索引條目在索引中可以得到更均勻的分布;主要是解決“右側”索引葉子塊的競爭,比如在一個oracle RAC的環境中,某些列用一個序列值或者時間戳填充,這些列上建立索引就屬于“右側”索引,也就是數據分布的相對比較集中。使用反向索引最大的優點莫過于降低索引葉子塊的爭用,減少索引熱點塊,提高系統性能。
1.反向索引應用場合
1)發現索引葉塊成為熱點塊時使用
通常,使用數據時(常見于批量插入操作)都比較集中在一個連續的數據范圍內,那么在使用正常的索引時就很容易發生索引葉子塊過熱的現象,嚴重時將會導致系統性能下降。
2)在RAC環境中使用
當RAC環境中幾個節點訪問數據的特點是集中和密集,索引熱點塊發生的幾率就會很高。如果系統對范圍檢索要求不是很高的情況下可以考慮使用反向索引技術來提高系統的性能。因此該技術多見于RAC環境,它可以顯著的降低索引塊的爭用。
2.使用反向索引的缺點
由于反向索引結構自身的特點,如果系統中經常使用范圍掃描進行讀取數據的話(例如在where子句中使用“between and”語句或比較運算符“>”“<”等),那么反向索引將不適用,因為此時會出現大量的全表掃描的現象,反而會降低系統的性能。
二:oracle中BTree索引的實現原理:一個經典的BTree索引的結構如下圖:
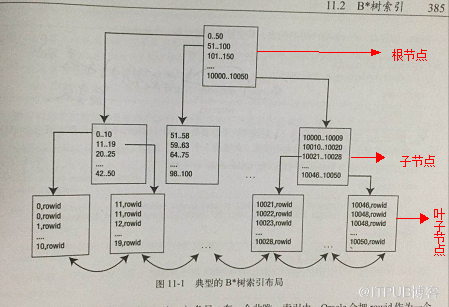
每個節點占用一個磁盤塊的磁盤空間,一個節點上有n個升序排序的關鍵字和(n+1)個指向子樹根節點的指針(上圖中關鍵字為51,101,151.。。。。,然后0到50 對應一個指針,51到100對應一個指針),這個指針存儲的是子節點所在磁盤塊的地址(注意這里的n是創建索引的時候,根據數據量計算出來的,如果數據量太大了,三層的可能就滿足不了,就需要四層的B+tree),然后n個關鍵字劃分成(n+1)個范圍域,然后每個范圍域對應一個指針,來指向子節點,子節點又從新根據關鍵字再次劃分,然后指針指向葉子節點,并且所有的葉子節點都在樹的同一層上,這說明所有的從索引根節點到葉子節點的遍歷都會訪問同樣數目的塊,也就是說會執行同樣數目的I/O,換言之索引是高度平衡的,
上圖就是 0...50對應一個指針,指向一個子節點;51...100對應一個指針,指向另一個子節點,然后子節點又根據關鍵字劃分區域,并由指針指向葉子結點,值得注意的是oracle B*樹索引存數據的是葉子節點(或者叫葉子塊);存的是索引鍵值(或者叫索引的列值)和一個rowid(指向所索引的行的一個指針或者說叫物理位置),然后如上圖所示,葉子節點之間有雙向鏈表,就是為了提高索引范圍掃描的效率,因為索引值的列值是有序的,找到了起始值后,直接就可以有序的去相鄰中找到下一個值,例如 where id between 10 and 20 ,oracle 發現第一個最小鍵值大于或等于10的索引葉子塊,然后水平地遍歷葉子節點鏈表,直到最后一個大于20的值;
需要注意的是:B*索引中不存在非唯一限制,也就是說非唯一列上也可以創建B*索引,但是在一個非唯一索引中,oracle會把rowid作為一個額外的列(有一個長度字節)追加到鍵上,使得鍵唯一,例如有一個create index index_name on table( x ,y)索引,從概念上說,他就是create unique index index_name on table( x ,y,rowid).在一個唯一索引中,根據你定義的唯一性,oracle 不會再向索引鍵增加rowid,在非唯一索引中,你會發現,數據會首先按索引鍵值排序,然后按rowid升序排序,而在唯一索引中,數據只按著索引鍵值排序;
三:使用B*樹索引檢索數據的過程。
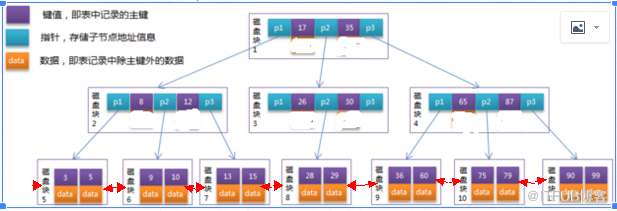
針對下圖B+tree索引的原理(修改自網絡):
然后針對上圖模擬下 where id=29的具體過程:。
首先根據根節點找到磁盤塊1,讀入內存。【磁盤I/O操作第1次】
