溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關大量刪除導致MySQL慢查的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
一、背景
監控上收到了大量慢查的告警,業務也反饋查詢很慢,隨即打開電腦確認慢查的原因。
二、現象描述
通過平臺的慢查分析之后,我們發現慢查有以下特征:
慢查的表名都是 sbtest1,沒有其他的表;
大部分的慢查都是查表最新的數據,例如 select * from sbtest1 limit 1;
rows examined 為 1,沒有掃描大量的數據。
三、問題分析
通對慢查的大致分析,SQL 本身沒有發現問題。那么是不是主機或者網絡等有問題呢?
經過對網絡和主機磁盤的 IO 等的分析,負載均正常,沒有丟包的現象。
回到數據庫本身,慢查還在,確認下慢查到底是慢在哪里。
當慢查在執行的時候,大部分的都是表現在 Sending data 的狀態,我們通過 profiling 去確認下慢查的時間分布:
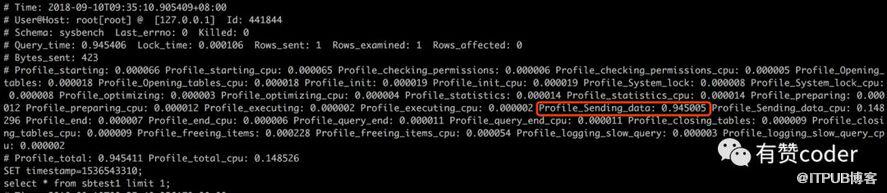
從圖中,我們可以看到 sending data 耗費的時間為 0.945 秒,基本占據了 SQL 執行時間的99%。
那么 sending data 是什么意思呢,我們從官方文檔里面了解下。
The thread is reading and processing rows for a SELECT statement, and sending data to the client. Because operations occurring during this state tend to perform large amounts of disk access (reads), it is often the longest-running state over the lifetime of a given query.
Sending data 表示在讀取以及處理行數據以及發送數據到客戶端,由于數據只有一行,且當時網絡確認正常,那么時間就是耗費在讀取和處理 select 的數據。
那為啥只取 limit 1,而且沒有 where 條件的 SQL 執行掃描一行數據會這么慢呢?
打開監控,看看有沒有啥指標異常。
我們注意到數據庫的 History list length 這個指標一直在升高,達到了幾萬。慢查的執行時間是隨著 History list length 升高而變的更慢。當 History list length 一直居高不下的時候,說明了有大量的 UNDO 沒有被 purge。由于當前數據庫的隔壁級別是 RR,開始比較早的事務,如果還沒提交,就需要通過 UNDO 去構建對應版本歷史時,保證數據庫的可重復讀(跟 MVCC 有關)。
既然 History list length 那么高,可能是有歷史事務出現異常沒有提交,也有可能是一致性快照的備份。可以通過 information_schema.innodb_trx 表去確認對應的事務信息。經過查詢,的確發現一個事務執行了4個小時左右,沒有提交,且不是備份用戶。手動將該線程執行 kill 操作,慢查消失。
3.1 聊一下 MVCC
MySQL InnoDB 支持 MVCC 多版本,可以在普通的 SELECT 時不加鎖。利用多版本讀取指定版本的行記錄,降低加鎖的次數,能極大提高數據庫的并發讀寫能力。
Innodb 在事務的某個時刻記錄下 MySQL 所有的活躍事務列表,保存到 read view 里面。在之后的查詢中,通過比較記錄的事務ID和 read view 里面的事務列表,判斷記錄是否可見。
3.1.1 Innodb 行記錄
