溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“MySQL性能需要關注的參數有哪些”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
1、innodb_flush_log_at_trx_commit設置為2
這參數是指 事務log 怎樣從log buffer寫進日志文件(ib_logfile0、ib_logfile1)
=0 mysql crash 就丟失了,性能最好
buffer pool -> log buffer 每秒 wirte os cache & flush磁盤
=1 不會丟失,效率低
每次commit,buffer pool -> log buffer—> write os cache & flush磁盤
=2 即使mysql崩潰也不會丟數據
每次commit ,buffer pool -> os cache 然后每秒flush 磁盤
注意:由于進程調度策略問題,這個“每秒執行一次 flush(刷到磁盤)操作”并不是保證100%的“每秒
可以根據業務的安全程度和對性能的要求來具體設置該參數,已經下面的sync_binlog
2、sync_binlog
二進制日志(binary log)同步到磁盤的頻率。binary log 每寫入sync_binlog 次后,刷寫到磁盤。
如果 autocommit 開啟,每個語句都寫一次 binary log,否則每次事務寫一次。
默認值是 0,不主動同步,而依賴操作系統本身不定期把文件內容 flush 到磁盤
設為 1 最安全,在每個語句或事務后同步一次 binary log,即使在崩潰時也最多丟失一個語句或事務的日志,但因此也最慢。
sync_binlog = N: 控制的是從binlog buffer中刷新binlog到底層binlog文件(也就是刷新到底層磁盤)
N>0 每向二進制日志文件寫入N條SQL或N個事務后,則把二進制日志文件的數據刷新到磁盤上;
N=0 不主動刷新二進制日志文件的數據到磁盤上,而是由操作系統決定;
大多數情況下,對數據的一致性并沒有很嚴格的要求,所以并不會把 sync_binlog 配置成 1,為了追求高并發,提升性能,可以設置為 100 或直接用 0
注意 MySQL 5.6開始引入Group Commit后
sync_binlog的含義就變了,假定設為1000,表示的不是1000個事務后做一次fsync,而是1000個事務組。也就是說,當設置sync_binlog=1,binlog還未落盤,此時系統crash,會丟失對應的最后一個事務組;如果這個事務組內有10個事務,那么這10個事務都會丟失。
如何查看是否屬于一個事務組
通過mysqlbinlog可以查看binlog日志中last_committed值,如果值一樣,表明是在同一事務組內。
### INSERT INTO `wukong_test`.`wukong`
### SET
### @1=3 /* INT meta=0 nullable=1 is_null=0 */
### @2='ccccc' /* VARSTRING(80) meta=80 nullable=1 is_null=0 */
# at 496468
#170527 4:17:35 server id 12001 end_log_pos 496499 CRC32 0xd6e7f69f Xid = 5556
COMMIT/*!*/;
# at 496499
#170527 4:17:35 server id 12001 end_log_pos 496564 CRC32 0x28816d5c GTIDlast_committed=1845sequence_number=1846
SET @@SESSION.GTID_NEXT= '0a646c88-36e2-11e7-937d-fa163ed7a7b1:3624'/*!*/;
# at 496564
#170527 4:17:35 server id 12001 end_log_pos 496632 CRC32 0x03150d48 Query thread_id=1852 exec_time=0 error_code=0
SET TIMESTAMP=1495873055/*!*/;
BEGIN
3、write/read thread
異步IO線程數
innodb_write_io_threads=16
innodb_read_io_threads=16
(該參數需要在配置文件中添加,重啟mysql實例起效)臟頁寫的線程數,加大該參數可以提升寫入性能
4、innodb_max_dirty_pages_pct
