溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Oracle 11.2.0.3數據庫CJQ進程造成row cache lock等待事件影響job無法停止怎么辦,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
一, 現象描述
某生產系統應用人員反映自己發起的job異常,沒有正常運行,導致相關表無數據,自己嘗試停止job但未成功,也無法重新發起job。
二, 問題分析
job的登錄模式一般為’DBMS_SCHEDULER’,通過PL/SQL工具登錄運行如下語句進行查看
select S.STATUS,
S.INST_ID,
S.SID,
S.PADDR,
S.SQL_ID,
S.SQL_EXEC_START,
S.ACTION,
S.LAST_CALL_ET,
S.BLOCKING_INSTANCE,
S.BLOCKING_SESSION,
S.EVENT,
S.WAIT_CLASS
from v$session S
where module = 'DBMS_SCHEDULER';
查詢到一個被kill的job,狀態為killed,并未釋放,通過下面的語句查詢到spid后,通過登錄后臺kill -9 的方式殺掉了系統進程。
Select p.spid from v$session s,v$processes p where p.addr=s.paddr and s.sid=508
之后讓應用再次發起job,但job依然無法執行,通過后臺發現該job發生了等待事件row cache lock,等待會話為1209,P1值為11,通過下面的語句查看無返回結果,不能定位row cache lock發生在哪里
Select * from v$rowcache where cache#=11;
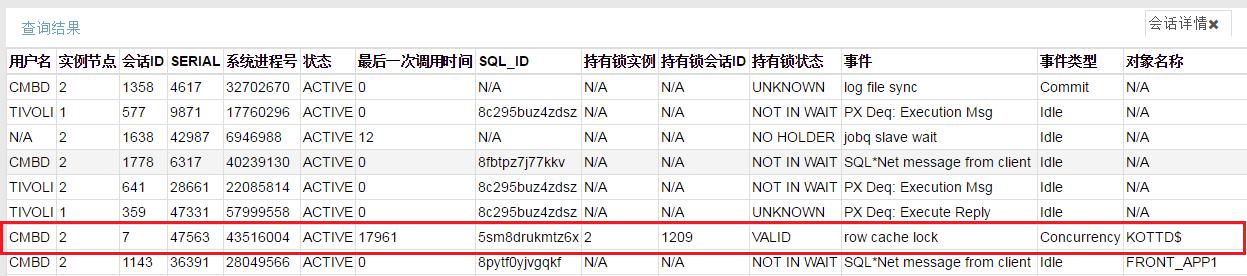
查詢1209會話發現為系統后臺進程CJQ0, CJQn和Jnnn均為為oracle作業隊列進程,后臺進程為什么會鎖正常的job呢?
Select * from v$session where sid=1209;

應用人員通過PL/SQL提供的JOB任務發現存在如下異常現象,

(上面的截圖缺少了任務CSH_BRANCH_D_1DAY,因為截取的是已經處理后的圖像,其實在出現問的時候是有的,只不過忘了截取了)
當前運行很多job,但沒有都沒有session_id,感覺像是僵尸job,既然無法通過會話殺掉job,
我們嘗試通過dbms_scheduler包進行停止,但無法停止,而且依然出現了row cache lock事件,依然被1209后臺進程鎖住。

