溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
原題:Oracle RAC建設過程中必須要知和要做的事情 作者:趙海,某城商行系統架構師,專注并擅長銀行數據中心解決方案規劃及設計。
數據庫建設過程中缺少可以遵循的實踐標準,知識點和經驗點散落四處難以快速形成邏輯性強的參照標準,面對項目令人無從下手。本文是基于數據建設的規劃、實施以及配置優化等階段對大量文獻的總結提煉,以及從項目的實踐出發,對數據庫建設過程中各個層面應該注意的事項進行的總結。優質長文,建議先收藏后看。
1.背景描述
數據庫建設是每一個企業數據中心建設過程中非常重要的一個環節,直接關系到業務連續性和穩定性。但是我們在數據庫建設過程當中卻很少有可以遵循的實踐標準。當我們面對整個建設項目的規劃設計和配置優化的時候,又覺得無從下手。散落在官方網站上的一些知識點和經驗點無法讓我們快速形成一個具有很強邏輯性的參照標準。本文希望通過以下篇幅的總結和分析,從各個層面給予實踐標準,為日后從事數據庫建設的項目提供一個參考思路。
2.存儲規劃設計的關鍵點 2.1 OCR/VOTE磁盤的合理規劃事項
什么是OCR/VOTE磁盤,它在集群中是什么樣的角色呢?
ORACLE RAC ASM管理模式下,磁盤組通常有三個(+DATA,+FRA,+OCR),在OCR磁盤組當中所有的磁盤中存儲的數據包括兩部分,一部分是Vote File,另外一部分就是OCR(Oracle Cluster Registry)。Vote File是用來記錄集群節點的磁盤心跳信息,而OCR是保存集群配置信息的數據。Vote File,以整個文件的方式存儲在OCR磁盤上,不做任何條帶。下圖是其信息記錄的一個說明:
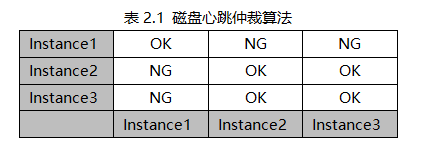
以上是一個三節點的ORACLE RAC集群的Vote FIle的一個示意矩陣,每一行是一個節點的寫入的信息,例如第一行,Instance1分別把其對集群中的三個成員(1、2、3)進行私網檢測的結果寫入到仲裁文件當中,Instance2、Instance3同樣把其檢測結果寫入仲裁文件,最終組成了三個節點的仲裁矩陣。當私網發生故障而從網絡上導致集群分割為幾個孤島子集的時候,集群是通過這個文件的信息來判斷最后存活的節點。具體算法有兩個非常重要的規則:
1. 保障隔離后的集群子集中節點數目最多的子集存活。
2. 當隔離后的集群子集獲得的仲裁票數相等時,保障實例號小者存活。
對于Vote File本身的數目來講,Oracle又有一個非常重要的規則:集群節點獲得的Vote File數目小于N/2+1時,節點就會被集群驅逐出集群,N是Vote File的總數目。也就是說集群中所有節點獲得的Vote File數目必須要大于等于N/2+1。
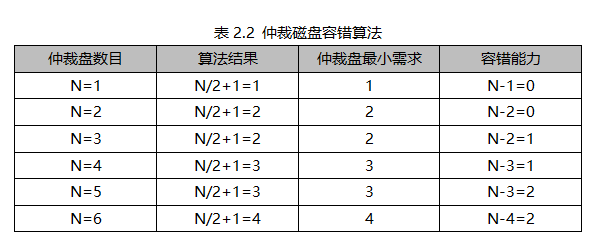
根據以上結果來看,對于VOTE磁盤組的規劃,首先偶數個仲裁磁盤必然會造成一個浪費。那么我們就沒有必要選擇偶數仲裁磁盤。然后我們再考慮磁盤組磁盤的容錯能力,為了保障我們至少有1份磁盤容錯能力,我們的仲裁磁盤至少是3塊兒。也就是說對于OCR磁盤組的規劃來講,至少保障其內有三個容錯組,每一個容錯組里面一塊兒仲裁磁盤。
對于OCR來講,它屬于集群的資源注冊信息,是集群運行的前提條件。所以一定要保障它的高可用性。由于它屬于配置數據,那么一定會遵循ORACLE ASM的磁盤冗余策略(External、Normal、High)。也就是說OCR在OCR磁盤組里面可以擁有1份、2份、3份鏡像。每份鏡像的數據條帶會落在一個獨立的容錯組里。
綜上所述,對于OCR磁盤組的規劃,為了保障仲裁盤的至少一份的容錯能力以及OCR數據的高冗余策略,我們應該至少將磁盤組內規劃為3個磁盤,每一個磁盤落在一個獨立的容錯組。磁盤大小建議為1GB以上(雖然OCR Device = 300M左右)。
2.2 存儲外部冗余架構設計
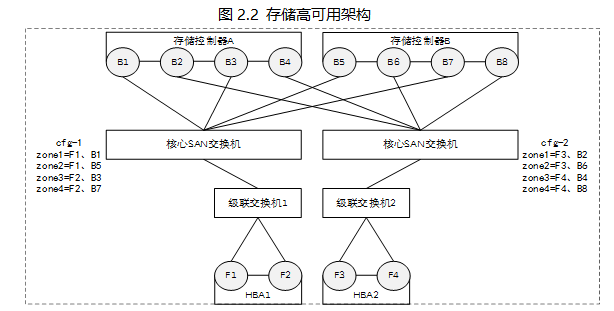
首先一定要用多路徑軟件對Lun進行路徑管理,并且保障鏈路切換策略為負載均衡模式。對于鏈路的數目來講最佳為8條鏈路。而且需要保證這8條鏈路在光纖口、光纖卡、接入交換機、核心交換機、存儲控制器5個層面上的冗余。例如2張雙口光纖卡,每個光纖卡通過各自接入交換機連接到不同的兩個核心交換機上,核心交換機又分別與兩個存儲控制器的前端口相連接。在光纖交換機的zone配置里,每一個主機光纖口wwn和存儲的一個前端口wwn配置在一個zone里面,端口比例為1:2,總共有8個zone。用示意圖的方式表示如下:
2.3 NFS架構的存儲配置參數
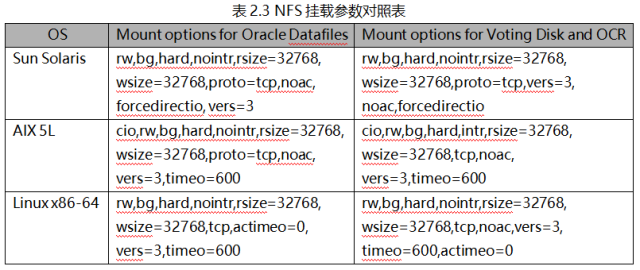
Orace RAC的ASM磁盤可以是網絡存儲架構實現的Lun,當然我們也可以利用文件系統或者裸盤作為數據庫的存儲資源。但是在掛載NFS卷的時候,有若干參數是值得我們注意的。
1)Hard/soft:當應用進程發送一個請求,Hard情況下,客戶端遇到錯誤不會立即通知應用,而是在后臺進行重試直到正常,這會導致應用進程的阻塞;Soft情況下,客戶端會立刻通知應用導致應用掛起。從這個意義上來講,Soft對應用的響應速度會比Hard好,但是如果網絡不穩,那么Soft有可能導致應用數據被損壞。這也是Oracle建議將這個參數設置為Hard的理由。
2)Rsize/Wsize:客戶端從服務器端讀寫文件的最大數目(byte)/每次請求。如果該參數不做設置的話,那么它是通過客戶端和服務器端的協商完成的。一般建議設置為固定的32768。
3)Timeo: 建議為600(60秒)。
4)Intr/nointr: 是否允許接受文件操作的中斷信號,一般而言設置為nointr。
5)Noac/ac: ac情況下,客戶端會緩存文件屬性信息,從而提高客戶端的讀性能。Noac情況下,客戶端不會緩存文件屬性信息,任何情況下的讀都是NFS文件系統上文件的實時版本信息。Ac情況下,客戶端會定期掃描Server端的文件實時信息,其他時候都是讀取自己緩存的信息。NFS卷作為數據庫的存儲磁盤,只需要實時反映文件的真實版本信息即可,不需要客戶端再去做緩存,數據庫有自己的緩存機制。因此一般情況下Oracle建議將這個參數設置為Noac。
當然這些參數,根據不同的操作系統特點是會有一些差異。表2.3是摘自Oracle官方發布的NFS存儲最佳實踐參數表當中的一部分,可以提供通用參考。
2.4 ASM磁盤組規劃
(1)磁盤組相關
除了OCR磁盤組之外,一般建議建立磁盤組不超過2個,一個是存放數據的數據磁盤組(+DATA),另外一個是存放日志的閃回區磁盤組(+FRA)。假設我們選擇磁盤組的冗余策略為Normal,那么建議磁盤數目為偶數個并且至少為4個相同大小相同性能配置,一方面考慮到冗余為2份,另外一方面保障Failure Group里面數目的條帶化分布,可以保障磁盤組的讀寫性能。如果是其他冗余策略,那么按照同樣的思路去選擇磁盤組的數目。另外Lun的大小不能超過2T(容易引起ORA-15196、ORA-15099問題)。
(2)磁盤分配單元及文件條帶
AU是ASM Disk Group磁盤空間分配單元。Strip實際上是文件層面的條帶,準確說法應該是文件的擴展塊兒。對于文件的擴展塊兒來講就是文件切割的單元。它有兩種模式(coarse & fine)。對于coarse模式來講,擴展塊兒大小等于AU大小,對應的參數固定不變(_asm_stripesize=AU,_asm_stripewidth=1)。對于fine模式來講,擴展塊兒大小是可以進行調整,根據我們的業務需求進行適當調整。例如設置為256K,那么原來1M的文件寫在一個磁盤中的AU中,那么現在可以并行寫入到賜個磁盤的4個AU當中。充分發揮了小IO的并行讀寫性能。但是對于某些大IO的數據庫業務,那么AU可以適當調整到4M,同時啟用操作系統的大頁讀寫參數。文件擴展塊兒可以保持corse模式。對于一般的OLTP業務來講,數據文件、歸檔文件一般設置為corse;而redo日志、控制文件、flashback日志設置為fine。對于11g之后的oracle,這些參數基本不需要我們去主動調整,除非確實有性能問題與之相關。
2.5 ASM內存管理參數
(1)內存參數相關
? db_cache_size: 緩沖區,存放metadata塊兒的buffer cache,建議值為64M。
? shared_pool: 管理ASM實例所需要的內存池,建議值為128M。
? Large_pool: 用來存儲 extent maps,建議值為64M。
(2)其他參數相關
在11g當中,如果多個數據庫共享ASM實例的話,那么建議按照以下規則計算process的數目設置。
ASM processes = 25 + (10 + max(可能的并發數據文件變化))* 數據庫的數目。當然這個數目需要一個經驗的評估,需要根據集群環境數據庫的情況以及業務IO的判斷來估算。
2.6 異步IO配置