最大臟頁百分數,當系統中臟頁所占百分比超過這個值,INNODB就會進行寫操作以把頁中的已更新數據寫入到磁盤文件中。默認75,一般現在流行的SSD硬盤很難達到這個比例。可依據實際情況在75-80之間調節,
這個參數太大,導致實例恢復需要很長時間,太小的話會頻繁刷新,增加page_cleaner_thread以及innodb_write_io_threads和cpu的負擔,一般就用默認值;
5、innodb_io_capacity=5000
從緩沖區刷新臟頁時,一次刷新臟頁的數量。根據磁盤IOPS的能力一般建議設置如下:
SAS 200
SSD 5000
PCI-E 10000-50000
6、innodb_flush_method=O_DIRECT(該參數需要重啟mysql實例起效)
控制innodb 數據文件和redo log的打開、刷寫模式。有三個值:fdatasync(默認),O_DSYNC,O_DIRECT。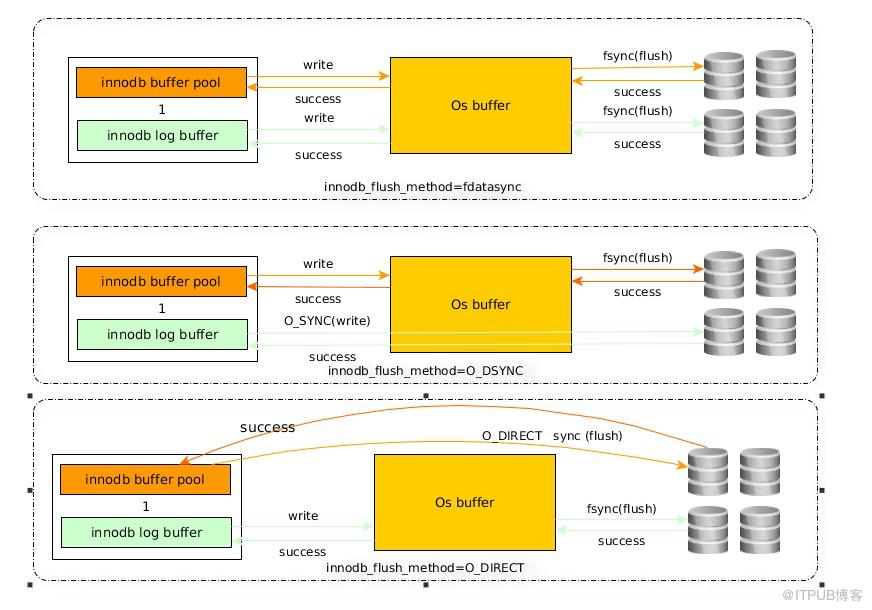
fdatasync模式:寫數據時,write這一步并不需要真正寫到磁盤才算完成(可能寫入到操作系統buffer中就會返回完成),真正完成是flush操作,buffer交給操作系統去flush,并且文件的元數據信息也都需要更新到磁盤。
O_DSYNC模式:寫日志操作是在write這步完成(不通過os buffer),而數據文件的寫入是在flush這步通過fsync完成。
O_DIRECT模式:數據文件的寫入操作是直接從mysql innodb buffer到磁盤的,并不用通過操作系統的緩沖,而真正的完成也是在flush這步,日志還是要經過OS緩沖。

通過圖可以看出O_DIRECT相比fdatasync的優點是避免了雙緩沖,本身innodb buffer pool就是一個緩沖區,不需要再寫入到系統的buffer,但是有個缺點是由于是直接寫入到磁盤,所以相比fdatasync的順序讀寫的效率要低些。所以如果磁盤io壓力不大的話,并且如果系統使用了swap空間,可以考慮innodb_flush_method=O_DIRECT;
在大量隨機寫的環境中O_DIRECT要比fdatasync效率更高些,順序寫多的話,還是默認的fdatasync更高效,因為咱們現在使用了insert buffer cache的使用(轉化成了順序寫),個人認為還是默認值比較好,
7、innodb_adaptive_flushing 設置為 ON (使刷新臟頁更智能)
影響每秒刷新臟頁的數目
規則由原來的“大于innodb_max_dirty_pages_pct時刷新100個臟頁到磁盤”變為 “通過buf_flush_get_desired_flush_reate函數判斷重做日志產生速度確定需要刷新臟頁的最合適數目”,即使臟頁比例小于 innodb_max_dirty_pages_pct時也會刷新一定量的臟頁。
8.innodb_page_cleaners
MySQL 5.7開啟并發刷新線程,innodb_page_cleaners控制刷新線程數
mysql> show variables like 'i%cleaners';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| innodb_page_cleaners | 1 |
+----------------------+-------+
1 row in set (0.05 sec)
配置文件my.cnf中添加innodb_page_cleaners=num值
默認是1;最大可以是64,也就是會有64個page cleaner線程并發工作清理臟頁
9.innodb_flush_ neighbors刷新臨近頁的參數;
當刷新一個臟頁時,Innodb存儲引擎會檢測該頁所在區(extent)的所有的頁,如果是臟頁,那么一起進行刷新。這樣做的好處顯而易見,通過AIO可以將多個IO寫入操作合并為一個IO操作,故該工作機制在傳統機械磁盤下有著顯著的優勢。至于固態硬盤來說,因為它有著超高的IOPS性能,則建議將該參數設置為0,也就是關閉這個特性;個人覺得如果io并不是性能瓶頸,不建議開啟這個功能,因為它可能將不怎么臟的頁進行刷新,而該頁之后又會很快變成臟頁;
10、innodb_adaptive_flushing_method 設置為 keep_average
影響checkpoint,更平均的計算調整刷臟頁的速度,進行必要的flush.(該變量為mysql衍生版本Percona Server下的一個變量,原生mysql不存在)
11、innodb_stats_on_metadata=OFF
關掉一些訪問information_schema庫下表而產生的索引統計。
當重啟mysql實例后,mysql會隨機的io取數據遍歷所有的表來取樣用于統計數據,這個實際使用中用的不多,建議關閉.