Row cache lock無法通過P1定位到具體的鎖對象,后臺進程為什么會鎖住job呢,通過上面的結果初步分析是因為之前有很多僵死的job沒有被正常停止,導致再次發起同樣的job任務或對該job進行處理就會出現鎖的情況,而且是被后臺進程CJQn鎖住。
SQL>Show parameter processes
通過查看參數job_queue_processes值為1000,aq_tm_processes為10000,并未達到峰值
進一步分析
登錄后臺通過DEBUG命令收集相關信息分析
用sysdba登錄到數據庫上:
$sqlplus / as sysdba
或者
$sqlplus -prelim / as sysdba <==當數據庫已經很慢或者hang到無法連接
以下為操作截屏,采用的hanganalyze 3,systemstate dump 258級別。
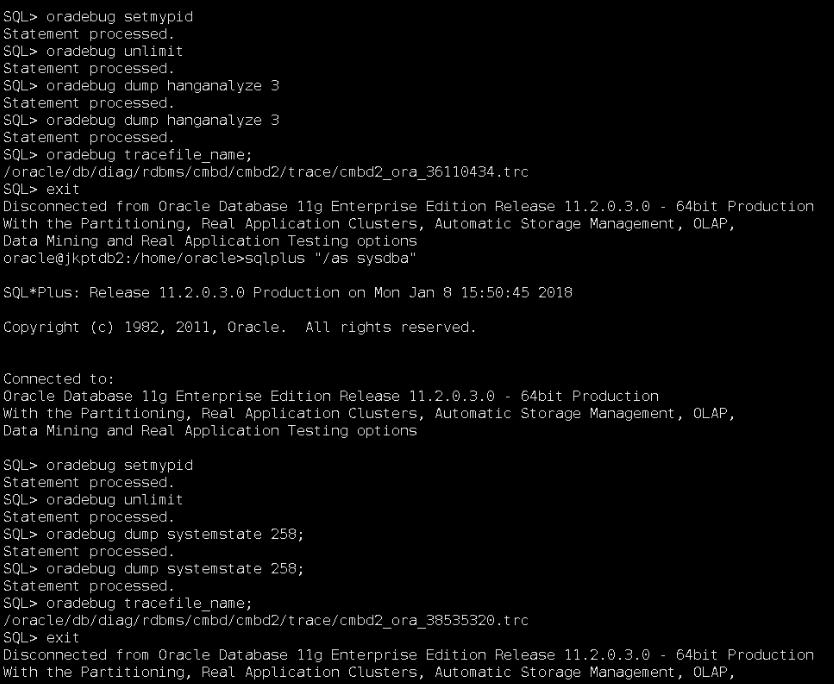
相關說明:
Level 的含義:
1-2:只有hanganalyze輸出,不dump任何進程
3:Level2+Dump出在IN_HANG狀態的進程
4:Level3+Dump出在等待鏈里面的blockers(狀態為LEAF/LEAF_NW/IGN_DMP)
5:Level4+Dump出所有在等待鏈中的進程(狀態為NLEAF)
Oracle官方建議不要超過level 3,一般level 3也能夠解決問題,超過level 3會給系統帶來額外負擔。
systemstate dump有多個級別:
2: dump (不包括lock element)
10: dump
11: dump + global cache of RAC
256: short stack (函數堆棧)
258: 256+2 -->short stack +dump(不包括lock element)
266: 256+10 -->short stack+ dump
267: 256+11 -->short stack+ dump + global cache of RAC
level 11和 267會 dump global cache, 會生成較大的trace 文件,一般情況下不推薦。
一般情況下,如果進程不是太多,推薦用266,因為這樣可以dump出來進程的函數堆棧,可以用來分析進程在執行什么操作。
但是生成short stack比較耗時,如果進程非常多,比如2000個進程,那么可能耗時30分鐘以上。這種情況下,可以生成level 10 或者 level 258, level 258 比 level 10會多收集short short stack, 但比level 10少收集一些lock element data.