在 Innodb 的行結構中,還存在三個系統列,分別是 DATA_ROW_ID、DATA_TRX_ID、DATA_ROLL_PTR。
DATA_ROW_ID: 如果表沒有顯示定義主鍵,則采用 MySQL 自己生成的 ROW_ID,為 48-bit,否則表示的是用戶自定義的主鍵值;
DATA_TRX_ID:表示這條記錄的事務 ID。如果是二級索引,只在 page 里面保存 trx_id;
DATA_ROLL_PTR: 指向對應的回滾段的指針。
3.1.2 read view
read view 是在 SQL 語句執行之前申請的,其中 RC 隔離級別是每個 SELECT 都會申請,RR 隔離級別的 read view 是事務開始之后的第一個 SQL 申請,之后事務內的其他 SQL 都使用該 read view。
read view 中有三個變量需要重點關注:
low_limit_id:表示的是創建 read view 那一刻活躍的事務列表的最大的事務 ID;
up_limit_id:表示的是創建 read view 那一刻活躍的事務列表的最小的事務 ID;
trx_ids:表示的創建 read view 那一刻所有的活躍事務列表。
3.1.3 判斷記錄可見
當記錄的 DATA_TRX_ID 小于 read vew 的 up_limit_id,說明該記錄在創建 read view 之前就已經提交,記錄可見;
如果記錄的 DATA_TRX_ID 和事務創建者的 TRX_ID 一樣,記錄可見;
當記錄的 DATA_TRX_ID 大于 read view 的 up_limit_id,說明該記錄在創建 read view 之后進行的新建事務修改提交的,記錄不可見;
在 RR 隔離級別,如果 A 事務在 B 事務創建 read view 之前開始的,那么 B 事務里面的 SQL 是不能看到 A 事務執行的修改的。因此還有一條規則:如果記錄對應的 DATA_TRX_ID 在 read view 的 trx_ids 里面,那么該記錄也是不可見的。
3.1.4 DATA_ROLL_PTR
UNDO 日志是 MVCC 的重要組成部分,當一條數據被修改時,UNDO 日志里面保存了記錄的歷史版本。當事務需要查詢記錄的歷史版本時,可以通過 UNDO 日志構建特定版本的數據。
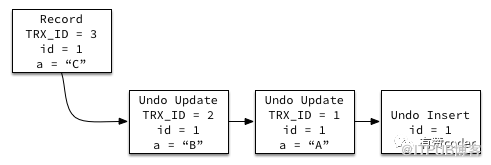
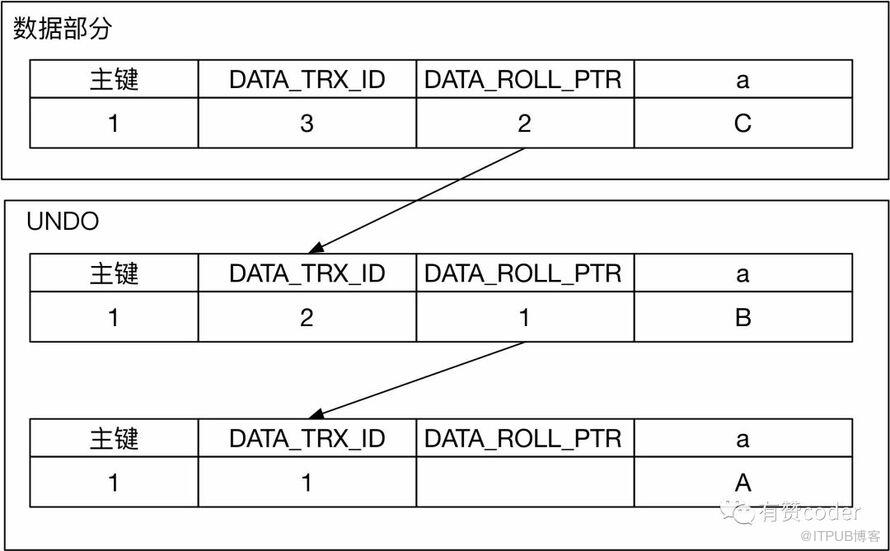
每條行記錄上面都有一個指針 DATA_ROLL_PTR,指向最近的 UNDO 記錄。同時每條 UNDO 記錄包含一個指向前一個 UNDO 記錄的指針,這樣就構成了一條記錄的所有 UNDO 歷史的鏈表。當 UNDO 的記錄還存在,那么對應的記錄的歷史版本就能被構建出來。
當記錄對應的版本通過 DATA_TRX_ID 比對發現不可見時,通過系統列 DATA_ROLL_PTR,找到對應的回滾段記錄,繼續通過上述判斷記錄可見的規則,進行判斷,如果記錄依舊不可見,繼續通過回滾段查找之前的版本,直到找到對應可見的版本。
3.2 慢查問題復現
經過和業務方溝通,得知該表每天都有定時任務,會刪除歷史數據。大致了解到整個過程后,我們搭建模擬環境進行測試。
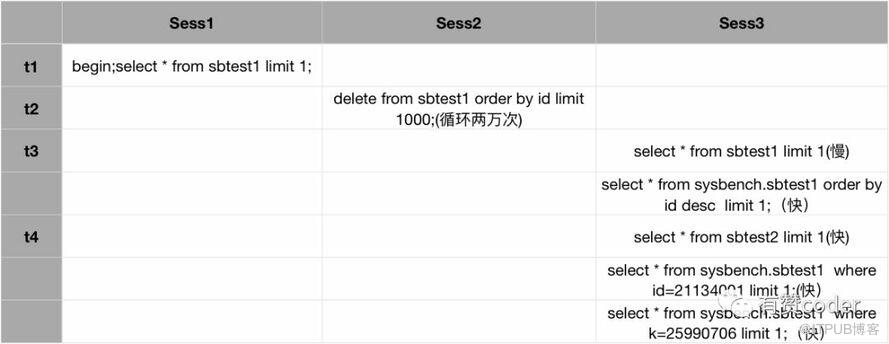
測試分為三個 session,其中 Sess1 執行長事務,沒有提交。Sess2 對表的歷史數據做清理,清理了 2000 萬的數據。此時在 Sess3 執行查詢,快慢情況如上圖所示。select * from sbtest1 limit 1 跟預期表現一樣,為很慢。但是 select * from sbtest1 order by id desc limit 1 執行很快,這是為什么呢?