一般來講數據庫應用都是要啟用異步IO來提高數據庫的IO性能。同時需要打開操作系統的異步IO參數和數據庫的異步IO參數。以Linux為例,在操作系統層面需要設置參數 aio-max-nr=1048576(11g 中設置為 4194304),表示同時可以擁有的異步IO請求數目。然后在Oracle數據庫層面設置以下兩個參數:filesystemio_option=setall;disk_asynch_io=true。對于AIX來說,需要設置以下三個參數(aix_maxservers, aix_minservers,aio_maxreqs)對于OLTP業務來講,IBM官方的建議值為(800,200,16384)。
以上的參數值只是一個通用的參考,但是以上所述的參數具體配置的值還是需要根據自己環境的數據來評估。比如我們需要關注iostat中的io等待情況和aio的一系列指標來判斷設置值的科學與否。
2.7 ASMLib & Udev
對于Linux平臺而言,Oracle RAC的ASM磁盤管理有三種方式(ASMlib、DM、udev),我們首選的方式是ASMlib,對于 RHEL6(從6.4開始),內核驅動軟件包'kmod-oracleasm'已經在 Redhat 平臺上啟動,并且可以通過RedHat Network (RHN)上的"RHEL Server Supplementary (v. 6 64-bit x86_64)" 渠道進行安裝。這個模塊的更新將會由 RedHat 提供。
對于ASMlib的方式,它是通過以下命令方式創建ASM磁盤:
# /usr/sbin/oracleasm createdisk disk_name device_partition_name
通過這種方式創建的ASM磁盤組名稱(disk_name),唯一綁定的是后面的device_partition_name,因此我們必須保障操作系統在日后的Lun變更過程中,這個命名是不能夠變更的。假設我們用的是第三方多路徑軟件管理方式實現,那么需要通過多路徑管理軟件的方式來講磁盤的device_partition_name和磁盤的唯一ID關聯。例如emcpowerpath可以用emcadm export/import方式來保障Rac節點上的Lun名稱一致。
對于udev的方式,同樣道理我們需要將磁盤的scsi-id和最終形成的asm磁盤名稱進行關聯,而不是用磁盤在操作系統顯示的設備名來關聯。例如:
KERNEL=="sd*", BUS=="scsi", PROGRAM=="/sbin/scsi_id -g -u -s %p", RESULT=="36000c29a972d7d5fe0bf683b21046b34", NAME="asmgrid_disk1", OWNER="grid", GROUP="asmadmin", MODE="0660"
其中的PROGRAM字段非常重要,它表示我們是用什么方式來關聯磁盤在操作系統和ASM之間的對應關系。如果在日后的運維過程中,隨著磁盤的增減變化或者服務器的重啟變更等導致了磁盤設備名發生變化,那么就會導致ASM磁盤符號紊亂,最終數據庫集群無法啟動。當然這個問題在11g之后就不存在了,因為11g之后ASM自動會去根據磁盤的唯一ID匹配ASM識別的磁盤ID,節點的讀寫是根據磁盤的ASM標示來執行的。但是從管理科學角度還是應該按照最佳實踐來做從而保障沒有任何風險。
2.8 AIX平臺關注的存儲參數
對于AIX平臺而言,存儲卷的系統參數必須遵循以下規則。
(1) reserve_lock、reserve_policy
該兩個參數其實都是表示操作系統是否持有存儲卷的共享鎖方式。存儲陣列類型為SSA, FAStT, 或者其他 non-MPIO-capable disks,參數設置參照A。存儲陣列類型為SS, EMC, HDS, CLARiiON, 或者其他 MPIO-capable disks,參數設置方式參照B。
A. # chdev -l hdiskn -a reserve_lock=no
B. # chdev -l hdiskn -a reserve_policy=no_reserve
(2) 磁盤在加入ASM磁盤組之前,必須清除其盤頭PVID信息。否則就會導致ORA-15063、ORA-15040、ORA-15042等磁盤錯誤。
(3) fc_err_recov。
該參數表示因為AIX平臺下光纖斷掉場合下,讀寫錯誤切換的時間。正常情況下,這個切換會導致數據庫IO掛起10分鐘。如果是Vote disk,就會導致集群重啟。為了避免此類情況發生需要把該參數的值設置為fast_fail,實現快速切換。
(4) max_transfer。
該參數建議設置最少為Oracle最大請求的IO大小,一般超過1M。
(5) queue_depth。
該參數表示Lun的最大IO隊列深度,這個參數的設置必須足以支撐數據庫并發讀寫的負載。
(6) max_xfer_size。
該參數表示光纖卡的最大傳輸大小,這個參數的設置必須與磁盤的吞吐參數保持倍數關系,并且必須大于磁盤設置的參數。
(7) num_cmd_elems。
該參數表示光纖卡接受的最大IO請求數目,這個參數同樣與磁盤的queue_depth有著倍數關系,具體值的設定需要看環境當中光纖卡和其所容納Lun的數目。
3.網絡規劃設計的關鍵點 3.1 硬件及參數
從Oracle官方的推薦來看,他們首先推薦使用萬兆以太網,至少使用千兆以太網,負載如果很高那么私網可以采用infiniband。當然這個完全取決于客戶生產環境的具體業務量及負載情況。這個僅僅是個參考,有條件的情況下可以按照推薦進行配置。私網的連接需要使用交換機,Oracle集群安裝并不支持私網的直連架構。網卡及交換機的雙攻擊速率參數保持正確一致。
3.2 網卡綁定
各種平臺都有自己的網卡綁定工具,而且提供負載均衡和主備模式的綁定。首先為了提高公網和私網的網絡高可用,網卡需要綁定。對于Linux平臺我們需要在配置文件 “/etc/modprobe.d/dist.conf” 中將數mode來控制網卡綁定的具體策略:
? mod=0,即:(balance-rr)Round-robin policy(平衡掄循環策略)。
? mod=1,即: (active-backup)Active-backup policy(主-備份策略)。
? mod=2,即:(balance-xor)XOR policy(平衡策略)。
? mod=3,即:broadcast(廣播策略)。
? mod=4,即:IEEE 802.3ad Dynamic link aggregation(IEEE802.3ad 動態鏈接聚合)。
? mod=5,即:(balance-tlb)Adaptive transmit load balancing(適配器傳輸負載均衡)。
? mod=6,即:(balance-alb)Adaptive load balancing(適配器適應性負載均衡)。
對于私網網卡綁定方式mode=3&6會導致ORA-600,公網網卡綁定方式mode=6會導致BUG9081436。對于具體的綁定模式,對于平臺版本低而且網絡架構非常復雜的場合,還是建議主備模式,因為主備模式更穩定,不容易產生數據包路徑不一致的問題。如果是負載均衡模式的場合,如果網絡參數設置不是很科學的情況下,很容易出現從一個物理網卡發送報文,但是回報文卻回到另外一個物理網卡上,網絡鏈路再加入防火墻的規則之后,非常容易導致丟包問題發生。
而對于AIX平臺來講,將參數mode修改為NIB或者Standard值。Standard是根據目標IP地址來決定用哪個物理網卡來發送報文,是基于IP地址的負載均衡,也不易產生上述的丟包問題。
3.3 SCAN
Oracle RAC,從11gr2之后增加了SCAN(Single ClientAccess Name)的特性。
SCAN是一個域名,可以解析至少1個IP,最多解析3個SCAN IP,客戶端可以通過這個SCAN 名字來訪問數據庫,另外SCAN ip必須與public ip和VIP在一個子網。啟用SCAN 之后,會在數據庫與客戶端之間,添加了一層虛擬的服務層,就是SCAN IP和SCAN IP Listener,在客戶端僅需要配置SCAN IP的tns信息,通過SCANIP Listener,連接后臺集群數據庫。這樣,不論集群數據庫是否有添加或者刪除節點的操作,均不會對客戶端產生影響,也就不需要修改配置。對于SCAN相關的配置,有以下一些配置注意事項:
(1)主機的默認網關必須與SCAN以及VIP在同一個子網上。
(2)建議通過 DNS,按round-robin方式將 SCAN 名稱(11gR2 和更高版本)至少解析為 3 個 IP 地址,無論集群大小如何。
(3)為避免名稱解析出現問題,假設我們設置了三個SCAN地址,那么HOSTs文件當中不能出現SAN的記錄,因為HOSTs文件當中的記錄是靜態解析,與DNS動態解析相悖。
3.4 網絡參數
操作系統平臺上關于網絡的內核參數非常重要,直接決定私網公網數據傳輸的穩定性和性能。不過針對不同的操作系統,相關的參數設置也各有差異。
1.Linux
對于Linux平臺的內核參數,有兩個非常重要(net.core.rmem_default、net.core.rmem_max)。具體功能解釋如下:
? net.ipv4.conf.eth#.rp_filter:數據包反向過濾技術。
? net.ipv4.ip_local_port_range:表示應用程序可使用的IPv4端口范圍。