以下為hanganalyze的截取輸出,可以看到主要等待為row cache lock,session id:7/porcess id:128被session id:1209/process id: 49鎖住,和上面的分析一致。
Chains most likely to have caused the hang:
[a] Chain 1 Signature: 'rdbms ipc message'<='row cache lock'
Chain 1 Signature Hash: 0xfe4c0898
Chain 1:
-------------------------------------------------------------------------------
Oracle session identified by:
{
instance: 2 (cmbd.cmbd2)
os id: 43516004
process id: 128, oracle@jkptdb2
session id: 7
session serial #: 47563
}
is waiting for 'row cache lock' with wait info:
{
p1: 'cache id'=0xb
p2: 'mode'=0x0
p3: 'request'=0x5
time in wait: 0.077179 sec
heur. time in wait: 16 min 18 sec
timeout after: 2.922821 sec
wait id: 13467
blocking: 0 sessions
wait history:
* time between current wait and wait #1: 0.000045 sec
1. event: 'row cache lock'
time waited: 3.000020 sec
wait id: 13466 p1: 'cache id'=0xb
p2: 'mode'=0x0
p3: 'request'=0x5
* time between wait #1 and #2: 0.000030 sec
2. event: 'row cache lock'
time waited: 3.000016 sec
wait id: 13465 p1: 'cache id'=0xb
p2: 'mode'=0x0
p3: 'request'=0x5
* time between wait #2 and #3: 0.000032 sec
3. event: 'row cache lock'
time waited: 3.000016 sec
wait id: 13464 p1: 'cache id'=0xb
p2: 'mode'=0x0
p3: 'request'=0x5
}
and is blocked by
=> Oracle session identified by:
{
instance: 2 (cmbd.cmbd2)
os id: 19792004
process id: 49, oracle@jkptdb2 (CJQ0)
session id: 1209
session serial #: 9
}
which is waiting for 'rdbms ipc message' with wait info:
{
p1: 'timeout'=0x14
time in wait: 0.168064 sec
heur. time in wait: 2.171697 sec
timeout after: 0.031936 sec
wait id: 72756966
blocking: 1 session
wait history:
* time between current wait and wait #1: 0.000350 sec
1. event: 'rdbms ipc message'
time waited: 0.200014 sec
wait id: 72756965 p1: 'timeout'=0x14
* time between wait #1 and #2: 0.000304 sec
2. event: 'rdbms ipc message'
time waited: 0.200016 sec
wait id: 72756964 p1: 'timeout'=0x14
* time between wait #2 and #3: 0.000307 sec
3. event: 'rdbms ipc message'
time waited: 0.200041 sec
wait id: 72756963 p1: 'timeout'=0x14
}
Chain 1 Signature: 'rdbms ipc message'<='row cache lock'
Chain 1 Signature Hash: 0xfe4c0898
以下為systemstate dump(部分截取信息)輸出如下:
上鎖進程(session id:129):
PROCESS 49: CJQ0
下面的描述大致為:系統進程49,也就是session id 129鎖住一個會話是sid:7,等待事件為row cache lock,和上面的分析吻合。
There are 1 sessions blocked by this session.
Dumping one waiter:
inst: 2, sid: 7, ser: 47563
wait event: 'row cache lock'
p1: 'cache id'=0xb
p2: 'mode'=0x0
p3: 'request'=0x5
row_wait_obj#: 520, block#: 11728, row#: 0, file# 1
min_blocked_time: 0 secs, waiter_cache_ver: 21656
下面可以看到CJQ0進程持有S鎖,而對象正是=CSH_BRANCH_D_1DAY_JOB,也就是我們上面打算停止的job名稱。
kssdmh: so 0x7000001b029ced8 (type 75, "row cache enqueues") may not have children
----------------------------------------
SO: 0x7000001b02dd868, type: 75, owner: 0x700000191e0d808, flag: INIT/-/-/0x00 if: 0x1 c: 0x1
proc=0x7000001aa6dc268, name=row cache enqueues, file=kqr.h LINE:2064 ID:, pg=0
row cache enqueue: count=2 session=7000001adb58460 object=7000001810e7238, mode=S
savepoint=0x351e5fa5
row cache parent object: address=7000001810e7238 cid=11(dc_objects)
hash=af8ef272 typ=21 transaction=0 flags=00000002
objectno=352585 ownerid=57 nsp=1
name=CSH_BRANCH_D_1DAY_JOB own=7000001810e7300[7000001b02dd910,7000001b02dd910] wat=7000001810e7310[7000001b2c1bf00,7000001b2c1bf00] mode=S
status=VALID/-/-/-/-/-/-/-/-