11、innodb_change_buffering=all
change buffer可以認為是insert buffer的升級,可以對dml操作---insert、delete、update都進行緩沖,他們分別是:insert buffer、delete buffer、purge buffer;
該參數用來開啟各種buffer的選項,可選擇的值為:inserts、delete、purges、changes、all、none;其中changes代表啟用了inserts和delete,all 表示啟用所有,none表示都不啟用,默認為all;
當更新/插入的非聚集非唯一索引的數據所對應的頁不在內存中時(對非聚集非唯一索引的更新操作通常會帶來隨機IO),會將其放到一個insert buffer中,當隨后頁面被讀到內存中時,會將這些變化的記錄merge到頁中。當服務器比較空閑時,后臺線程也會做merge操作。
由于主要用到merge的優勢來降低io,但對于一些場景并不會對固定的數據進行多次修改,此處則并不需要把更新/插入操作開啟change_buffering,如果開啟只是多余占用了buffer_pool的空間和處理能力。這個參數要依據實際業務環境來配置。
12、innodb_change_buffer_max_size
從Innodb 1.2.X版本開始,可以通過參數innodb_change_buffer_max_size來控制change buffer最大使用內存的數量;默認值為25,表示最多使用25%的緩沖池內存空間,該參數最大有效值為50%。
如果使用太多,那么當MySQL server crash,會進行很長時間的恢復工作(進行merger操作)
13、innodb_old_blocks_pct初始化默認是37,
(innodb體系架構 27頁)注意因為新來的page是放到了尾部3/8的位置(也就是屬于sublist of old blocks)所以sublist of new blocks只能來自于sublist of old blocks的移動
innodb緩存池有2個區域一個是sublist of old blocks存放不經常被訪問到的數據,另外一個是sublist of new blocks存放經常被訪問到的數據
innodb_old_blocks_pct參數是控制進入到sublist of old blocks區域的數量,初始化默認是37.
innodb_old_blocks_time參數是在訪問到sublist of old blocks里面數據的時候控制數據不立即轉移到sublist of new blocks區域,而是在多少微秒之后才會真正進入到new區域,這也是防止new區域里面的數據不會立即被踢出。
所以就有2種情況:
1、如果在業務中做了大量的全表掃描,那么你就可以將innodb_old_blocks_pct設置減小,增到innodb_old_blocks_time的時間,不讓這些無用的查詢數據進入old區域,盡量不讓緩存再new區域的有用的數據被立即刷掉。(這也是治標的方法,大量全表掃描就要優化sql和表索引結構了)
2、如果在業務中沒有做大量的全表掃描,那么你就可以將innodb_old_blocks_pct增大,減小innodb_old_blocks_time的時間,讓有用的查詢緩存數據盡量緩存在innodb buffer pool中,減小磁盤io,提高性能。
21、binlog_cache_size
二進制日志緩沖大小:一個事務,在沒有提交(uncommitted)的時候,產生的日志,記錄到Cache中;等到事務提交(committed)需要提交的時候,則把日志持久化到磁盤。
設置太大的話,會比較消耗內存資源(Cache本質就是內存),更加需要注意的是:binlog_cache是不是全局的,是按SESSION為單位獨享分配的,也就是說當一個線程開始一個事務的時候,Mysql就會為這個SESSION分配一個binlog_cache
怎么判斷我們當前的binlog_cache_size設置的沒問題呢?
mysql> show status like 'binlog_%';
+-----------------------+-----------+|
Variable_name | Value |
Binlog_cache_disk_use | 1425 |
| Binlog_cache_use | 126945718 |
2 rows in set (0.00 sec)
mysql> select @@binlog_cache_size;
+-----------------------+-----------+|
@@binlog_cache_size
1048576
1 row in set (0.00 sec)
運行情況Binlog_cache_use 表示binlog_cache內存方式被用上了多少次,Binlog_cache_disk_use表示binlog_cache臨時文件方式被用上了多少次,當對應的Binlog_cache_disk_use 值比較大的時候 我們可以考慮適當的調高 binlog_cache_size 對應的值
22.innodb_file_per_table兩個取值:
1:開啟獨立表空間;
0:不開啟,也就使用共享表空間;
優點:
1)每個表的數據和索引都會存在自已的表空間中,
2)可以實現單表在不同的數據庫中移動
3)空間可以回收(除drop table操作)
4)刪除大量數據后可以通過:alter table TableName engine=innodb; 回縮不用的空間
使用turncate table也會使空間收縮
5)對于使用獨立表空間的表,不管怎么刪除,表空間的碎片不會太嚴重的影響性能
缺點:
1)單表增加過大,如超過100個G,使用共享表空間可能會更好!