? net.core.rmem_default:表示套接字接收緩沖區大小的缺省值。
? net.core.rmem_max:表示套接字接收緩沖區大小的最大值。
? net.core.wmem_default:表示套接字發送緩沖區大小的缺省值。
? net.core.wmem_max:表示套接字發送緩沖區大小的最大值。
為了獲得更好的網絡性能,我們需要根據具體情況把以上兩個參數從其默認值適當調整為原來的2-3倍甚至更高,關閉或者設置反向過濾功能為禁用0或者寬松模式2。
2.AIX
對于AIX平臺的內核參數,以下設置是從Oracle官方文檔摘出的最佳配置:
tcp_recvspace = 65536;tcp_sendspace = 65536;
udp_sendspace = ((db_block_size *db_multiblock_read_count) + 4096) ;
udp_recvspace = 655360;
rfc1323 = 1;
sb_max = 4194304;
ipqmaxlen = 512;
第1、2個參數表示TCP窗口大小,第3、4個參數表示UDP窗口大小。rfc1323啟用由 RFC 1323(TCP 擴展以得到高性能)指定的窗口定標和時間圖標。窗口定標允許 TCP 窗口大小(tcp_recvspace 和 tcp_sendspace)大于 64KB(65536)并且通常用于大的 MTU 網絡。默認為0(關),如果試圖將 tcp_sendspace 和 tcp_recvspace 設為大于 64 KB則需要先修改此值為1。ipqmaxlen 表示指定接收包的數目,這些包可以列在 IP 協議輸入隊列中。sb_max指定一個 TCP 和 UDP 套接字允許的最大緩沖區大小。
3.5 安全配置事項
1.Linux平臺下的防火墻需要關閉,否則會引起公網或者私網的通訊問題。
# chkconfig iptables stop
2.Linux平臺下的selinux安全配置項需要關閉,配置文件為/etc/security/config。
SELINUX=disabled
3.如果是Power System主機的PowerVM虛擬化架構下的AIX平臺,如果發現Oracle RAC的兩個節點之間有大量丟包現象或者是以下幾種事件:
? Cache Fusion "block lost"
? IPC Send timeout
? Instance Eviction
? SKGXPSEGRCV: MESSAGE TRUNCATED user data nnnn bytes payload nnnn bytes
那么我們需要檢查VIOS分區操作系統的補丁信息,如果沒有APAR IZ97457,那么我們需要將這個補丁打上,詳細需到IBM官網找到相應的補丁及其詳細解釋。
3.6 通用注意事項
1.系統主機名、域名等配置不允許有下劃線。
2.網卡名稱在兩個節點上保持一致(例:public->eth2e1,private->eth3e2)。
3.網卡設備名稱當中不能包含“.”等特殊字符。
4.私網地址需遵守RFC1918標準,采用其所規定的ABC三類企業內部私網地址。否則會引起BUG4437727發生。A類:10.0.0.0 -10.255.255.255 (10/8比特前綴); B類:172.16.0.0 -172.31.255.255 (172.16/12比特前綴); C類:192.168.0.0 -192.168.255.255 (192.168/16比特前綴)。而且私網VLAN需要與上述no-routeable子網之間需要是1:1的映射關系,以免引起BUG9761210。
5.從11gr2起,私網網段配置需要支持組播功能,因為私網需要通過組播模式實現通訊。
3.7 send (tx) / receive (rx)
UDP包傳輸的過程中,接受進程會讀取數據包頭的校驗值。任何校驗值損壞都會使這個包被丟棄,并導致重發,這會增加CPU的使用率并且延緩數據包處理。
由于網卡上開啟了Checksum offloading 導致了checksum 錯誤,如果出現這樣的問題請檢查checksum offloading的功能是否被禁用,測試后考慮關閉網卡上的該項功能。在Linux系統上執行ethtool -K <IF> rx off tx off可以關閉該功能。
3.8 MTU
不匹配的MTU大小設置會導致傳輸過程中出現 "packet too big" 錯誤并丟失數據包,導致global cache block丟失和大量的重傳(retransmission)申請。而且私網中不一致的MTU值會導致節點無法加入集群的問題。
對于以太網(Ethernet),大多數UNIX平臺的默認值是1500字節。私網鏈路中所有設備都應該定義相同的MTU。請確認并監控私網鏈路中的所有的設備。為ping ,tracepath,traceroute命令指定大的,非默認尺寸,ICMP probe 包來檢查MTU設置是否存在不一致。使用ifconfig或者廠商推薦的工具為服務器網卡(NIC)的MTU設置合適的值。
Jumbo Frames 并不是IEEE 標準配置。單個Jumb Frame的大小是9000 bytes左右。Frame 的大小取決于網絡設備供應商,在不同的通信設備上的大小可能是不一致的。如果默認的MTU 尺寸不是9000bytes,請保證通信路徑中的所有設備(例如:交換機/網絡設備/網卡)都能夠支持一個統一的MTU值,在操作的過程中必須把Frame Size(MTU Size)配置成這個值。不合適的MTU設置,例如:交換機上配置MTU=1500,但是服務器上的私網網卡配置成MTU=9000,這樣會造成丟包,包的碎片和重組的錯誤,這些都會導致嚴重的性能問題和節點異常宕機。大部分的平臺上我們都可以通過netstat –s命令的‘IP stats’輸出發現包的碎片和重組的錯誤。大部分的平臺上我們可以通過ifconfig –a命令找到frame size的設置。關于交換機上的配置查詢,需要查看交換機提供商的文檔來確定。
4.操作系統層的關鍵優化項
4.1 兼容性檢查
在Oracle建設實施之前,根據操作系統平臺對即將采用的相關數據庫技術進行兼容性檢查。下面的link是官方的Matrix,分別針對Linux平臺和Unix平臺:
http://www.oracle.com/technetwork/database/clustering/tech-generic-linux-new-086754.html
http://www.oracle.com/technetwork/database/clustering/tech-generic-unix-new-166583.html
4.2 平臺版本及補丁
當我們選擇了具體的操作系統平臺以及具體的數據庫版本之后,接下需要做的事情就是要根據官方提供的文檔來檢查我們的系統補丁以及相關軟件包是否齊全準確:
https://support.oracle.com/epmos/faces/DocumentDisplay?_afrLoop=184026698780346&parent=DOCUMENT&sourceId=1526555.1&id=169706.1&_afrWindowMode=0&_adf.ctrl-state=bjsizj5t_240
https://support.oracle.com/epmos/faces/DocumentDisplay?_afrLoop=184190072886338&parent=DOCUMENT&sourceId=1526555.1&id=1393041.1&_afrWindowMode=0&_adf.ctrl-state=bjsizj5t_338
https://support.oracle.com/epmos/faces/DocumentDisplay?_afrLoop=184287678146090&parent=DOCUMENT&sourceId=1526555.1&id=282036.1&_afrWindowMode=0&_adf.ctrl-state=bjsizj5t_436
Oracle官方對所有數據庫集群及RDBMS等建議的最新補丁列表:
https://support.oracle.com/epmos/faces/DocumentDisplay?_afrLoop=202212137729856&parent=DOCUMENT&sourceId=1526083.1&id=756671.1&_afrWindowMode=0&_adf.ctrl-state=yi6z8ecqc_839#r11204
另外在AIX平臺上有一個不容忽視的地方,那就是必須保障Hacmp沒有安裝或者沒有任何殘留痕跡。
4.3 時間同步設置項
NTP是11gr2之前必須的選項,用來同步節點之間的時間。而到了11gr2之后,不僅僅可以采用NTP也可以采用CTSSD(Cluster Time Synchronization Daemon)代替NTP。如果NTP啟用的話,Oracle會采用NTP,CTSSD自動處于觀察模式。但是在NTP的啟用模式上,我們需要采用漸進式模式(需要利用啟動參數-x)。可以參照下面的配置:
1. /etc/sysconfig/ntpd
