溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家介紹該如何進行MySQL的索引分類,內容非常詳細,感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
MySQL的索引分類問題一直讓人頭疼,幾乎所有的資料都會給你列一個長長的清單,給你介紹什么主鍵索引、單值索引,覆蓋索引,自適應哈希索引,全文索引,聚簇索引,非聚簇索引等……給人的感覺就是云里霧里,好像MySQL索引的實現方式有很多種,但是都沒有一個清晰的分類。所以本人嘗試總結了一下如何給MySQL的索引類型分類,便于大家記憶,由于MySQL中支持多種存儲引擎,在不同的存儲引擎中實現略微有所差距,下文中如果沒有特殊聲明,默認指的都是InnoDB存儲引擎。
索引從不同維度劃分可以有很多種名稱,但是需要明確一個問題——索引的本質是一種數據結構,其他索引的劃分則是針對實際應用而言。
索引是提高查詢效率的數據結構,而能夠提高查詢效率的數據結構有很多,如二叉搜索樹,紅黑樹,跳表,哈希表(散列表)等,而MySQL中用到了B+Tree和散列表(Hash表)作為索引的底層數據結構(其實也用到了跳表實現全文索引,但這不是重要考點,所以可以忽略)。
MySQL并沒有顯式支持Hash索引,而是作為內部的一種優化。具體在Innodb存儲引擎里,會監控對表上二級索引的查找,如果發現某二級索引被頻繁訪問,二級索引成為熱數據,就為之建立hash索引。因此,在MySQL的Innodb里,對于熱點的數據會自動生成Hash索引。這種hash索引,根據其使用的場景特點,也叫自適應Hash索引。
這個是MySQL索引的基本實現方式。除了全文索引、hash索引,Innodb、MyISAM的索引都是通過B+樹實現的。
為了能應對不同的數據檢索需求,索引既可以僅包含一個字段,也可以同時包含多個字段。單個字段組成的索引可以稱為單值索引,否則稱之為復合索引,也稱為組合索引或多值索引。
這個很好理解,假如我們有一張表,有三個屬性,分別是 id,age 和 name 。假如在id上建立索引,那這就是單值索引;如果在 name 和 age 上建立索引,那這就是復合索引。
復合索引的索引的數據順序跟字段的順序相關,包含多個值的索引中,如果當前面字段的值重復時,將會按照其后面的值進行排序。
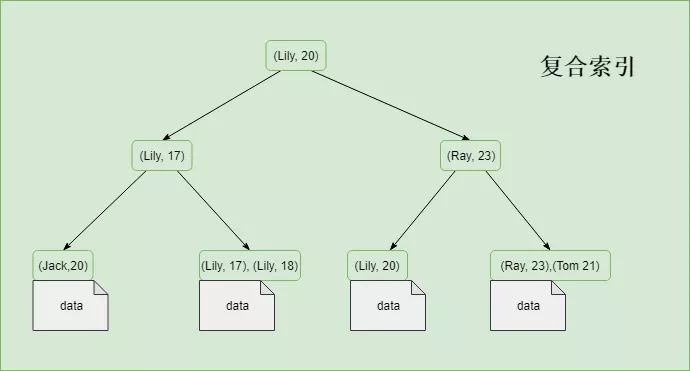
使用覆蓋索引的前提是字段長度比較短,對于值長度較長的字段則不適合使用覆蓋索引,原因有很多,比如索引一般存儲在內存中,如果占用空間較大,則可能會從磁盤中加載,影響性能。
MySQL中是根據主鍵來組織數據的,所以每張表都必須有主鍵索引,主鍵索引只能有一個,不能為null同時必須保證唯一性。建表時如果沒有指定主鍵索引,則會自動生成一個隱藏的字段作為主鍵索引。
如果不是主鍵索引,則就可以稱之為非主鍵索引,又可以稱之為輔助索引或者二級索引。主鍵索引的葉子節點存儲了完整的數據行,而非主鍵索引的葉子節點存儲的則是主鍵索引值,通過非主鍵索引查詢數據時,會先查找到主鍵索引,然后再到主鍵索引上去查找對應的數據。