request=N release=FALSE flags=8
instance lock=QI af8ef272 41d157e6
set=0, complete=FALSE
data=
00000039 00154353 485f4252 414e4348 5f445f31 4441595f 4a4f4200 00000000
00000000 01000000 00000000 00000000 00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
被鎖進程(session id:7)
PROCESS 128:
----------------------------------------
Short stack dump:
ksedsts()+360<-ksdxfstk()+44<-ksdxcb()+3384<-sspuser()+116<-47dc<-sskgpwwait()+32<-skgpwwait()+180
<-ksliwat()+11032<-kslwaitctx()+180<-kqrigt()+1424<-kqrLockAndPinPo()+532<-kqrpre1()+864<-kqrpre()+28
<-jskaObjGet()+1024<-jskaJobRun()+2788<-jsiRunJob()+776<-jsaRunJob()+780<-spefcmpa()+600
<-spefmccallstd()+1340<-pextproc()+168<-peftrusted()+164<-psdexsp()+276<-rpiswu2()+480
<-psdextp()+632<-pefccal()+588<-pefcal()+260<-pevm_FCAL()+144<-pfrinstr_FCAL()+96
<-pfrrun_no_tool()+96<-pfrrun()+1032<-plsql_run()+716<-peicnt()+320<-kkxexe()+508
<-opiexe()+17168<-kpoal8()+1856<-opiodr()+720<-ttcpip()+1028<-opitsk()+1508<-opiino()+940
<-opiodr()+720<-opidrv()+1132<-sou2o()+136<-opimai_real()+608<-ssthrdmain()+268
<-main()+204<-__start()+112
當前正在等待事件row cache lock
Current Wait Stack:
0: waiting for 'row cache lock'
cache id=0xb, mode=0x0, request=0x5
wait_id=13602 seq_num=13603 snap_id=1
wait times: snap=0.003162 sec, exc=0.003162 sec, total=0.003162 sec
wait times: max=3.000000 sec, heur=23 min 0 sec
wait counts: calls=1 os=1
in_wait=1 iflags=0x5a2
下面顯示了該進程在請求一個X鎖,請求的對象是正是CSH_BRANCH_D_1DAY_JOB,和上面的分析是溫和的,CJQ進程對 CSH_BRANCH_D_1DAY_JOB持有一個S鎖,而當前的進程需要對CSH_BRANCH_D_1DAY_JOB進程操作,需要一個X鎖。
SO: 0x7000001b2c1be58, type: 75, owner: 0x70000019c72b078, flag: INIT/-/-/0x00 if: 0x1 c: 0x1
proc=0x7000001ab6cb410, name=row cache enqueues, file=kqr.h LINE:2064 ID:, pg=0
row cache enqueue: count=1 session=7000001ab826ce0 object=7000001810e7238, request=X
savepoint=0x893a
row cache parent object: address=7000001810e7238 cid=11(dc_objects)
hash=af8ef272 typ=21 transaction=0 flags=00000002
objectno=352585 ownerid=57 nsp=1
name=CSH_BRANCH_D_1DAY_JOB own=7000001810e7300[7000001b02dd910,7000001b02dd910] wat=7000001810e7310[7000001b2c1bf00,7000001b2c1bf00] mode=S
status=VALID/-/-/-/-/-/-/-/-
request=N release=FALSE flags=8
instance lock=QI af8ef272 41d157e6
set=0, complete=FALSE
data=
00000039 00154353 485f4252 414e4348 5f445f31 4441595f 4a4f4200 00000000
00000000 01000000 00000000 00000000 00000000 00000000 00000000 00000000
011044c6 00000000 07000001 810e7300
下面記錄了操作語句:
begin sys.dbms_scheduler.run_job('CMBD.CSH_BRANCH_D_1DAY_JOB', false); end;
----------------------------------------
SO: 0x70000015d5f35c8, type: 78, owner: 0x7000001ab826ce0, flag: INIT/-/-/0x00 if: 0x3 c: 0x3
proc=0x7000001ab6cb410, name=LIBRARY OBJECT LOCK, file=kgl.h LINE:8548 ID:, pg=0
LibraryObjectLock: Address=70000015d5f35c8 Handle=7000000ba27f998 Mode=N CanBeBrokenCount=1 Incarnation=1 ExecutionCount=1
User=7000001ab826ce0 Session=7000001ab826ce0 ReferenceCount=1 Flags=CNB/[0001] SavepointNum=5a52c6da
LibraryHandle: Address=7000000ba27f998 Hash=a53cfcdd LockMode=N PinMode=0 LoadLockMode=0 Status=VALD
ObjectName:Name=begin sys.dbms_scheduler.run_job('CMBD.CSH_BRANCH_D_1DAY_JOB', false); end;
三,問題定位
通過相關關鍵字row cache lock cjq在metlink搜索查看,最終定位到了一個BUG16994952 –Unable to unscheduled propagation due to CJQ self-deadlock/hang。通過BUG的描述發現和上面的分析吻合。
This note gives a brief overview of bug 16994952.
