溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、引言
在運維MySQL時,經常遇到的一個問題就是活躍連接數飆升。一旦遇到這樣的問題,都根據后臺保存的processlist信息,或者連上MySQL環境,分析MySQL的連接情況。處理類似的故障多了,就萌生了一種想法,做個小工具,每次接到這種報警的時候,能夠快速地從各個維度去分析和統計當前MySQL中的連接狀態。比如當前連接的分布情況、活躍情況等等。
另外,真實故障處理時,光知道連接分布情況往往還不夠,我們需要知道當前MySQL的正在忙于做什么,也就是正在執行一些什么樣的SQL。而且,有時候即使我們知道了當前執行的SQL情況,也很難找到根因,因為如果活躍連接一旦飆升,這是的CPU基本上是處于被打滿的狀態,IO的負載也非常高,即使平時很快的SQL也變成了慢SQL,更不用說本身就很慢的SQL了。那我們怎么去甄別這些SQL里,哪些是導致問題的罪魁禍首,哪些僅僅是受害者呢?
帶著這些需求和問題,本文逐漸展開并一一做分析和解答,展示我們這個小工具的功能。
二、連接分析
想知道當前MySQL的連接信息,最直觀的方法是看MySQL的processlist,如果希望看到完整的SQL,可以執行show full processlist,或者直接查information_schema中的processlist這個表。當MySQL中連接數比較少的時候,還能夠人肉分析出來,可是如果連接數比較多,那就很難考肉眼看processlist去分析問題了。
最開始,我們的做法是寫個腳本,用MySQL客戶端在命令行登錄MySQL,并執行show full processlist,然后將輸出作為一個文本分析。本來這種實現方式在MySQL5.5和MariaDB上運行得很好,可是,當在MySQL5.6環境上運行時,出現了問題,在控制臺輸出中會多出一行Warning: Using a password on the commandline interface can be insecure,相信很多運行orzdba的同學也遇到過這種情況。這個是MySQL5.6本身的安全提示,輸入明文密碼時,沒有辦法避免,阿里的同學還分享過他們為此做過源碼改造,因為他們很多任務都依賴于命令行執行MySQL命令并捕獲結果。
還有另外一種方式規避這個問題就是用mysql_config_editor這個工具,但是這個需要做額外的一些配置,同時也有安全上的隱患。我們沒有能力改造源碼,但是也不想使用mysql_config_editor,所以我們使用了另外的方式,不從命令行登錄,而是用information_schema的表processlist作為數據源,在上面做查詢,得到processlist的信息。還有另外一張表performance_schema.threads,也包含了同樣的結果,甚至更豐富的后臺線程信息,而且相比information_schema.processlist,在查詢的時候不用申請mutex,對系統系能影響小,不過這要求打開perfomance schema,感興趣的同學可以自己嘗試。
確定了連接信息來源,下面就開始分析信息統計維度。查看processlist這個表,表結構如下(以MySQL5.6為例,MariaDB可能有額外的信息):
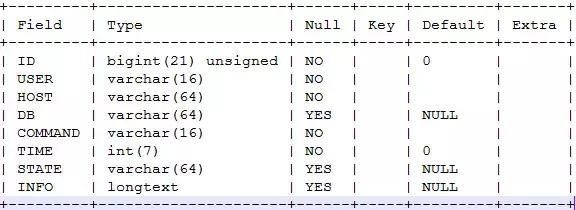
ID:線程ID,這個信息對統計來說沒有太大作用
USER:連接使用的賬號,這個是一個統計維度,用于統計來自每個賬號的連接數
HOST:連接客戶端的IP/hostname+網絡端口號,這也是一個統計維度,用于確定發起連接的客戶端
DB:連接使用的default database,DB通常對應具體服務,可以用于判斷服務的連接分布,這算一個統計維度
COMMAND:連接的動作,實際上是說連接處于哪個階段,常見的有Sleep、Query、Connect、Statistics等,這也是一個統計維度,主要用于判斷連接是否處于空閑狀態
TIME:連接處于當前狀態的時間,單位是s,這個在后面進行分析,暫不算在連接狀態的統計維度中
STATE:連接的狀態,表示當前MySQl連接正在做什么操作,這算一個統計維度,可能的值也比較多,詳細可以查閱官方文檔
INFO:連接正在執行的SQL,這個在下一節分析,暫不算在連接狀態的統計維度中
通過上面的分析,總結出了5個連接的統計維度:user、host、db、command和state。有了這5個統計維度,我們就可以開始著手寫小工具了。