# Drop root to id 'ntp:ntp' by default.
OPTIONS="-x -u ntp:ntp -p /var/run/ntpd.pid"
# Set to 'yes' to sync hw clock after successful ntpdate
SYNC_HWCLOCK=no
# Additional options for ntpdate
NTPDATE_OPTIONS=""
4.4 ASLR (Address Space Layout Randomization)
ASLR是REL5 Linux以上版本中默認開啟的一個特性,是參與保護緩沖區溢出問題的一個計算機安全技術。是為了防止攻擊者在內存中能夠可靠地對跳轉到特定利用函數。ASLR包括隨機排列程序的關鍵數據區域的位置,包括可執行的部分、堆、棧及共享庫的位置。ASLR通過制造更多讓攻擊者預測目標地址的困難以阻礙一些類型的安裝攻擊。而在ORACLE的進程管理當中,多個進程共享相同地址的共享內存,開啟ASLR特性之后,Oracle就無法保障共享內存可用。從而導致ORA-00445錯誤發生。要在Linux上關閉這個特性需要添加或修改以下兩個參數到/etc/sysctl.conf文件:
kernel.randomize_va_space=0
kernel.exec-shield=0
4.5 HugePage
大多數操作系統采用了分段或分頁的方式進行管理。分段是粗粒度的管理方式,而分頁則是細粒度管理方式,分頁方式可以避免內存空間的浪費。相應地,也就存在內存的物理地址與虛擬地址的概念。通過前面這兩種方式,CPU必須把虛擬地址轉換程物理內存地址才能真正訪問內存。為了提高這個轉換效率,CPU會緩存最近的虛擬內存地址和物理內存地址的映射關系,并保存在一個由CPU維護的映射表中。為了盡量提高內存的訪問速度,需要在映射表中保存盡量多的映射關系。
Linux的內存管理采取的是分頁存取機制,為了保證物理內存能得到充分的利用,內核會按照LRU算法在適當的時候將物理內存中不經常使用的內存頁自動交換到虛擬內存中,而將經常使用的信息保留到物理內存。
通常情況下,Linux默認情況下每頁是4K,這就意味著如果物理內存很大,則映射表的條目將會非常多,會影響CPU的檢索效率。因為內存大小是固定的,為了減少映射表的條目,可采取的辦法只有增加頁的尺寸。因此Hugepage便因此而來。也就是打破傳統的小頁面的內存管理方式,使用大頁面2m,4m等。如此一來映射條目則明顯減少。如果系統有大量的物理內存(大于8G),則物理32位的操作系統還是64位的,都應該使用Hugepage。
那么如何控制Oracle數據庫對HugePage的利用呢?主要分為以下幾個步驟:
1.需要在/etc/security/limits.conf 中設置memlock值(單位KB),該值小于內存大小。
2. 如果你使用11G及以后的版本,AMM已經默認開啟,但是AMM與Hugepages是不兼容的,必須先關閉AMM。
3.編輯/etc/sysctl.conf 設置 vm.nr_hugepages參數的具體值。
4.停止實例并重啟OS系統,并通過以下命令檢查設置是否生效:
# grep HugePages /proc/meminfo
HugePages_Total: 1496
HugePages_Free: 485
HugePages_Rsvd: 446
HugePages_Surp: 0
5.通過以下參數控制數據庫對HugePage的使用方式(11gr2之后):
use_large_pages = {true/only/false/auto}
默認值是true,如果系統設置Hugepages的話,SGA會優先使用hugepages,有多少用多少。如果設置為false, SGA就不會使用hugepages。如果設置為only 如果hugepages大小不夠的話,數據庫實例是無法啟動的。設置為auto,這個選項會觸發oradism進程重新配置linux內核,以增加hugepages的數量。一般設置為true。
SQL> alter system set use_large_pages=true scope=spfile sid='*';
4.6 Transparent HugePage
透明大頁管理和前面所述的標準大頁管理都是操作系統為了減少頁表轉換消耗的資源而發布的新特性,雖然Oracle建議利用大頁機制來提高數據庫的性能,但是Oracle卻同時建議關閉透明大頁管理。這二者的區別在于大頁的分配機制,標準大頁管理是預分配的方式,而透明大頁管理則是動態分配的方式。
對于數據庫來講這種動態的分配方式在系統負載很高的情況下非常有可能導致數據庫出現嚴重的性能問題。這在Oracle官方文檔1557478.1當中有詳細的記載。
那么如何來關閉系統的透明大頁管理呢?只要修改如下參數即可:
# echo never > /sys/kernel/mm/transparent_hugepage/enabled
4.7 vm.min_free_kbytes
該參數是Linux內核當中用來控制保留最小空閑內存的數量,Oracle建議調大該值為512M。這樣的設置有利于相對加快內存的回收速度,從而降低內存吃緊的壓力。
4.8 AIX虛擬內存參數
這一項主要是針對AIX的內存管理。AIX內存管理和Linux的內存管理機制不一樣,它采用計算內存和非計算內存方式來管理內存。IBM對Oracle的建議值為以下方案:
minperm%=3
maxperm%=90
maxclient%=90
lru_file_repage=0
lru_poll_interval=10
strict_maxperm=0
strict_maxclient=1
page_steal_method=1
minperm和maxperm控制非計算內存中的文件頁的下限和上限;maxclient控制非計算內存中的客戶頁面;lru_file_repage表示分頁替換守護進程將根據其內部重新分頁表來確定選擇何種類型的分頁進行操作。strict_maxperm&strict_maxclient表示無論是否有空閑內存,都會嚴格限制文件頁以及客戶頁的最大占有比率不得超越限制。page_steal_method表示換頁時的策略,0為全部頁面,1為非計算持久頁面。以上參數放方案表示費計算持久頁面的上限為90%,下限為3%;客戶機頁面上限為90%;采用非嚴格持久頁面上限控制策略;嚴格客戶機頁面上限控制策略。lru_file_repage & page_steal_method配合使用表示LRUD在尋找空閑頁時,只尋找費計算內存當中的持久內存頁面。
vmm_klock_mode=2
這個參數是是否對內核頁進行加鎖的控制。0則表示不進行加鎖,那么內核頁有可能被錯誤換出從而導致Page Fault發生;1則表示部分內核頁面加鎖;2則表示對所有內核頁面進行加鎖。在Oracle RAC環境下或者EMC的存儲作為系統的Swap Device的時候,IBM強烈建議將該參數設置為2。
4.9 PowerVM環境下的參數調整
PowerVM環境下,由于其利用Hypervisor實現了很多虛擬化的功能,這些功能大多從靈活性及擴展型來考慮,但是如果我們運行的是Oracle Rac的話,那么還是有很多關鍵點需要注意。
1. cpu folding
虛擬處理器折疊功能,當系統負載比較低的時候,AIX系統自動休眠一些虛擬處理器,以減少Hypervisor的開銷,提升PowerVM平臺整體性能。但是在某些情況下,當數據庫的負載變化非常快的時候,CPU折疊或者打開的速度反而會影響數據庫甚至系統的性能,嚴重導致系統掛起。下面是IBM針對該BUG的一個補丁,主要針對AIX5.3 & 6.1。
https://www-01.ibm.com/support/docview.wss?uid=isg1fixinfo105201
4.10 Linux內核參數
以下是Oracle官方針對Linux平臺內核參數設置的一個通用方案:
fs.aio-max-nr = 1048576
fs.file-max = 6815744
kernel.shmall = 2097152
kernel.shmmax = 4294967295
kernel.shmmni = 4096
kernel.sem = 250 32000 100 128
net.ipv4.ip_local_port_range = 9000 65500
net.core.rmem_default = 4194304
net.core.rmem_max = 4194304
net.core.wmem_default = 4194304
net.core.wmem_max = 4194304
kernel.shmmax: 是核心參數中最重要的參數之一,用于定義單個共享內存段的最大值。設置應該足夠大,能在一個共享內存段下容納下整個的SGA ,設置的過低可能會導致需要創建多個共享內存段,這樣可能導致系統性能的下降。
至于導致系統下降的主要原因為在實例啟動以及ServerProcess創建的時候,多個小的共享內存段可能會導致當時輕微的系統性能的降低(在啟動的時候需要去創建多個虛擬地址段,在進程創建的時候要讓進程對多個段進行“識別”,會有一些影響),但是其他時候都不會有影響。