The content was last updated on: 23-AUG-2015
Click here for details of each of the sections below.
Product (Component) | Oracle Server (Rdbms) |
Range of versions believed to be affected | (Not specified) |
Versions confirmed as being affected | · 11.2.0.3 |
Platforms affected | Generic (all / most platforms affected) |
The fix for 16994952 is first included in | · 12.1.0.1 (Base Release) |
Interim patches may be available for earlier versions - click here to check.
Symptoms: | Related To: |
· Deadlock · Hang (Process Hang) · Waits for "row cache lock" · Stack is likely to include jskaObjGet | · Advanced Queuing · Job Queues |
Unable to unschedule propagation due to CJQ self-deadlock / hang.
Rediscovery Information:
This bug may be the cause if the CJQ0 process is stuck in a
self-deadlock waiting on "row cache lock" for a dc_objects
entry in X mode for an object that it already holds in S mode.
The stack is likely to include jskaObjGet
Workaround:
Kill the hung CJQ process
HOOKS "WAITEVENT:row cache lock" STACKHAS:jskaObjGet WAITEVENT:row cache lock STACKHAS:jskaObjGet LIKELYAFFECTS XAFFECTS_11.2.0.1 XAFFECTS_V11020001 AFFECTS=11.2.0.1 XAFFECTS_11.2.0.2 XAFFECTS_V11020002 AFFECTS=11.2.0.2 XAFFECTS_11.2.0.3 XAFFECTS_V11020003 AFFECTS=11.2.0.3 XAFFECTS_11.2.0.4 XAFFECTS_V11020004 AFFECTS=11.2.0.4 XPRODID_5 PRODUCT_ID=5 PRODID-5 RDBMS XCOMP_RDBMS COMPONENT=RDBMS TAG_AQ TAG_DEADLOCK TAG_HANG TAG_JOBQ AQ DEADLOCK HANG JOBQ FIXED_12.1.0.1 SOLVED_SR=2 SOLVED_SR_BAND_2
Please note: The above is a summary description only. Actual symptoms can vary. Matching to any symptoms here does not confirm that you are encountering this problem. For questions about this bug please consult Oracle Support. |
Bug:16994952 (This link will only work for PUBLISHED bugs)
Note:245840.1 Information on the sections in this article
四,問題處理
Kill the hung CJQ process,殺掉CJQ進程
SQL>Select spid from v$session s,v$process p where p.addr=s.paddr and s.sid=129;
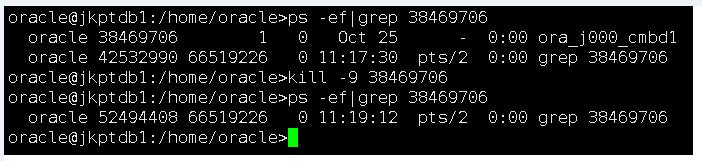
再次通過dbms_scheduler包進行停止,可以正常停止,依次停止僵死的job后,應用可以再次正常發起job,恢復正常。

看完了這篇文章,相信你對“Oracle 11.2.0.3數據庫CJQ進程造成row cache lock等待事件影響job無法停止怎么辦”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