最基本的功能需求就是,查詢information_schema.processlist這個表,然后按剛才總結的5個統計維度,對MySQL中的連接進行分組統計,按照統計個數排序。processlist這個表的host字段需要做一些細節上的處理,因為它的值實際上是IP/hostname+網絡端口號的組合,我們需要把端口號裁剪掉,這樣才能按照客戶端進行統計,否則每個客戶端連接的端口號都是不一樣的,沒法進行分組統計。
最后的輸出如下:

有了最基本的功能,能滿足最基本的統計需求。可是在實際排查和處理線上問題時,可能并不關心所有的統計維度,只需要按照上述5個維度中的部分進行統計;另外,可能希望host出現在user的前面,優先按照客戶端的IP或者是hostname進行統計。所以,這就要求這個工具具有增加靈活地添加或者刪除統計維度的功能,而且能夠對統計維度的出現順序進行動態調整。
最后的示例輸出如下:
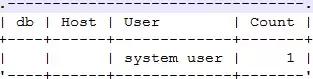
最開始說了,我們造這個工具的初衷是分析活躍連接,可是統計出來的結果中,包含了空閑連接,那么需要將空閑連接從統計結果中排除出去。當然,除了空閑連接,可能還有一些MySQL本身的一些連接,例如slave線程,binlog dump線程等,也希望從結果排除出去。這就要求有個按照任意統計維度進行排除的功能。既然有了排除功能,那同樣也可以增加包含功能,即按照任意統計維度進行過濾,包含固定條件的連接才能出現在統計結果之中。
有了這個連接統計信息,我們就清楚當前MySQL內部的連接狀態,大致判斷出是哪個業務或者模塊有問題。
三、SQL分析
分析到業務或者模塊的粒度還不夠,到底是哪個接口或者是哪個功能有問題呢?根據上面的連接狀態信息,還沒有辦法準確地回答這個問題。我們繼續深入,分析processlist中的SQL,回去看到上節中被我們暫時忽略的information_schema.processlist這個表的INFO字段,里面就保存了每個活躍連接上正在執行的SQL信息。通過分析和統計SQL,我們才真正清晰地掌握MySQL當前的內部活動,活躍連接都在干些什么事。通過這種方式,我們可以協助RD同學快速地定位問題,找到有問題的接口或者是功能模塊。
其實,要統計SQL并不容易,因為SQL千變萬化,每一條SQL都不是一樣的,即使是統一功能模塊的SQL,參數也可能不一樣。那這種情況下,如何統計SQL呢?這里借鑒了pt-toolkit中的設計思想。在pt-query-digest的分析結果中,有一個fingerprint的字段,它其實是一個hash值,這個hash值代表了一類SQL,這類SQL除了參數不一樣之外,其它的SQL結構都是完全一致的。所以我們把這種思路引入到具體實現中,通過正則,將SQL中的具體條件都去掉,然后將正則之后的SQL結構相同的SQL都算作同一條SQL,然后就可以進行分組統計了。舉個例子,比如現在應用里有2條SQL,分別如下:
SELECT * FROM `xxxxxxxxxxxxxxxxxxxx` `t` WHERE `t`.`ucid`='1000000020018048' LIMIT 1
SELECT * FROM `xxxxxxxxxxxxxxxxxxxx` `t` WHERE `t`.`ucid`='1000000020281039' LIMIT 1
這2條SQL除了最后where條件中ucid字段的值不一樣之外,其他的SQL結構是完全一致的。通過正則匹配之后,將ucid的值和limit的行數去掉,在最終的統計結果中,這2條SQL都變成了下面的SQL:
SELECT * FROM `xxxxxxxxxxxxxxxxxxxx` `t` WHERE `t`.`ucid`=? LIMIT ?
這樣,就實現了SQL的分組統計。