64位linux系統:可取的最大值為物理內存值-1byte,建議值為多于物理內存的一半,一般取值大于SGA_MAX_SIZE即可,可以取物理內存-1byte。例如,如果為12G物理內存,可取210241024*1024-1=12884901887,SGA肯定會包含在單個共享內存段中。
kernel.shmall: 該參數控制可以使用的共享內存的總頁數。Linux共享內存頁大小為4KB,共享內存段的大小都是共享內存頁大小的整數倍。一個共享內存段的最大大小是16G,那么需要共享內存頁數是16GB/4KB=16777216KB /4KB=4194304(頁),也就是64Bit系統下16GB物理內存,設置kernel.shmall = 4194304才符合要求(幾乎是原來設置2097152的兩倍)。這時可以將shmmax參數調整到16G了,同時可以修改SGA_MAX_SIZE和SGA_TARGET為12G(您想設置的SGA最大大小,當然也可以是2G~14G等,還要協調PGA參數及OS等其他內存使用,不能設置太滿,比如16G)。
kernel.shmmni: 該參數是共享內存段的最大數量。shmmni缺省值4096,一般肯定是夠用了。
fs.file-max: 該參數決定了系統中所允許的文件句柄最大數目,文件句柄設置代表linux系統中可以打開的文件的數量。
fs.aio-max-nr: 此參數限制并發未完成的請求,應該設置避免I/O子系統故障。
kernel.sem: 以kernel.sem = 250 32000 100 128為例:250是參數semmsl的值,表示一個信號量集合中能夠包含的信號量最大數目。32000是參數semmns的值,表示系統內可允許的信號量最大數目。100是參數semopm的值,表示單個semopm()調用在一個信號量集合上可以執行的操作數量。128是參數semmni的值,表示系統信號量集合總數。
net.ipv4.ip_local_port_range: 表示應用程序可使用的IPv4端口范圍。
net.core.rmem_default: 表示套接字接收緩沖區大小的缺省值。
net.core.rmem_max: 表示套接字接收緩沖區大小的最大值。
net.core.wmem_default: 表示套接字發送緩沖區大小的缺省值。
net.core.wmem_max: 表示套接字發送緩沖區大小的最大值。
5.配置集群層的關鍵點
5.1 diagwait
在集群進行驅逐節點時,節點發生重新啟動的場合下,操作系統需要轉儲CrashDump,這個參數就是集群需要等待操作系統轉儲的時間參數。對于版本 10gR2 和 11gR1,所有平臺上的最佳實踐都是將 CSS diagwait 參數設置為小于等于13。對于11gR2已經不要求對該參數進行設置。
5.2 ORA_CRS_HOME
對于這個變量,Oracle官方給出的建議是:不要設置 ORA_CRS_HOME 環境變量(在所有平臺上)。設置此變量將使各個 Oracle 組件出現問題,而且 CRS 程序完全不需要此變量,因為它們都有包裝腳本。
5.3 關于組播和多播
Oracle11gR2私網采用的是組播方式通訊,組播地址段為230.0.1.0 或 224.0.0.251網段,為了保障集群私網通訊的正常及穩定,一方面這個網段的網絡配置需要支持組播,另外一方面不要讓主機的任何其他網絡配置和這兩個網段沖突。曾經遇到過浪潮的X86服務器的帶外管理的某個地址也正好利用了這個網段,結果導致了Oracle Rac節點的異常重啟。這種問題一般會顯示為私網通訊報錯,但是正常狀況下只要帶外管理收集日志工具不啟動的話,那么是不會發現這個問題的,屬于偶發性問題。所以我們需要特別小心此類問題,不要等到發生時候再去花費大量實踐調查。
6.安裝集群時的關鍵點
6.1 cluvfy
如果安裝過10g以后的RAC環境,應該對這個工具并不陌生。在安裝Cluster和Database之前通常會執行runcluvfy.sh腳本來檢查當前系統是否滿足安裝條件。runcluvfy.sh將cluvfy工具的功能在shell中實現,使得用戶在數據庫和CLUSTER安裝之前就可以利用這個工具的功能。這個工具的主要作用就是驗證系統是否滿足安裝的條件,尤其是檢查網絡和域名解析,如果網絡和域名解析在安裝之前沒有正常的配置,通常直接導致安裝的失敗。主要用法如下所列兩個功能:
# runcluvfy.sh stage -list
# runcluvfy.sh comp -list
6.2 升級順序問題
安裝完集群軟件也好,RDBMS也好,打補丁是必然要做的事情。但是究竟是等安裝完所有的組件之后再統一打補丁呢還是說將每一個組件都按照安裝&補丁升級的順序依次做完呢?Oracle給的建議是:在執行 11gR2 之前的安裝時,建議在執行任何 RDBMS 或 ASM 主目錄安裝前應用補丁程序將 Clusterware 主目錄升級到所需的級別。
6.3 root.sh & rootupgrade.sh
安裝或者升級期間,最后的步驟就是要執行以上的腳本。當然按照安裝文檔的要求必須是用超級用戶root來執行。但是可能有些人認為只要利用root的權限去執行就可以了,很想當然的用了su root -c或者是sudo等去執行,結果導致執行失敗,日志報錯crsd.bin crashes。因為腳本的執行不僅僅是要用超級用戶root的權限,還要利用root用戶的環境配置等。
6.4 /etc/init.cssd
11.2 之前再AIX系統上,OPROCD 默認不在 AIX 全局運行隊列運行 ,這可能會導致 OPROCD 錯誤地重啟節點。(Bug 13623902)。此問題的更正操作是修改 /etc/init.cssd 文件,加入如下參數:
RT_GRQ=ON
export RT_GRQ
但是AIX6.1 TL4以上的版本就自帶了對該問題的修正程序。所以當我們采用低版本的AIX操作系統時,需要特別注意這個配置文 件。
7.數據庫層的關鍵優化項
7.1 pre_page_sga & lock_sga
這兩個參數都是對數據庫SGA的保護參數。lock_sga是控制SGA不被換出到交換空間上,會保障數據庫內存頁一致留在物理內存上,從而提高性能。而pre_page_sga是保障數據庫實例啟動時就把所有SGA讀到物理內存上,雖然啟動會慢,但是后續性能會好。
但是pre_page_sga同時還有一個作用。pre_page_sga 為true時, 每個進程創建的時候都會去touch一遍sga里的page, 當sga越大的時候,這個touch所消耗的時間就越長,特別是在斷開式連接,短連接的Application上, 將會消耗很多資源。當客戶端連接感覺到慢的時候,這個參數就一定要設置成false了。Oracle的建議也是false。
SQL> alter system set pre_page_sga=false scope=spfile sid='';
SQL> alter system set lock_sag=true scope=spfile sid='';
7.2 關于重做日志
首先、接觸過數據庫的人相信對這個概念都不陌生。數據庫在做SQL更新的時候,首先要將事務執行過程記入重做日志當中,然后才會把日志刷入磁盤,將數據更新持久化。一條數據提交之后成功的標準時日志落到磁盤,而不是真正的數據落盤。因此日志的配置(大小、數量)直接決定著數據庫讀寫的性能,如果日志大小非常大,那么會造成歸檔切換時間非常長,一旦這時候發生了不可恢復的DB災難,那么通過備份恢復的數據流失量或者說RPO就會較大。日志大小非常小的話,勢必會造成日志頻繁切換,AWR里面有大量的日志切換事件,這樣對數據庫的性能會有較大影響。因此根據性能測試的AWR報告中日志切換的等待事件、和切換頻度來決定其數據量和大小是否需要調整。一般的OLTP建議(10組、500M)。
接著、我們還需要考慮與其相關的參數設置。
1. _use_adaptive_log_file_sync
它直接決定了日志落盤的方式,對于日志緩沖區的數據落盤的方式,11g增加一種新的方式就是polling的方式,傳統方式是post/wait方式。oracle底層自動判斷何時用何種方法來完成lgwr進程的寫任務。對于post/wait方式來講,客戶端做了commit之后,需要等待事件完成。oracle一旦完成會通知用戶進程,用戶進程立刻感知。但是這一通知post,會耗費大量CPU資源。polling是oracle前臺進程啟動檢查任務,自動檢查后臺lgwr寫入情況,耗費CPU資源比較少,但是用戶進程并不一定能立刻感知。
所以兩種方法各有千秋。但是關鍵是后臺實現兩種方法切換的時候要耗費系統性能,尤其在繁忙的時候頻繁切換的話反而會導致數據庫性能下降。awr出現大量log file sync,Bug 13707904。
SQL> alter system set "_use_adaptive_log_file_sync"=false scope=spfile sid='*';
2. archive_lag_target 它決定了我們是否開啟日志強制切換功能,為了減少故障時數據損失,可以設置archive_lag_target參數,強制進行日志切換。這個參數的缺省值是0,即為不啟用該參數。建議設置值為1800。 SQL> alter system set archive_lag_target=1800 scope=spfile sid='*';