結論:共享表空間在Insert操作上少有優勢。其它都沒獨立表空間表現好。當啟用獨立表空間時,請合理調整一 下:innodb_open_files,因為每個表對應一個文件,需要打開的文件個數比共享表空間要多,所以需要適當調大innodb_open_files的參數,并且調高linux內核參數 open files的限制1
想要將共享表空間轉化為獨立表空間有兩種方法:
1.先邏輯備份,然后修改配置文件my.cnf中的參數innodb_file_per_table參數為1,重啟服務后將邏輯備份導入即可。
2.修改配置文件my.cnf中的參數innodb_file_per_table參數為1,重啟服務后將需要修改的所有innodb表都執行一遍:alter table table_name engine=innodb;
使用第二種方式修改后,原來庫中的表中的數據會繼續存放于ibdata1中,新添加的數據才會使用獨立表空間
23.sync_relay_log:
sync_relay_log:默認為10000,即每10000次sync_relay_log事件會刷新到磁盤。為0則表示不刷新,交由OS的cache控制,為N就是n次次sync_relay_log事件會刷新到磁盤;
If the value of this variable is greater than 0, the MySQL server synchronizes its relay log to disk (using fdatasync()) after every sync_relay_log events are written to the relay log. Setting this variable takes effect for all replication channels immediately, including running channels
當設置為1時,slave的I/O線程每次接收到master發送過來的binlog日志都要寫入系統緩沖區,然后刷入relay log中繼日志里,這樣是最安全的,因為在崩潰的時候,你最多會丟失一個事務,但會造成磁盤的大量I/O。
當設置為0時,并不是馬上就刷入中繼日志里,而是由操作系統決定何時來寫入,雖然安全性降低了,但減少了大量的磁盤I/O操作。這個值默認是10000,可動態修改;
24.然后介紹參數sync_binlog:
sync_binlog = N: 控制的是從binlog buffer中刷新binlog到底層binlog文件(也就是刷新到底層磁盤)
N>0 每向二進制日志文件寫入N條SQL或N個事務后(組提交的時候,實際上是n個組事務),則把二進制日志文件的數據刷新到磁盤上;
N=0 不主動刷新二進制日志文件的數據到磁盤上,而是由操作系統決定;
25.增加本地端口,以應對大量連接
1 | echo ‘1024 65000′ > /proc/sys/net/ipv4/ip_local_port_range |
該參數指定端口的分配范圍,該端口是向外訪問的限制。mysql默認監聽的3306端口即使有多個請求鏈接,也不會有影響。但是由于mysql是屬于高內存、高cpu、高io應用,不建議把多個應用于mysql混搭在同一臺機器上。即使業務量不大,也可以通過降低單臺機器的配置,多臺機器共存來實現更好。
26.增加隊列的鏈接數
1 | echo ‘1048576' > /proc/sys/net/ipv4/tcp_max_syn_backlog |
建立鏈接的隊列的數越大越好,但是從另一個角度想,實際環境中應該使用連接池更合適,避免重復建立鏈接造成的性能消耗。使用連接池,鏈接數會從應用層面更可控些。
27.設置鏈接超時時間
1 | echo '10'> /proc/sys/net/ipv4/tcp_fin_timeout |
該參數主要為了降低TIME_WAIT占用的資源時長。尤其針對http短鏈接的服務端或者mysql不采用連接池效果比較明顯。
28.linux內核信號量
來linux內核信號量默認設置太小,造成大量等待,
默認值如下:
# cat /proc/sys/kernel/sem
250 32000 32 128
說明:
第一列,表示每個信號集中的最大信號量數目。
第二列,表示系統范圍內的最大信號量總數目。
第三列,表示每個信號發生時的最大系統操作數目。
第四列,表示系統范圍內的最大信號集總數目。
將第三列調大一點,參考網上的數據
echo "kernel.sem=250 32000 100 128″>>/etc/sysctl.conf
然后sysctl -p
重啟mysql
如果設置過小,當大量并發的時候,會在錯誤日志中報錯:InnoDB: Warning: a long semaphore wait!!!!
“MySQL性能需要關注的參數有哪些”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