在這里假設我們有張表user,具有三列:ID,age,name,create_time,id是主鍵,(age,create_time,,name)建立輔助索引。執行如下sql語句:
select name from user where age>2 order by create_time desc。
正常的話,查詢分兩步:
1.按照輔助索引,查找到記錄的主鍵,
2.按照主鍵主鍵索引里查找記錄,返回name。
但實際上,我們可以看到,輔助索引節點是按照age,create_time,name建立的,索引信息里完全包含我們所要的信息,如果能從輔助索引里返回name信息,則第二步是完全沒有必要的,可以極大提升查詢速度。
按照這種思想Innodb里針對使用輔助索引的查詢場景做了優化,叫覆蓋索引(在這里小聲吐槽一下,不知道業界起這種名詞干嘛,太容易引起歧義了,叫個索引覆蓋查詢不是更好嗎)。
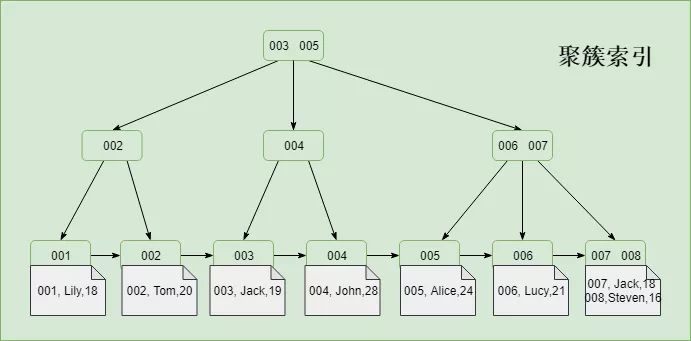
根據數據與索引的存儲關聯性,可以分為聚簇索引和非聚簇索引(也叫聚集索引和非聚集索引)。聚簇索引也叫簇類索引,是一種對磁盤上實際數據重新組織以按指定的一個或多個列的值排序。整個簡潔的說法,這倆的區別就是索引的存儲順序和數據的存儲順序是否是關系的,有關就是聚簇索引,無關就是非聚簇索引。具體實現方式根據索引的數據結構不同會有所不同。下面以B+樹實現的索引為例,舉例來說明聚簇索引和非聚簇索引。
Innodb的主鍵索引,非葉子節點存儲的是索引指針,葉子節點存儲的是既有索引也有數據,是典型的聚簇索引(這里可以發現,索引和數據的存儲順序是強相關的。因此是典型的聚簇索引),如圖:
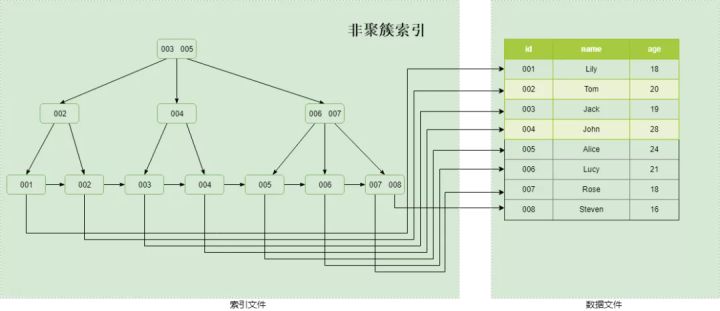
MyISAM中索引和數據文件分開存儲,B+Tree的葉子節點存儲的是數據存放的地址,而不是具體的數據,是典型的非聚簇索引;換言之,數據可以在磁盤上隨便找地方存,索引也可以在磁盤上隨便找地方存,只要葉子節點記錄對了數據存放地址就行。因此,索引存儲順序和數據存儲關系毫無關聯,是典型的非聚簇索引,另外Inndob里的輔助索引也是非聚簇索引。
顧名思義,不允許具有索引值相同的行,從而禁止重復的索引或鍵值。系統在創建該索引時檢查是否有重復的鍵值,并在每次使用 INSERT 或 UPDATE 語句添加數據時進行檢查, 如果有重復的值,則會操作失敗,拋出異常。
需要注意的是,主鍵索引一定是唯一索引,而唯一索引不一定是主鍵索引。唯一索引可以理解為僅僅是將索引設置一個唯一性的屬性。
在MySQL 5.6版本以前,只有MyISAM存儲引擎支持全文引擎。在5.6版本中,InnoDB加入了對全文索引的支持,但是不支持中文全文索引.在5.7.6版本,MySQL內置了ngram全文解析器,用來支持亞洲語種的分詞。主要用來利用關鍵詞查詢文本,不是MySQL的主要面向場景,使用較少,這里就不展開討論了。
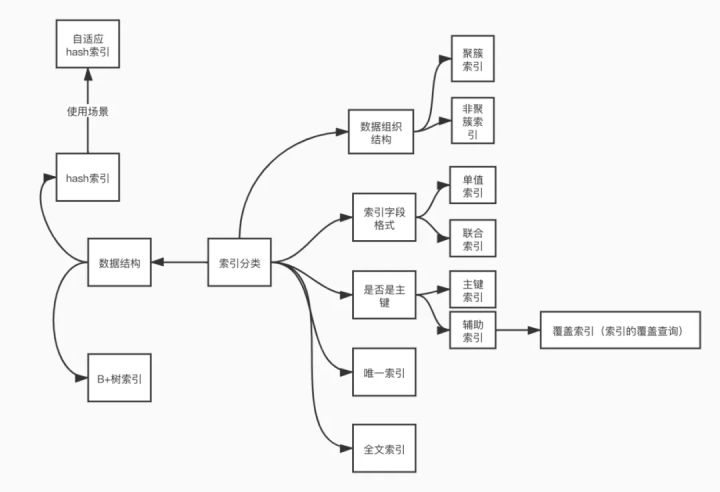
最后總結一張腦圖方便記憶:
關于該如何進行MySQL的索引分類就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