7.3 AMM
首先、ORACLE通用的兩種內存管理方式AMM&ASMM,從Oracle 11g開始,ORACLE默認使用AMM(自動內存管理),即讓數據庫完全管理SGA、PGA的大小,而對于管理員只需要設置一個總的大小(memory_target),數據庫會動態的調整SGA、PGA的大小以及其中包含的各個組件大小,如Database buffer cache、Shared pool等。這個特性設計的初衷是好的,它希望避免不正確的SGA和PGA設置導致的內存使用不平衡的性能問題。
但是在實際應用過程中,這個特性是不是一定非常出色呢?AMM中在數據庫啟動是會有一個固定比例來分配SGA/PGA 大小:
sga_target =memory_target 60%
pga_aggregate_target=memory_target *40%。
但是在并發較高,數據庫非常繁忙的場合下,自動內存調整的速度很可能趕不上大量會話對內存的請求的速度。另外當PGA隨著會話不斷增加而需求量猛增的情況下,它會首先搶占SGA,導致數據庫性能故障。在高并發的數據庫場景中并不建議使用AMM。采用10g更為成熟的自動共享內存管理(ASMM)和自動PGA管理。手動調整內存參數,具體可以參照以下:
1. 關閉內存自動管理
SQL> alter system set memory_target=0 scope=spfile sid='';
SQL> alter system set memory_max_target=0 scope=spfile sid='*';
2. 設置SGA為固定值,可以根據性能測試中的AWR報告中的建議
SQL> alter system set sga_max_size=XG scope=spfile sid='';
SQL> alter system set sga_target=XG scope=spfile sid='';
3. 設置PGA等參數
SQL> alter system set pga_aggregate_target=XG scope=spfile sid='';
SQL> alter system set large_pool_size=256M scope=spfile sid='';
pga_aggregate_target=XG
large_pool_size=256M
另外很重要的一個參數,“_shared_pool_reserved_pct”,如果這個參數設置小了,很可能導致ORA04031,所以需要一個合理的設置。
SQL> alter system set“_shared_pool_reserved_pct”=10 scope=spfile sid='*';
7.4 SQL解析
1. 綁定變量窺測
在Oracle中每條SQL語在執行之前都需要經過解析,這里面又分為軟解析和硬解析。在Oracle中存在兩種類型的SQL語句,一類為 DDL語句(數據定義語言),他們是從來不會共享使用的,也就是每次執行都需要進行硬解析。還有一類就是DML語句(數據操縱語言),他們會根據情況選擇要么進行硬解析,要么進行軟解析。一般我們希望我們的AWR報告中硬解析偏少,而軟解析偏多。因為硬解析的代價會非常高。為了減少帶綁定變量的sql的解析時間,oracle 9i引入的綁定變量窺測的功能。也就是在同一個SQL的變量被賦于不同值時采用同一個游標,這樣雖然節省了sql的解析時間。大家有沒有通過功能的打開或者關閉實際觀察過AWR中的軟硬解析數目的實際狀況呢?其實對于綁定變量窺測這個特性以及后來的自適應游標等特性,都是oracle為了找到最優執行計劃而啟用的一些新特性,但是在實際應用過程中,對于不同量級不同特性的業務場景也曾經因此出現了很多bug( Bug 20370037,Bug 13456573,Bug 20082921)等。
根據自己的業務系統特點,做大量的性能測試和業務測試,根據參數的關閉打開對比awr報告當中顯示出的軟硬解析比率以及執行計劃數據決定是否打開或者關系相應功能特性。如下參數:
"_optim_peek_user_binds"
"_optimizer_adaptive_cursor_sharing"
"_optimizer_extended_cursor_sharing"
"_optimizer_extended_cursor_sharing_rel"
"_optimizer_use_feedback"
2. open_cursors & session_cached_cursors
與之相關的幾個參數:open_cursors、session_cached_cursors 這兩個參數決定著應用會話可以控制打開以及緩存的游標數量,如果數量不足,就會引起SQL解析的性能問題。這兩個參數要根據v$resource_limit視圖中的值的情況進行調整,避免資源設置不合理導致的性能問題。
SQL> alter system set open_cusors=N scope=spfile sid='';
SQL> alter system set session_cached_cursors=M scope=spfile sid='';
3. _b_tree_bitmap_plans
與執行解析執行計劃相關的幾個參數,_b_tree_bitmap_plans、有時將B-Tree索引進行BITMAP轉換來進行SQL執行,往往會生成極其惡劣的執行計劃,導致CPU100%。Select Fails With ORA-600 [20022] (文檔 ID 1202646.1) 建議可以關掉。
SQL> alter system set "_b_tree_bitmap_plans"=false scope=spfile sid='*';
7.5 process & sessions
process 限制了能夠連接到SGA的操作系統進程數,這個總數必須足夠大,從而能夠適用于后臺進程與所有的專用服務器進程,此外共享服務器進程與調度進程的數目也被計算在內。session 是通信雙方從開始通信到通信結束期間的一個上下文(context)。這個上下文是一段位于服務器端的內存:記錄了本次連接的客戶端機器、通過哪個應用程序、哪個用戶在登錄等信息。
Oracle的連接數sessions與其參數文件中的進程數process相關,它們的關系如下: sessions=(1.1process+5)
這兩個參數的設置是需要根據應用的具體并發需求來決定具體的設置方案。
SQL> alter system set process=N scope=spfile sid='';
SQL> alter system set sessions=1.1N+5 scope=spfile sid='';
7.6 DRM
數據庫節點之間的競爭有很多,包括鎖(各種粒度鎖)的競爭以及數據的傳輸等。完全避免競爭那就失去了RAC的意義了,RAC本身就是希望能在兩個節點并行執行任務。如果特別極致的并行一定引起嚴重的性能問題,如果完全禁止,既無法做到又失去了集群本來的意義。所以我們只能在一定程度上去平衡:
首先、關于DRM,oracle的DRM特性從理論上來看,它是為了避免節點間的數據量傳輸,避免節點間的鎖等待事件頻繁發生。DRM的極致是做到請求節點和Master節點統一化。但是實踐中,這個特性引起了很多的BUG、反而導致了節點間的競爭出現了性能故障。Bug 6018125 - Instance crash during dynamic remastering or instance reconfiguration (Doc ID 6018125.8)。所以建議關閉。
SQL> alter system set "_gc_policy_time"=0 scope=spfile sid='*';
SQL> alter system set "_gc_undo_affinity"=false scope=spfile sid='*';
7.7 parallel_force_local
關于參數“parallel_force_local”,ORACLE RAC為了實現多節點并行處理是花費了很大代價的,假設一個集群當中有三個節點,對于某一個數據塊兒讀寫,有一個Master、有一個請求者、有一個擁有者,請求者向Master請求數據塊兒的最新版本,Master把請求轉發給擁有者,擁有者按照請求信息把數據塊兒傳送給申請者,然后加鎖進行讀寫。這一過程是需要有大量的數據傳輸和競爭存在的,一旦這個事情成為多數,那么勢必造成節點間的通訊負載過大,造成大量的鎖等待時間,嚴重影響數據庫整體性能。尤其是在做跨數據中心高可用的場合下。因此我們只要做到業務級別的并發處理,而不要追求一個SQL級別的絕對并發。物極必反的道理就在于此。因此把參數打開,使得進程級別并發實現本地化處理,不要跨節點處理。在官方文檔 ID 1536272.1當中,必須優化的參數就包括這個。
SQL> alter system set parallel_force_local=true scope=spfile sid='*';
7.8 關于自動任務