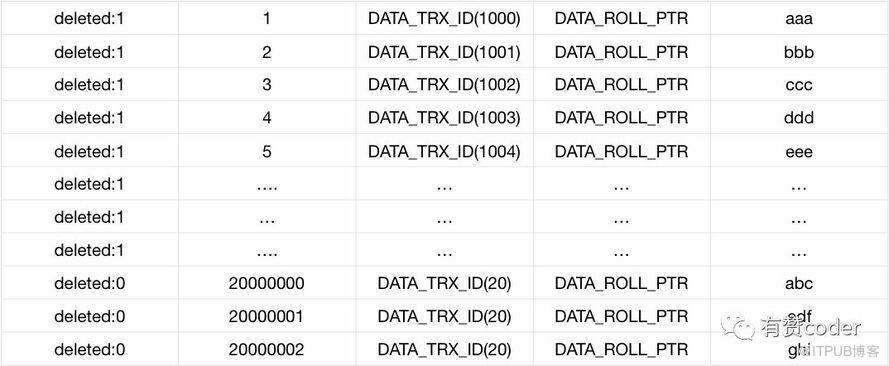
上圖為主鍵的記錄格式,在每條主鍵記錄的前面有個刪除標志位,然后是主鍵 ID,事務 ID,回滾段指針,最后是行記錄。
當記錄被執行刪除的時候,MySQL 只是將記錄標記為已刪除,同時更新 DATA_TRX_ID 為自己刪除會話的事務 ID,并沒有將記錄真正刪除。當被刪除的記錄不再被其他事務需要的時候,會被 purge 線程刪除。purge 線程負責清理這些真正被刪除的記錄以及不再需要的 UNDO 日志。
回到慢查本身,我們來看看慢查的執行過程。
SQL 為 select * from sbtest1 limit1。
通過主鍵,掃描到 ID=1 的記錄,根據 MVCC 比對,發現自己的事務 ID 大于記錄的 DATA_TRX_ID,匹配可見規則 1,記錄可見;
由于 ID=1 已經被標記為 DELETED,刪除記錄可見;
由于表數據還沒有全部掃描完成,未滿足 limit 1,繼續掃描下一條記錄;
掃描到 ID=2 的記錄,根據 MVCC 比對,發現自己的事務 ID 大于記錄的 DATA_TRX_ID,匹配可見規則 1,記錄可見;
由于 ID=2 已經被標記為 DELETED,刪除記錄可見;
由于表數據還沒有全部掃描完成,未滿足 limit 1,繼續掃描下一條記錄;
重復 4-6 步驟,直到滿足找到一條記錄,或者全表掃描完成。
由于被刪除的記錄有 2000 萬,Innodb 需要掃描 2000 萬的記錄,才能找到符合條件的第一條記錄,然后返回到 MySQL 的 Server 層。
當 SQL 為 select * from sbtest1 order by id desc limit1。
由于刪除的是老數據,當從 ID 最大的方向開始掃描時,通過 MVCC 判斷可見,然后判斷記錄是否被標記為刪除的時候,記錄沒有被刪除,因此就可以快速返回到 Server 層,SQL 執行效率就會很高。
關于“大量刪除導致MySQL慢查的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