示例輸出如下:

當然,還可以根據需要,添加一些附加信息,便于定位和分析問題,例如user、Host等。

四、事務分析
有了SQL分析和統計,在某些場景下,基本能定位到問題所在,比如高頻的執行計劃良好的SQL。可是如果是由于慢SQL導致整個系統響應變慢的場景,上面單純的SQL統計是否還能夠有效地快速定位出問題呢?肯定不能,因為此時,單純地從統計結果,無法分辨出哪些是導致系統響應變慢的慢SQL,哪些是被影響的SQL。當然,統計結果中,次數多的SQL可能會是慢SQL,但是也可能本身就是一些高頻的接口調用,因為系統響應變慢,導致請求堆積。所以,最好的辦法就是能夠加入一些其它的輔助信息,幫助判斷哪些請求可能是慢查詢。那加入哪些輔助信息呢?有兩種選擇。
首先,我們回去看第一節被我們忽略的information_schema.processlist這個表的Time字段,可以用于大概判斷連接的上SQL的執行,和實際時長的差異取決于SQL執行時每個階段所消耗的時間。其次,因為線上表都是InnoDB表,所以可以和InnoDB的事務統計信息進行關聯。InnoDB的事務分為只讀事務和讀寫事務,信息都保存在information_schema.INNODB_TRX這張表里。對于某些大事務的場景下,一個事務包含多個操作,這種方式得出的結果會有偏差。如果是非InnoDB的引擎,這種方式不適用。
此處分析時,以只讀事務,也就是select語句為例。在實現上,我們將問題簡化,通過processlist中time字段的值或者事務的執行時間,去預估一條SQL的執行時間,進而判斷在processlist中,積壓的大量連接中,哪些請求本身就是慢查詢,哪些是受影響變慢的查詢。利用事務判斷時,將processlist中ID字段和information_schema.INNODB_TRX中trx_MySQl_thread_id字段做關聯,具體的SQL為select p.*, now() - t.trx_started as runtime frominformation_schema.processlist p, information_schema.INNODB_TRX t where p.id =t.trx_MySQl_thread_id。最后,統計正則之后每一類SQL總的執行時間,以及平均執行時間。執行時間越長的,我們更傾向于認為是導致問題的罪魁禍首。
示例輸出如下:

RT:這一類SQL截止當前,總的執行時間,單位是S(秒)
AVGRT:這一類SQL截止當前,每個事務平均執行時間,單位是S(秒)
加入user、Host等附加信息之后,輸出如下:

五、結語
通過上面的3個維度,把MySQL的processlist中的可用信息基本上都挖掘得差不多了。我們在實際問題排查和處理時,也經常使用這個工具,經過實踐檢驗,問題定位效率還是比較高效的。
但是,也還存在很多改進的地方。比如SQL語句分析中,limit值不同的,嚴格來說其實應該算不同的SQL,因為執行時間可能相差非常大。另外,SQL執行時間分析中,對于單條select語句的只讀事務分析結果非常準確,但是對于讀寫事務,怎么減少結果的誤差,因為讀寫事務相比只讀事務會更復雜,因為可能涉及鎖等待等一些額外的情況。所有的這些已經在我們的改進計劃中,如果大家有好的思路或者是想法,歡迎交流。
我們自己做這些事情,其實日常運維經驗的積累和沉淀,如果剛好某位同學的思路和實現有雷同,實屬必然。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