Oracle 11g 數據庫有三個預定義自動維護任務:
1. Automatic Optimizer Statistics Collection(自動優化器統計信息收集): 收集數據庫中所有無統計信息或僅有過時統計信息的 Schema 對象的 Optimizer(優化器)統計信息。QL query optimizer(SQL 查詢優化器)使用此任務收集的統計信息提高 SQL 執行的性能。
2. Automatic Segment Advisor(自動段指導): 識別有可用回收空間的段,并提出如何消除這些段中的碎片的建議。也可以手動運行 Segment Advisor 獲取更多最新建議。
3. Automatic SQL Tuning Advisor(自動 SQL 優化指導):檢查高負載 SQL 語句的性能,并提出如何優化這些語句的建議。您可以配置此指導,自動應用建議的SQL profile。
關于統計信息收集,數據庫是有其自己的默認啟動時間,11g是在22:00-2:00之間,假設這個時間跟我們的跑批時間有沖突的話,我們可以修改器具體執行時間。但是這個任務必須保留。關于其他的兩個優化指導,其實要看我們實際工作中用到的幾率是否很高,是否有價值留著給我們提供一些優化的理論指導。如果感覺意義不大,可以不用。
7.9 安全方面的配置優化
首先、是數據庫要不要保留審計?如何保留?
假設不打開審計,那么將來出來安全問題,我們無法尋找線索;假設打開,那么很可能因為使得審計日志占用大量的存儲空間,甚至影響數據庫IO性能。一般情況下還是需要對一些基本登錄行為的審計,但是我們可以把日志位置修改制定到操作系統層面減少數據庫層因此的性能壓力,而且應該定期轉儲,減少碎文件太多而把文件系統i節點用光的極端情況。可以通過對參數"audit_trail"以及adump參數的調整來實現此項優化。
接著、alert日志和trace文件的控制參數。
max_dump_file_size,它決定了這些文件的大小限制,默認情況下是unlimited,如果生成了很大的文件,就會達到OS對文件上限的要求,導致寫入失敗。
SQL> alter system set max_dump_file_size='100m' scope=spfile sid='*';
7.10 parallel_min_servers
這個參數決定了實例可以并行執行的進程的最大數目。設置太小查詢進程沒有并行執行能力。如果設置太大,那么可能會導致內存資源緊張,從而影響系統整體性能。確保監控活動并行服務器進程的數量并計算要應用于 parallel_min_servers 的平均值。可通過以下操作完成:
SQL> select * from v$pq_syssstat;
查看列值 "Servers Highwater";
根據硬件情況優化 parallel_max_servers的值。最開始可以使用 (2 * ( 2 個線程 ) (CPU_COUNT)) = 4 x CPU 計算,然后使用測試數據對更高的值重復測試。一般OLTP系統需限制其不超過128(ORACLE的默認算法有BUG,在cpu核數超過128,默認并行參數設置過高時,容易被觸發,會導數oracle無法啟動。另外,如果這個參數太高,并行的進程開的太大了,會導數數據庫無法承受并發壓力)。
SQL> alter system set parallel_max_servers=128 scope=spfile sid='';
7.11 fast_start_mttr_target & fast_start_parallel_rollback
fast_start_mttr_target={0-3600} 一旦設置具體值,那么崩潰恢復將在此要求的時間范圍內完成。fast_start_parallel_rollback={high/low/false},high啟動4倍于CPU數目的并行恢復進程,low啟動2倍于CPU數目的并行恢復進程,false關閉并行恢復進程。這兩個參數都是用來加速在故障場合下的奔潰恢復,其根本的機制就是要通過主動觸發checkpoint來縮短最近依次checkpoint和聯機重做日志之間的距離。但是這個無疑會帶來一定的性能風險。所以這兩個值的設置需要根據具體業務情況來設置,同時要進行壓力測試,不要因為激進的策略帶來性能問題。
與此相關還有一個參數log_checkpoints_to_alert,默認是關閉狀態。打開這個參數會在trace文件當中記錄詳細的檢查點發生信息,對于數據庫診斷來講是一個必不可少的功能。因此建議打開。
SQL> alter system set fast_start_mttr_target=120 scope=spfile sid='';
SQL> alter system set fast_start_parallel_rollback=low scope=spfile sid='';
SQL> alter system set log_checkpoints_to_alert=true scope=spfile sid='*';
7.12 listener.ora
對于11.2之前的 listener, 首先得保證IPC項存在,且此項列在所有RAC listener的地址列表的第一個。否則,可能會對 VIP 在公網接口出現故障時進行故障轉移所用的時長產生不利影響。
LISTENER_n1 =
(DEION_LIST =
(DEION =
(ADDRESS_LIST = (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC)))
(ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = n1vip)(PORT = 1521)(IP = FIRST)))
(ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = 10.8.21.121)(PORT = 1521)(IP = FIRST)))
)
)
假設把TCP列到第一項,那么監聽需要等待TCP timeout,而TCP timeout是受操作系統相關參數控制,并且timeout時間較長,那么就有可能引起故障轉移并不能非常及時的問題。
7.13 sqlnet.ora
數據庫連接的客戶端異常斷開后,其占有的相應并沒有被釋放,如從v$session視圖中依舊可以看到對應的session處于inactive,且對應的服務器進程也沒有釋放,導致資源長時間地被占用,對于這種情形開該如何處理呢?sqlnet.expire_time對于這個問題我們提供了解決方案,專門用于清理那些異常斷開的情形,如網絡異常中斷,客戶端異常掉電,異常重啟等。可以在sqlnet.ora文件當中設置參數sqlnet.expire_time=5。
7.14 回收站
從ORACLE 10g開始,引入了一個叫回收站(Recycle Bin)的概念。它的全稱叫Tablespace Recycle Bin。回收站實際是一個邏輯容器。它以表空間中現有已經分配的空間為基礎,而不是從表空間上物理劃出一個固定區域用作回收站。這意味著回收站和表空間中的對象共用存儲區域、系統沒有給回收站預留空間。因此,當表被DROP后,如果可用空間充足,并且沒有對回收站進行清理,那么被DROP掉的對象會一直存在回收站中,但是如果可用空間緊張的情況下,數據庫會根據先進先出的順序覆蓋Recycle Bin中的對象。回收站這個特性主要的好處就是在誤刪除一個表時有一個恢復機制,不必通過數據庫還原來實現,避免大量的人工誤操作。
但是對于業務場景存在大量的drop對象但是沒有purge操作的場合下,那么回收站的開啟勢必會帶來數據庫系統表空間大量占用以及數據庫性能降低的風險,尤其是在金融業務批量的業務環境。所以就實際的生產環境而言,這個功能的用途并非像理論上想象的那么有意義。基于風險的考慮,還是建議把該功能關閉掉。
SQL> show parameter recyclebin
SQL> salter system set recyclebin=off cope=spfile sid='*';
SQL> spurge recyclebin
SQL> spurge dba_recyclebin
7.15 結果緩存
結果緩存是11g之后增加的特性。分為server和client兩種類型,server是指在SGA的Share Pool當中保留一塊兒內存空間用來存儲SQL或者PLSQL的查詢結果,供其他進程來共享使用。Client是指在OCI連接進程當中的內存當中保存SQL查詢結果,供進程內所有session來使用。本意都是要提高查詢效率。但是在實際使用的過程當中,它曾導致了很多問題,例如RC Latch、reliable message等資源等待問題(ID 1951729.1 - Bug 19557279,12c已經修復了這個問題)。
因此,為了避免系統遇到以上情況下發生更嚴重的性能問題,建議將結果緩存關閉掉。
SQL> alter system set "_optimizer_ads_use_result_cache"=false scope=spfile sid='*';