比較關鍵字29在區間(17,35),找到磁盤塊1的指針P2。
根據P2指針找到磁盤塊3,讀入內存。【磁盤I/O操作第2次】
比較關鍵字29在區間(26,30),找到磁盤塊3的指針P2。
根據P2指針找到磁盤塊8,讀入內存。【磁盤I/O操作第3次】
在磁盤塊8中的關鍵字列表中找到關鍵字29。
分析上面過程,發現需要3次磁盤I/O操作,和3次內存查找操作。由于內存中的關鍵字是一個有序表結構,可以利用二分法查找提高效率。而3次磁盤I/O操作是影響整個B-Tree查找效率的決定因素。
四:oracleb*tree索引的限制
1)在索引列上使用函數。如SUBSTR,DECODE,INSTR等,對索引列進行運算.需要建立函數索引就可以解決了。
例如:表dept,有col_1,col_2,現在對col_1做upper函數索引 如下:
CREATE INDEX index_name ON dept(upper(col_1));
函數索引是基于代價的優化方式-CBO,(在Oracle8及以后的版本,Oracle強列推薦用CBO的方式,而非RBO),所以表必須經過analyze才可以使用,或者使用hints才可以 ;
2)新建的表還沒來得及生成統計信息,分析一下就好了,我們知道oracle優化器是基于統計信息來判斷執行計劃的,如果統計信息不準確,那么oracle可能會做出不走索引的執行計劃。
3)oracle優化器cbo是基于cost的成本分析,訪問的表過小,使用全表掃描的消耗小于使用索引。
4)使用<>、not in 、not exist,對于這三種情況中大多數情況下認為結果集很大,一般大于5%-15%就不走索引而走全表掃描(FTS)。
5) like "%_" 百分號在前。
6) 單獨引用復合索引里非第一位置的索引列,oracle和mysql一樣,btree索引都是最左匹配原則,當你創建組合索引(A,B,C)相當于創建了(A)、 (A,B)、(A,B,C)三個索引;
7)字符型字段為數字時在where條件里不添加引號,這里oracle內部使用函數做隱士轉換,所以可以歸結為第一類,使用函數導致索引失效,值得注意的是:VARCHAR2->NUMBER的隱式轉換,可以走索引;NUMBER->VARCHAR2的隱式轉換,就導致索引失效了。(VARCHAR2->NUMBER不會讓索引失效,可以理解成轉換為where id = to_number('123')。NUMBER->VARCHAR2會讓索引失效,我猜測是轉換為where to_number(name) = 123)
8)當變量采用的是times變量,而表的字段采用的是date變量時.或相反情況。
9)索引失效(INVALID),可以考慮重建索引,alter index index_name rebuild online;。
10)B-tree索引 is null不會走,is not null會走;
五:oracle和mysql的btree索引的區別
其實oracle和mysql的btree索引結構和原理很相似,只是oracle葉子節點存儲的是鍵值+rowid,mysql的索引葉子結點存儲的內容因存儲引擎不同而不同,還有主鍵索引和二級索引之分如下:
oracle葉子節點存儲的是鍵值+rowid
MyISAM引擎中leaf node存儲的內容:
主鍵索引 :僅僅存儲行指針;
二級索引:僅僅是行指針;
InnoDB引擎中leaf node存儲的內容
主鍵索引 :聚集索引存儲完整的數據(整行數據)(類似于oracle的索引組織表)
二級索引:存儲索引列值+主鍵信息
總結:
索引能提高檢索數據的效率,但是索引的建立必須慎重,對每個索引的必要性都應該經過仔細分析,要有建立的依據。因為太多的索引與不充分、不正確的索引對性能都毫無益處:在表上建立的每個索引都會增加存儲開銷,索引對于插入、刪除、更新操作也會增加處理上的開銷。另外,過多的復合索引,在有單字段索引的情況下,一般都是沒有存在價值的;相反,還會降低數據增加刪除時的性能,特別是對頻繁更新的表來說,負面影響更大。