SQL> alter system set "_result_cache_max_size"=900 scope=spfile sid='*';
7.16 undo
在事務提交或回滾之后,因為flashback或一致讀的需求,還需要將對應的undo數據保存在undo表空間中一段時間,這個時間就是由undo_retention來設置的。根據undo_retention可以繼續將undo的inactive狀態劃分為EXPIRED,UNEXPIRED兩類,undo中超過undo_retention時間之外的inactive undo回滾區稱為expired, 還處于unod_retention時間之內的inactive undo回滾區稱為unexpired。undo_retention不是說必須達到這個時間后才能被覆蓋,而只是一個期望值,比如undo表空間文件設置為非自動擴展,當一個大事務需要將undo中未使用的區域及過期的undo區域都使用完了,而undo空間不能自動擴展,這時保證事務順利運行優先級比較高,undo中沒有過期的回滾區也會被覆蓋使用(從其中使用時間越早的開始),也就是說retention設置的時間段內的undo非過期數據是沒有保證的。
10g之后引入一個新的參數“_undo_autotune”,這個參數表示Oracle對undo自動優化,就是在undo表空間非自動增長的情況下,Oracle會根據undo表空間的大小來調整undo RETENTION的大小,自動調整retention就是最大限度的利用當前undo表空間的可用空間,盡可能的保留最多的undo數據,以最大化的減少類似ORA-01555 等錯誤發生。
_undo_autotune此參數默認開啟,有利于時間長的查詢,但是對于典型的OLTP系統來說不太適用。尤其在系統繁忙的時候,經常會出現undo不夠用的情況。回收undo,簡單resize會報錯。因此建議關閉次參數并設置合理的retetion時間。
SQL> alter system set "_undo_autotune"=false scope=spfile sid='*';
SQL> alter system set undo_retention=900 scope=spfile sid='*';
(1.OLTP系統:15分鐘 / 2.混合:1小時 / 3.DSS系統:3小時)
7.17 執行計劃中的排序
正常情況下,我們認為SQL查詢計劃如果利用index排序索引的話,從性能上看會是比較優的選擇。但是往往在實際生產過程中,很多中情況如果走排序的話不一定會獲得最優的查詢計劃,有的時候反而會更糟糕。因此Oracle用一個參數“_sort_elimination_cost_ratio”來控制是否一定走排序尋找最優執行計劃。
當“不排序的成本/排序的成本”這個比值小于“_sort_elimination_cost_ratio”參數值時,Oracle會選擇不走排序去獲取執行計劃。“_sort_elimination_cost_ratio”的默認值為0,也就是說Oracle默認任何情況下都選擇排序獲取執行計劃,即使排序的成本是無窮大。
實踐證明默認的選擇往往是不對的,會將查詢引入到錯誤的執行計劃。因此建議將參數值設置為5。 SQL> alter system set "_sort_elimination_cost_ratio"=5 scope=spfile sid='*';
7.18 控制文件
關于控制文件的記錄保存時間控制參數control_file_record_keep_time,默認值為7,也就是說控制文件只保留7天記錄,超過7天的備份記錄會被認為是無效的。這個值的設置需要跟兩個地方關聯起來:
1. 集中備份軟件設置的備份策略中關于過期時間的定義。
2. Rman的參數retention policy。
例如我們的備份策略對某系統備份集過期的時間定義為30天,那么我們就分別對控制文件和RMAN兩個地方的參數做如下設置(RMAN保留時間設置太長會導致list backup命令執行多幾分鐘時間):
SQL> alter system set control_file_record_keep_time=30 scope=spfile sid='*';
RMAN> configure retention policy to recovery window of 30 days;
7.19 job_queue_processes
如果同一時間內運行的Job數很多,過小的參數值導致job不得不進行等待。而過大的參數值則消耗更多的系統資源。應該設置一個比較合理的數值,以避免此類事情發生。
Oracle默認值為1000,這個值對于一般的OLTP系統來講比較大,所以需要進行合理的修改。
7.20 rman
1. 為了提高rman備份的效率,假設磁帶備份設備支持異步I/O,建議將這個參數設置為true,以啟動該設置。創建一個large pool,使得RMAN中獲得良好的性能。 SQL> alter system set backup_tape_io_slaves=true scope=spfile sid='*';
2. 關于ADG備庫的RMAN參數設置, RMAN> configure archivelog deletion policy to applied on standby; 這個參數設置是保護沒有被應用的日志不被刪除,在11g的高版本實際上已經不需要再設置了,但是低版本的就需要注意了。
7.21 其他
1.表空間的數據文件是否采用了自動擴展的方式?
2.表空間的數據文件是否都用了ASM的方式?
3.ASM的冗余方式是否一致?
4.應用用戶的默認密碼策略是不是已經取消了180天的限制等等。
5.數據庫的監控指標是否覆蓋了(集群、服務、監聽、ASM、表空間、性能等所有應該涵蓋的方面)?
6.OS層面的監控是否已經啟用?尤其是私網之間的通訊、CPU、內存的監控等?是Nmon還是osw,他們的日志是定期循環還是持續不斷增長等等?
7.數據庫巡檢的體系是否完善?日巡檢月度巡檢的內容是否經過精心設計?是否已經實現了自動化等等?強烈建議日巡檢工作實現腳本自動化,任務定時執行,日志統一整合到共享文件系統上,有條件的可以進行整合入庫,按照自己的巡檢機制和體系實現按需調入調出。
8.總結及展望
本文是基于數據建設的規劃、實施以及配置優化等階段對大量文獻的總結提煉以及項目的實踐出發,對數據庫建設過程中各個層面應該注意的事項進行了一個總結。希望對正在從事此項工作的同業以及將來要從事這類項目的同業給予參考,也希望更多人在此基礎之上能夠將其完善和優化分享給大家。
【主要參考文獻】
[1]. RAC 和 Oracle Clusterware 最佳實踐和初學者指南(平臺無關部分) (文檔 ID 1526083.1)
[2]. RAC and Oracle Clusterware Best Practices and Starter Kit (Linux) (文檔 ID 811306.1)
[3]. RAC and Oracle Clusterware Best Practices and Starter Kit (AIX) (文檔 ID 811293.1)
[4]. Top 11 Things to do NOW to Stabilize your RAC Cluster Environment (文檔 ID 1344678.1)
[5]. IBM System p Advanced POWER Virtualization Best Practices
[6]. 最佳實踐:主動避免數據庫和查詢相關的性能問題 (文檔 ID 1549184.1)
[7]. 11gR2 Clusterware and Grid Home - What You Need to Know (文檔 ID 1053147.1)
[8]. Oracle Databases on VMware Best Practices Guide
[9]. Deploying Oracle Database 11g R2 on Red Hat Enterprise Linux 6 Best Practices
[10].10g 和 11gR1 ASM 技術最佳實踐 (文檔 ID 1602417.1)
[11]. Oracle? Database High Availability Best Practices 11g Release 1 (11.1)
[12]. Oracle? Database High Availability Best Practices 11g Release 2 (11.2)
[13]. Oracle on AIX – Configuration & Tuning. R Ballough (ppt)
[14]. Oracle Database 11g R2 Oracle Database 11g R2 RAC on IBM AIX Tips and Considerations
[15]. Grid Infrastructure Redundant Interconnect and ora.cluster_interconnect.haip
此文章是轉載于搜狐的文章
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





